
1.RigL:ニューラルネットワークの冗長性を動的に最適化(3/3)まとめ
・RigLのパフォーマンスはトレーニング時間を伸ばすと基本時間の百倍までは常に改善された
・ResNet-50では最先端のtop 1精度、MobileNet-v1でも少ない反復回数で高精度を達成
・新しいハードウェアは疎なモデルの性能を向上させる事が予想されRigLは進歩を促進
2.RigLの性能
以下、ai.googleblog.comより「Improving Sparse Training with RigL」の意訳です。元記事の投稿は2020年9月16日、Utku EvciさんとPablo Samuel Castroさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by fran hogan on Unsplash
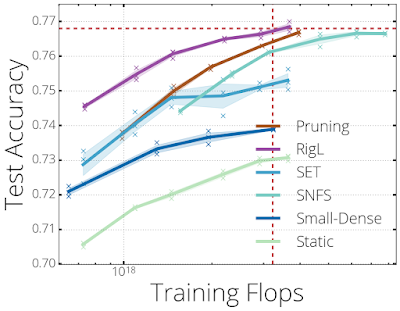
均一なスパース分布で80%疎なResNet-50アーキテクチャをトレーニングした際の各手法のパフォーマンス。各曲線上の点は、個々のトレーニングに対応しており、トレーニング時間を増加させています。標準的な高密度ResNet-50をトレーニングするために必要なFLOP数とそのパフォーマンスは、赤い破線で示されています。RigLは、サイズが5倍小さいにも関わらず、標準のResNet-50のパフォーマンスに匹敵します。
トレーニング時間とパフォーマンスの関係を観察するため、より長い時間トレーニングを実行して結果を比較しました。
考慮した時間内(基本時間から基本時間の百倍まで)では、RigLのパフォーマンスはトレーニング時間を追加する事によって常に改善されました。RigLは、99%疎なResNet-50アーキテクチャを使ったトレーニングで68.07%のtop 1精度という最先端のパフォーマンスを実現しました。
同様に、RigLを使用した90%疎なMobileNet-v1アーキテクチャでは、70.55%のtop1精度を達成しました。少ない反復回数で同じ精度を得られた事は、将来の研究のエキサイティングな方向を示しています。
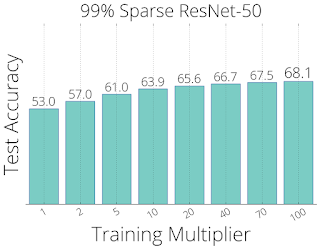
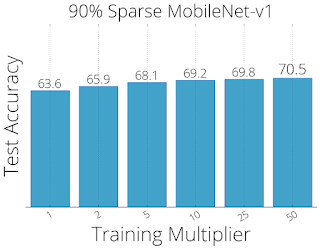
99%疎なResNet-50(左)および90%疎なMobileNets-v1(右)アーキテクチャをトレーニングする際のRigL精度とトレーニング時間の関係
その他の実験には、CIFAR-10データセットでの画像分類や、WikiText-103データセットでRNNを使用した文字ベースの言語モデリングが含まれます。これらは論文内で読む事ができます。
今後の研究
RigLは、3つの異なるシナリオで役立ちます。
(1)製品展開を目的としたスパースモデルの精度の向上
(2)限られた回数の反復でしかトレーニングできない大規模なスパースモデルの精度の向上
(3)スパースプリミティブ(sparse primitives)と組み合わせて、他の方法では不可能だった非常に大きな疎なモデルのトレーニング
3番目のシナリオは、スパース性に対するハードウェアとソフトウェアのサポートがないため、未踏のままです。
それにもかかわらず、現在のハードウェアで疎なネットワークのパフォーマンスを改善するための研究が続けられており、新しいタイプのハードウェアアクセラレータはパラメータのスパース性のサポートが向上すると予想されます。RigLがそのような進歩を活用し、それらの動機付けを行うためのツールを提供してくれることを願っています。
謝辞
論文のプレプリントに関するフィードバックを提供してくれたEleni Triantafillou, Hugo Larochelle, Bart van Merrienboer, Fabian Pedregosa, Joan Puigcerver, Danny Tarlow, Nicolas Le Roux, Karen Simonyanに感謝します。SNIP実装の検証とデバッグを支援してくれたNamhoon Lee。分散型トレーニングバグの発見と解決を支援してくださったChris Jones。アルゴリズムの視覚化を作成してくれたTom Smallにも同様に感謝します。
3.RigL:ニューラルネットワークの冗長性を動的に最適化(3/3)関連リンク
1)ai.googleblog.com
Improving Sparse Training with RigL
2)proceedings.icml.cc
Rigging the Lottery:Making All Ticket Winners(PDF)
3)github.com
google-research/rigl
4)www.nature.com
Scalable training of artificial neural networks with adaptive sparse connectivity inspired by network science(SET)
5)arxiv.org
Sparse Networks from Scratch: Faster Training without Losing Performance(SNFS)
SNIP: Single-shot Network Pruning based on Connection Sensitivity

