
1.PWIL:敵対的トレーニングに依存しない摸倣学習(2/2)まとめ
・PWILは敵対的手法でないためエージェントとエキスパートを直接類似させる事が可能
・最先端の摸倣学習は敵対的トレーニングに依存しているアルゴリズム的に不安定
・PWILは敵対的トレーニングに依存せず摸倣元データが少なくとも対応可能な摸倣学習
2.模倣学習の類似度を測る新しい尺度
以下、ai.googleblog.comより「Imitation Learning in the Low-Data Regime」の意訳です。元記事の投稿は2020年9月15日、Robert DadashiさんとLéonard Hussenotさんによる投稿です。
こちら、地味ですが実はオフライン強化学習の飛躍に繋がる可能性を秘めているお話と思います。
アイキャッチ画像のクレジットはPhoto by Fabrizio Verrecchia on Unsplash
分布マッチング問題としての模倣学習
PWIL法は、分布マッチング問題として模倣学習を新たに定式化するアイディアに基づいており、本件の場合は、ワッサースタイン距離です。
敵対的な模倣学習の最初のステップは、デモンストレーションのデータから「エキスパートが行ったアクションと対応する環境の状態の分布」を推測することです。次に、環境との相互作用を通じて、エージェントとエキスパートの状態とアクションの分布の間の距離を最小化していきます。
対照的に、PWILは敵対的ではない手法であり、最小/最大の最適化問題を回避し、エージェントとエキスパートの状態とアクションのペアの分布間のワッサースタイン距離を直接最小化できます。
PWIL(Primal Wasserstein Imitation Learning)
正確なワッサースタイン距離の計算は、エージェントの軌道を最後まで待つ必要があるため、制限的になる可能性があります。つまり、エージェントが環境とのやり取りを完了したときにのみ報酬を計算できます。
この制限を回避するには、代わりに距離の上限を使用します。上限から、強化学習により最適化する報酬を定義できます。
これにより、MuJoCoシミュレーターの多数の移動タスクで、エキスパートの行動を実際に回復し、エージェントとエキスパートの間のWasserstein距離を最小化することを示しました。
敵対的な模倣学習手法では、エージェントは環境と相互作用を繰り返して報酬関数を最適化していくため、継続的に報酬関数を再推定する必要があります。
それに対してPWILは、デモンストレーションのデータからオフラインで報酬関数を定義します。これは更新される事がなく、敵対的な摸倣学習手法よりも実質的に少ないハイパーパラメーターで済みます。
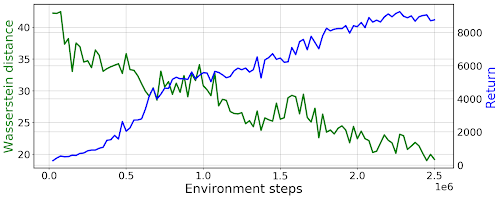
PWILを使ったHumanoidタスクの学習曲線
緑線は「エキスパートの状態とアクションの分布」とのワッサースタイン距離
青線エージェントが達成した報酬の合計
模倣学習の類似度を測る尺度としてのワッサースタイン距離
機械学習の多くの課題と同様に、多くの模倣学習手法は合成タスクを使って評価されます。合成タスクでは通常、タスクの報酬関数を利用可能であり、この報酬関数を使って期待される報酬の合計を算出可能です。報酬の合計、つまりパフォーマンスの観点からエキスパートとエージェントの行動の類似性を測定します。
PWILは副産物として、タスク報酬の合計を必要としない、エキスパートの動作を任意の摸倣学習手法のエージェントの動作と比較できる尺度の作成に繋がりました。
合成タスクのようにパフォーマンスの観点から比較するだけでなく、ワッサースタイン距離をどれだけ摸倣できているかの観点で比較できます。
まとめ
環境との相互作用にコストがかかる場合(実際のロボットや複雑なシミュレーターなど)、PWILは主要な候補となります。PWILはエキスパートの行動を回復させる事ができるだけでなく、PWILが定義する報酬関数は調整しやすく、環境との相互作用が不要なためです。
これにより、現実世界のシステムへの展開、PWILを(状態やアクションではなく)デモ状態にのみアクセスできる設定でも利用できるように拡張する事、PWILを視覚ベースのタスクに適用するなど、将来の調査のための複数の機会が開かれました。
謝辞
共著者のMatthieu GeistとOlivier Pietquinに感謝します。
Zafarali Ahmed, Adrien Ali Taïga, Gabriel Dulac-Arnold, Johan Ferret, Alexis Jacq and Saurabh Kumarにも同様に、原稿に意見をくれた事に感謝します。
3.PWIL:敵対的トレーニングに依存しない摸倣学習(2/2)関連リンク
1)ai.googleblog.com
Imitation Learning in the Low-Data Regime
2)arxiv.org
Primal Wasserstein Imitation Learning
An Algorithmic Perspective on Imitation Learning
3)papers.nips.cc
Generative Adversarial Imitation Learning(PDF)

