
1.BigBird:疎なAttentionでより長い連続データに対応可能なTransformer(2/2)まとめ
・ETCを更に拡張し元データに存在する構造に関する前提知識を不要とするBigBirdを開発
・GPUやTPUを活用するためにスパースAttentionメカニズム用の効率的な実装も実現した
・BigBirdはパフォーマンスを犠牲にせずにメモリ消費を明らかに削減する事が実証された
2.BigBirdとは?
以下、ai.googleblog.comより「Constructing Transformers For Longer Sequences with Sparse Attention Methods」の意訳です。元記事の投稿は2021年3月25日、Avinava Dubeyさんによる投稿です。
アイキャッチ画像は京都で撮影された巨鳥でクレジットはPhoto by vaea Garrido on Unsplash
BigBird
ETCの研究を拡張し、BigBirdを提案します。BigBirdは、Transformersで使用されるAttentionメカニズムの一般的な代替であるスパースAttentionメカニズムを採用しており、トークンの数も線形に抑えられています。
ETCとは対照的に、BigBirdは、元データに存在する構造に関する前提知識を必要としません。BigBirdモデルのまばらなAttentionは、次の3つの主要部分で構成されます。
・入力シーケンスの全ての部分に参加するグローバルトークンのセット
・ローカル隣接トークンのセットに参加するすべてのトークン
・ランダムトークンのセットに参加するすべてのトークン
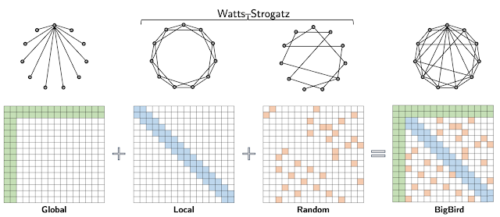
BigBirdのスパースAttentionは、Watts-Strogatzグラフにいくつかのグローバルトークンを追加したものと見なすことができます。
BigBirdの論文では、二次Attentionを近似するのにスパースAttentionで十分である理由を説明し、ETCが成功した理由を部分的に説明しています。
重要な観察は、計算する類似性スコアの数と、異なるノード間の情報の流れとの間に固有の張力(つまり、1つのトークンが相互に影響を与える能力)があることです。
グローバルトークンは情報フローの導管として機能し、グローバルトークンを使用したスパースAttentionメカニズムが完全Attentionモデルと同じくらい強力である可能性があることを証明します。
特に、BigBirdは、元のTransformerと同じくらい表現力があり、計算上普遍的であり(Yun et al. and Perez et al)、連続関数の普遍近似器であることを示します。さらに、私たちの証明は、ランダムグラフの使用が情報の流れをさらに容易にするのに役立ち、ランダムAttentionコンポーネントの使用を動機付けることができることを示唆しています。
この設計は、構造化タスクと非構造化タスクの両方で、はるかに長いシーケンス長に拡張できます。トレーニング時間をシーケンスの長さとトレードオフすることにより、勾配チェックポインティングを使用することで、更に規模の拡大を行うことができます。これにより、効率的なスパースTransformerを拡張して、エンコーダーとデコーダーを必要とする生成タスクを含めることができます。たとえば、長いドキュメントの要約など、新しい最先端技術を実現できます。
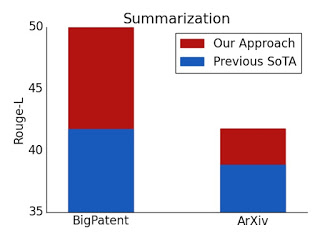
長いドキュメントの要約のROUGEスコア
BigPatentデータセットとArXivデータセットの両方で、新しい最先端の結果を実現します。
更に、BigBirdが一般的な代替品であるという事実により、特定領域に関して既存知識がなくても新しい領域に拡張することもできます。特に長いコンテキストが有益であるTransformerベースのモデルの新しい応用として、ゲノム配列(DNA)の特徴表現の抽出を紹介します。
BigBirdは、より長いマスク言語モデルの事前トレーニングにより、プロモーター領域の予測やクロマチンプロファイルの予測などの下流タスクで最先端のパフォーマンスを実現します。
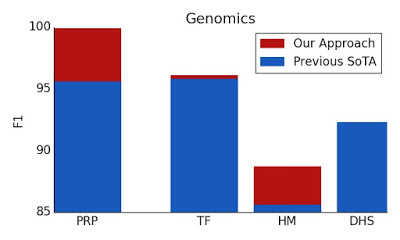
プロモーター領域予測(PRP:Promoter Region Prediction)、転写因子(TF:Transcription Factors)含むクロマチンプロファイル予測、ヒストンマーク(HM:Histone-Mark)、DNase I過敏性(DHS:Dnase I HyperSensitive)検出などの複数のゲノミクスタスクでは、ベースラインを上回っています。更に、私たちの結果は、Transformerモデルが現在十分に検討されていない複数のゲノミクスタスクに適用できることを示しています。
