
1.CLIP:学習していない視覚タスクを実行なニューラルネット(3/3)まとめ
・CLIPは一般的な物体認識には優れているが抽象的または体系的なタスクには苦戦
・CLIPは、言葉遣いや言い回しに過敏で機能させるために試行錯誤も必要
・分類対象の設計がCLIPのパフォーマンスやバイアスに大きく影響する可能性
2.CLIPの制限事項
以下、openai.comより「CLIP: Connecting Text and Images」のまとめです。元記事の投稿は2021年1月5日、Alec Radfordさん、Ilya Sutskeverさん、Jong Wook Kimさん、Gretchen Kruegerさん、Sandhini Agarwalさん, Justin Jay Wangさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by STIL on Unsplash
(2)CLIPは柔軟で汎用性があります
CLIPモデルは、自然言語から直接幅広い視覚的概念を学習するため、既存のImageNetモデルよりもはるかに柔軟で汎用性があります。CLIPモデルは多くの異なるタスクをゼロショットで実行できることがわかりました。これを検証するために、きめ細かい物体分類(fine-grained object classification)、地理的位置特定(geo-localization)、動画内の行動認識(action recognition in videos)、OCR(光学文字認識、Optical Character Recognition)などのタスクを含む、30を超えるさまざまなデータセットでCLIPのゼロショットパフォーマンスを測定しました。
特に、OCR学習は、標準のImageNetモデルでは発生しない刺激的な動作の例です。前述の例では、各ゼロショット分類器からランダムに選択された予測を視覚化しています。
この発見は、線形プローブを使用した標準的な特徴表現学習評価にも反映されています。最高のCLIPモデルは、テストした26の異なる転移データセットのうち20で、公開されている最高のImageNetモデルであるNoisy Student EfficientNet-L2よりも優れています。
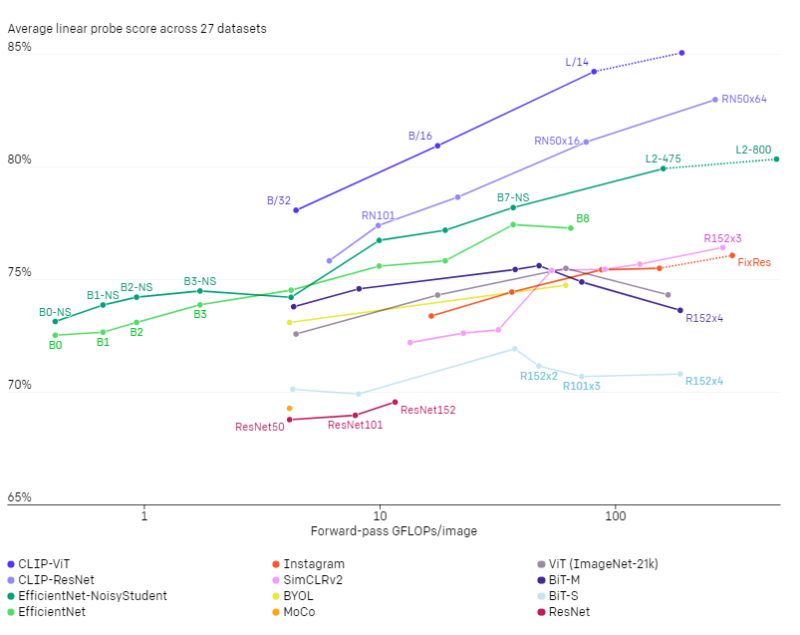
きめ細かい画像分類、OCR、ビデオ内の行動認識、地理的位置特定などのタスクを測定する27のデータセット群全体で、CLIPモデルがより広く有用な画像特徴表現を学習することがわかります。CLIPモデルは、比較対象とした10の従来アプローチのモデルよりも計算効率が高くなっています。
制限事項
CLIPは通常、一般的な物体の認識に優れていますが、画像内の物体の数を数えるなどのより抽象的なまたは体系的なタスクや、写真に写っている最も近い車がどれだけ近いかを予測するなどのより複雑なタスクには苦労します。これらの2つのデータセットでは、ゼロショットCLIPはランダムな推測よりもわずかに優れています。ゼロショットCLIPは、車のモデル、航空機のバリエーション、花の種の違いを区別するなど、非常にきめ細かい分類でもタスクに特化したモデルと比較すると苦戦します。
CLIPは、トレーニング前のデータセットでカバーされていない画像への一般化もまだ不十分です。たとえば、CLIPはOCRシステムの機能を学習する事ができますが、MNISTデータセットに格納されている手書きの数字を使って評価すると場合、ゼロショットCLIPは88%の精度しか達成できません。人間が同じデータセットを使って達成した99.75%の精度をはるかに下回ります。
最後に、CLIPのゼロショット分類器は、言葉遣いや言い回しに過敏です。うまく機能させるために試行錯誤して「入力を上手く伝える技術(prompt engineering)」が必要になる場合があることが確認されています。
より広範な影響
CLIPを使用すると、ユーザーは独自の分類器を設計でき、タスク固有のトレーニングデータが不要になります。この際、分類クラスの設計方法は、モデルのパフォーマンスとモデルのバイアスの両方に大きく影響する可能性があります。
例えば、Fairfaceレースラベルを含む一連のラベルと、「犯罪者」、「獣」などの少数の悪質な用語が与えられた場合、モデルは0~20歳の人々の画像を32.3%の割合で言語道断なカテゴリに分類する傾向があることがわかります。ただし、「子供」を選択可能な用語としてリストに追加すると、この動作は約8.7%に低下します。
さらに、CLIPはタスク固有のトレーニングデータを必要としないため、特定のニッチなタスクをより簡単に実現できます。これらのタスクの一部はプライバシーまたは監視関連のリスクを高める可能性があり、有名人の識別に関するCLIPのパフォーマンスを調査することでこの懸念を調査しました。
CLIPは、100の候補から選択した場合、雑踏の中に写っている有名人の画像分類のトップ1精度が59.2%であり、1000の可能な選択肢から選択した場合のトップ1の精度は43.3%です。タスクにとらわれない事前トレーニングでこれらの結果を達成することは注目に値しますが、このパフォーマンスは、広く利用可能な本番レベルのモデルと比較した場合、競争力がある精度ではありません。
CLIPが私たちの論文で提起する課題をさらに調査し、この作業がそのようなモデルの機能、欠点、およびバイアスの特性評価に関する将来の研究の動機付けになることを願っています。私達は、そのような質問について研究コミュニティと関わることに興奮しています。
結論
CLIPを使用して、インターネットから収集された自然言語を使った事前トレーニングが、タスクにとらわれずにその他の深層学習のパフォーマンスを向上させるために活用できるかどうかをテストしました。
このアプローチをコンピュータービジョンに適用してこれまでに確認できた結果に興奮しています。GPTファミリと同様に、CLIPは事前トレーニング中にさまざまなタスクを学習できます。これをゼロショット転移を使って示しました。
また、ゼロショット評価がモデルの能力をより代表する尺度となる事を示唆するImageNetを使った調査結果にも勇気づけられています。
3.CLIP:学習していない視覚タスクを実行なニューラルネット(3/3)まとめ
1)openai.com
CLIP: Connecting Text and Images
2)cdn.openai.com
Learning Transferable Visual Models From Natural Language Supervision(PDF)
3)github.com
openai / CLIP

