
1.ETLの未来がELTではなくEL(T)である理由まとめ
・ETLは柔軟性、視認性、及びデータ追加時にコストがかかる事が問題点である
・ELTは、データを取り込んだ後に変換するのでデータ要件が変更されても追加コストが不要
・最終的にExtract-Load部分から変換タスクを完全に切り離す事で自由度が更に上がるはず
2.ETLとELTの違い
以下、www.kdnuggets.comより「Why the Future of ETL Is Not ELT, But EL(T)」の意訳です。元記事の投稿は2020年12月、John Lafleurさんによる投稿です。
ETLとは、「Extract(抽出)/Transform(変換)/Load(取り込み)」の略で、様々な場所からデータを集める処理、または集める際に使うツール群の事です。かなりインフラよりの話ですが、データサイエンティストになるために2021年に学ぶべきスキルの1つとしてAirflowがあげられていた事からも米国ではデータパイプライン構築系の話もざっと押さえておく必要があると見なされているのか、元記事は年末にかなりアクセスを集めていました。
私もデータウェアハウス/データレイクの位置づけや、データサイエンティストと機械学習エンジニアがやる事は違っていてもインフラ基盤が共通化されると言う視点は興味深く読みました。ただ、自分の過去の経験から思う事は、データとは均等に大きくなるのではなく何か一つに偏る傾向があるので、1つだけ異常に肥大化したデータが出来ないように期間や項目、サイズに何らかの制限を最初に加えておかないと1つだけ肥大化したデータに全体的に足を引っ張られる事になってしまう恐れがあるので要注意かな、と思いました。
ETLで抽出したデータをデータレイクに落とし込んでいるイメージで選択したアイキャッチ画像のクレジットはPhoto by Blake Wheeler on Unsplash
データの保存と管理の方法は、過去10年間で完全に変化しました。私たちはETL(Extract(抽出)/Transform(変換)/Load(取り込み)、例えば、Excelファイルからデータを「抽出」して、CSVに「変換」して、データベースに「取り込む」等の一連の処理及びその処理を自動化するツール類)の世界から、その順番を変更したELTの世界に移行しつつあり、Fivetranのような企業がトレンドを推し進めました。ただし、そこで止まるとは思いません。ELTは、EL(T)、(ELがTから切り離される)への移行です。そして、これを理解するには、この傾向の根本的な理由を特定する必要があります。将来に向けて何が待ち受けているかを示す可能性があるからです。
これがこの記事で解説する事です。私は、データ統合のための新しいオープンソース標準であるAirbyteの共同創設者です。
ETLの問題は何でしょうか?
これまで、データパイプラインプロセスは、データの抽出、変換、およびウェアハウスまたはデータレイクへのロードで構成されていました。この順番には重大な欠点があります。
・柔軟性の欠如
ETLは本質的に厳格です。これにより、データアナリストは、データを使用するすべての方法、作成するすべてのレポートを事前に知る必要があります。彼らが変更を行う際にコストがかかる可能性があります。これは、最初の抽出工程に関わるデータ利用者に影響を与える可能性があります。
・視認性の欠如
データに対して実行される変換により、元データの一部が見えなくなります。データアナリストには、データウェアハウス内の全てのデータが表示されるわけではなく、変換フェーズ終了後にも保持されたデータのみが表示されます。適切に区分されていないデータに基づいて結論が導き出される可能性があるため、これは危険です。
・アナリスト自身で作業する事が困難
大事な事ですが、ETLベースで大規模なデータパイプラインを構築する事は、多くの場合、データアナリストのエンジニアリング能力を超えた作業になります。通常、各データソースを抽出して変換するための追加のプログラミングと共に、エンジニアリング手腕の緊密な連携が必要になります。
このようなETLベースの複雑なエンジニアリングプロジェクトが維持できない場合、場当たり的で時間がかかり、最終的には持続不可能になる環境で分析を行い、レポートを作成する事になります。
なぜELTはETLよりはるかに優れているのでしょうか?
・クラウドベースで計算処理とデータ保存ができるようになっている
社内サーバ(on-premises)で計算処理とデータ保管のコストが高いため、ETLアプローチがかつて必要でした。しかし、Snowflakeなどのクラウドベースのデータウェアハウスの急速な成長と、クラウドベースの計算処理とデータ保存コストの急落により、最終的なデータ取り込みをする前に変換を続行する理由はほとんどありません。実際、TとL、2つの処理を入れ替える事で、アナリストは自律的な方法でより良い仕事をすることができます。
・ELTは、アナリストの迅速な意思決定をサポート可
データを変換せずにデータを読み込む事ができるのならば、従来のようにアナリストがデータ分析して洞察を得る前に正確なデータ型を決定する必要はなくなります。
代わりに、基になるソースデータを「信頼できる唯一の情報源」としてデータウェアハウスに直接複製します。その後、アナリストは必要に応じてデータの変換を実行できます。アナリストはいつでも元のデータに戻ることができ、データの整合性を損なう可能性のある変換処理に悩まされることはなく、自由に分析できます。これにより、ビジネスインテリジェンスプロセスは比類のない柔軟性と安全性を備えるようになります。
ELTは、会社組織全体のデータリテラシーを促進します
ELTアプローチをLooker、Mode、TableauなどのクラウドベースのBIツール(Business Intelligence tool)と組み合わせて使用すると、組織全体で共通分析データへのアクセスが広まります。ビジネスインテリジェンスダッシュボードによりは、比較的技術に詳しくないユーザーでもアクセスできるようになります。
私たちはAirbyteのELTの大ファンでもあります。しかし、ELTはデータ統合の問題を完全に解決しているわけではなく、独自の問題があります。ELはTから完全に切り離す必要があると思います。
現在何が変わりつつあるのでしょうか?そしてなぜEL(T)が未来なのでしょうか?