主な実装のアイデア
スパースAttentionの大規模な採用に対する主な障害の1つは、スパース操作が最新のハードウェアでは非常に非効率的であるという事実です。ETCとBigBirdの両方の背後にある、私たちの重要な革新の1つは、スパースAttentionメカニズムの効率的な実装を行うことです。
GPUやTPUなどの最新のハードウェアアクセラレータは、連続するバイトのブロックを一度にロードする合体メモリ操作の使用に優れているため、スライディングウィンドウ(ローカルAttention用)またはランダム要素クエリ(ランダムAttention)によって引き起こされる小さな散発的なルックアップを行うことは効率的ではありません。代わりに、スパースなローカルおよびランダムなAttentionを密なテンソル演算に変換して、最新の「単一命令、複数データ(SIMD:Single Instruction, Multiple Data)」ハードウェアを最大限に活用します。
これを行うには、最初にAttentionメカニズムを「ブロック化」して、ブロックで動作するように設計されたGPU/TPUをより有効に活用します。次に、以下のアニメーションに示すように、形状変更、ロール、収集などの一連の単純な行列演算を使用して、スパースなAttentionメカニズムの計算を密なテンソル積に変換します。
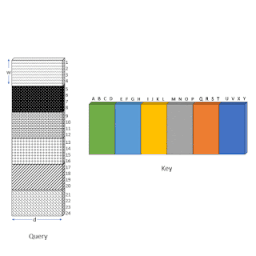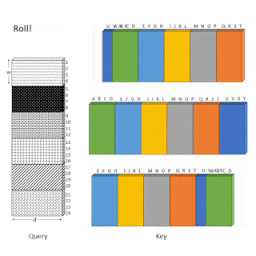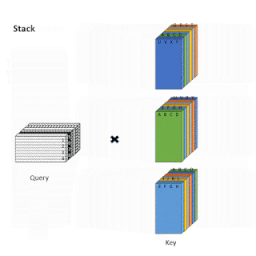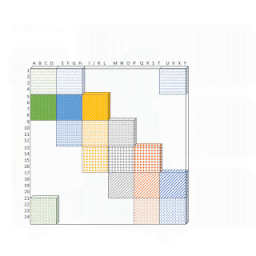
ロールとリシェイプを使用して、小さな散発的なルックアップなしで、スパースウィンドウのAttentionを効率的に計算する概要図
最近、論文「Long Range Arena:A Benchmark for Efficient Transformers」は、より長い文脈情報を必要とする6つのタスクのベンチマークを提供し、既存のすべてのlong range transformersをベンチマークするための実験を実行しました。結果は、BigBirdモデルが、他のモデルとは異なり、パフォーマンスを犠牲にすることなくメモリ消費を明らかに削減することを示しています。
結論
注意深く設計されたスパースattention は、元のフルattention モデルと同じくらい表現力と柔軟性があることを示しました。理論的な保証に加えて、非常に効率的な実装を提供し、はるかに長い入力に拡張できるようにしました。その結果、質問回答、ドキュメントの要約、ゲノムフラグメントの分類に関して最先端の結果が得られました。
私たちのスパースattention の一般的な性質を考えると、このアプローチは、プログラム合成や長い形式のオープンドメインの質問応答などの他の多くのタスクに適用できるはずです。ETCとBigBirdの両方のコードをgithubでオープンソース化しました。どちらも、GPUとTPUの両方で長いシーケンスに対して効率的に実行されます。
謝辞
この研究は、 EMNLPとNeurIPSの論文の共同執筆者であるAmr Ahmed, Joshua Ainslie, Chris Alberti, Vaclav Cvicek, Avinava Dubey, Zachary Fisher, Guru Guruganesh, Santiago Ontañón, Philip Pham, Anirudh Ravula, Sumit Sanghai, Qifan Wang, Li Yang, Manzil Zaheerとのコラボレーションの結果です。
3.Big Bird:疎なAttentionでより長い連続データに対応可能なTransformer(2/2)関連リンク
1)ai.googleblog.com
Constructing Transformers For Longer Sequences with Sparse Attention Methods
2)arxiv.org
ETC: Encoding Long and Structured Inputs in Transformers
Big Bird: Transformers for Longer Sequences
Long Range Arena: A Benchmark for Efficient Transformers
3)github.com
google-research/etcmodel/
google-research/bigbird

