
1.VoiceFilter-Lite:オンデバイスの音声認識の改善(1/2)まとめ
・2018年に自分の声を登録して音声認識機能をパーソナライズするVoiceFilterを発表
・VoiceFilterは成功したがスマートフォンなどのデバイス上で実行するには制限があった
・VoiceFilter-Liteはオンデバイス実行可能で入り混じった音声の認識を大幅に改善するモデル
2.VoiceFilter-Liteとは?
アイキャッチ画像のクレジットはPhoto by GESPHOTOSS on Unsplash
ユーザーが音声コマンドを使用してデバイスと対話できるようにする音声支援テクノロジーは、様々な異なる声を持つユーザーに個別に応答する能力を持つために正確な音声認識技術を必要としています。
しかし、多くの実際の使用例では、そのようなテクノロジーへ入力される音声は、喧騒の中で入り混じっている事が多く、多くの音声認識アルゴリズムに大きな課題をもたらします。
2018年に、GoogleはVoice Matchを活用して、ユーザーが自分の声を登録できるようにすることで、支援技術とのやり取りをパーソナライズするVoiceFilterシステムを公開しました。
VoiceFilterアプローチは非常に成功し、従来のアプローチよりも優れたソース対歪み比(SDR:Source to Distortion Ratio)を実現しています。しかし、スマートフォンなどのデバイス上で効率的なストリーミング音声認識を行うためには、モデルサイズ、CPUとメモリの制限、バッテリー使用量の考慮事項、遅延の最小化などの各種制限に対処する必要があります。
論文「VoiceFilter-Lite: Streaming Targeted Voice Separation for On-Device Speech Recognition」では、選択した話者の登録された音声を活用することにより、入り混じった音声の音声認識を大幅に改善できる、デバイス上で使用可能なVoiceFilterのアップデート版を紹介します。
重要な事は、このモデルは既存のデバイス上の音声認識アプリケーションと簡単に統合できるため、インターネット接続が利用できない場合でも、ユーザーは周囲が非常に騒がしい状況でも音声支援機能を使用できます。私達の実験では、2.2MBのVoiceFilter-Liteモデルにより、入り混じった音声の単語誤り率(WER:Word Error Rate)が25.1%向上することが示されています。
オンデバイス音声認識の改善
元のVoiceFilterシステムは、使用者の音声信号を他の音声が重複している元音声から分離することに非常に成功していますが、そのモデルサイズ、計算コスト、および反応速度は、モバイルデバイス上での音声認識には適していません。
新しいVoiceFilter-Liteシステムは、デバイス上のアプリケーションに適合するように注意深く設計されています。VoiceFilter-Liteは、音声波形を処理する代わりに、音声認識モデルとまったく同じ入力特徴表現(stacked log Mel-filterbanks)を使用し、使用者に属していない音声コンポーネントをリアルタイムで除外することでこれらの特徴表現を直接強化します。
ネットワークトポロジのいくつかの最適化すると共に、実行時の作業量が大幅に削減されます。TensorFlow Liteライブラリを使用してニューラルネットワークを量子化した後、モデルサイズはわずか2.2MBであり、ほとんどのオンデバイスアプリケーションに適合します。
VoiceFilter-Liteモデルをトレーニングするために、ノイズの多い音声のフィルターバンク(訳注:入力信号を帯域毎に分割したもの)が、ターゲットスピーカーのIDを表すembeddingベクトル(つまり、dベクトル)と共にネットワークへの入力として供給されます。
ネットワークはマスクを予測します。これは、要素毎に入力に乗算されて、「拡張フィルターバンク」を生成します。損失関数は「拡張フィルターバンク」と「トレーニング中のクリーンなスピーチからのフィルターバンク」の違いを最小限に抑えるように定義されています。
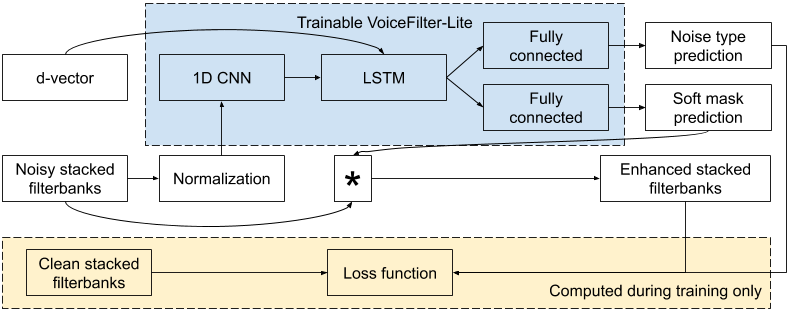
VoiceFilter-Liteシステムのモデルアーキテクチャ
3.VoiceFilter-Lite:オンデバイスの音声認識の改善(1/2)関連リンク
1)ai.googleblog.com
Improving On-Device Speech Recognition with VoiceFilter-Lite
2)arxiv.org
VoiceFilter-Lite: Streaming Targeted Voice Separation for On-Device Speech Recognition
VoiceFilter: Targeted Voice Separation by Speaker-Conditioned Spectrogram Masking
Generalized End-to-End Loss for Speaker Verification