データレイクとデータウェアハウスの統合
Andreessen Horowitzは、データインフラストラクチャがどのように進化しているかについて優れた分析を行いました。これは、業界のリーダーと多くのインタビューをした後に彼らが思いついた最新のデータインフラストラクチャのアーキテクチャ図です。
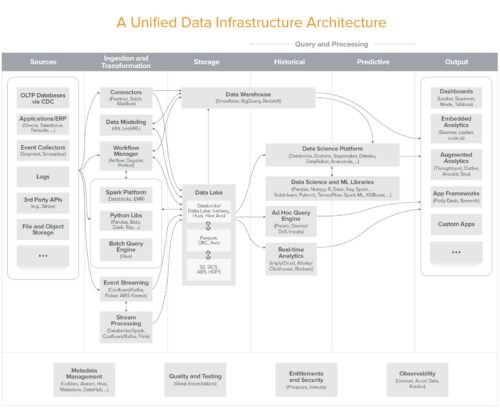
データインフラストラクチャは、高レベルで2つの目的を果たします。
(1)データの利用を通じてビジネスリーダーがより良い意思決定を行う事を支援します(分析的用途)
(2)機械学習などを介して、データインテリジェンスを顧客向けアプリケーションに組み込みます(運用的用途)
これらの幅広い用途を中心に、2つの並列する基盤システムが成長しました。
データウェアハウスは、分析システムの基盤を形成します。ほとんどのデータウェアハウスは、構造化された形式でデータを保存します。これらは、通常SQLを使用してコアビジネスで記録された数値から洞察を生成するように設計されています。(Pythonの人気は高まっていますがSQLが使われる事が多いです)
データレイクは、運用システムの基盤です。データを生の形式で保存することにより、アプリケーションやより高度なデータ処理のニーズに必要な柔軟性、拡張性、パフォーマンスを提供します。データレイクは、Java/Scala、Python、R、SQLなどの幅広い言語で使われます。
本当に興味深いのは、最新のデータウェアハウスとデータレイクが互いに類似し始めている事です。どちらも、安価なストレージ、規模拡大の容易性が向上、半構造化データ型、ACIDトランザクション、対話的なSQL実行などの機能を提供します。
従って、データウェアハウスとデータレイクが収束への道を進んでいるのではないかと疑問に思われるかもしれません。それらは可換可能になりますか? データウェアハウスは運用ユースケースにも使用可能になるのでしょうか?
EL(T)は、分析と運用MLの両方の用途をサポート可能です。
ELは、ELTとは対照的に、Extract-Load部分から発生する可能性のある変換タスクを完全に切り離します。運用用途では、受信データの活用方法が全て異なります。独自の変換プロセスを使用するものもありますし、変換しないものもあります。
分析用途の場合に関しては、アナリストはある時点で自分のニーズに合わせて受信データを正規化する必要があります。ただし、ELをTから切り離す事で、必要な正規化ツールを選択できます。DBT(訳注:Data Build Tool、SELECT文を書く事でデータウェアハウス内のデータを変換するFishtown Analytics社が提供するサービス/ツール)は、最近、データエンジニアリングチームとデータサイエンスチームの間で大きな注目を集めています。これは、オープンソース界で変換タスクの標準ツールとなりました。自動データパイプラインサービスを提供するFivetranでさえ、DBTと統合して、チームがDBTに慣れている場合はDBTを使用できるようにしています。
ELはより高速にスケーリングし、エコシステム全体を活用するようになります。変換はデータを使用する全ての場所で必要になります。企業内の特定のニーズ毎に、ツール毎に固有のデータ正規化が必要になります。
ELをTから切り離すことで、業界は多種多様なデータ接続に対応するためにコネクタを使い始めることが可能になります。Airbyteでは、「コネクタ製造工場」を建設しているため、数か月後には1,000を超える事前開発されたデータコネクタを入手できます。
更に、前述のように、チームがエコシステム全体をより簡単に活用するのに役立ちます。あなたはあらゆるニーズに対応するオープンソース標準を見据える事ができ、将来のデータアーキテクチャは次のようになります。
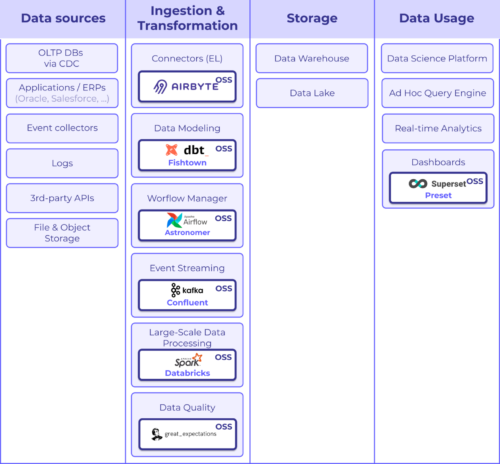
最終的に、E(抽出)とL(取り込み)はT(変換)から切り離されます。
あなたは私達の意見に同意しますか?
3.ETLの未来がELTではなくEL(T)である理由関連リンク
1)www.kdnuggets.com
Why the Future of ETL Is Not ELT, But EL(T)

