
1.組成の一般化能力の測定(3/3)まとめ
・compound divergenceという新しい指標によりデータセットの難度を数値で表す事ができた
・代表的な3つの標準的なMLアーキテクチャは難度があがるにつれて正確性が直線的にさがってしまう
・従って標準的なMLアーキテクチャは組成を一般化する事が出来ておらず新たなアプローチが必要
2.compound divergence
以下、ai.googleblog.comより「Measuring Compositional Generalization」の意訳です。元記事の投稿は2020年3月6日、Marc van Zeeさんによる投稿です。アイキャッチ画像のクレジットはPhoto by Raphaël Biscaldi on Unsplash
CFQを使った「組成の一般化」実験
与えられたトレーニングデータとテストデータについて、トレーニングデータとテストデータセットの複合分布が非常に類似している場合、それらのcompound divergenceは0に近くなり、組成の一般化を試験する用途としては難しい試験ではないことを示しています。compound divergenceが1に近いということは、トレーニングデータとテストデータセットに多くの異なる複合物があることを意味し、組成の一般化のテストとして適しています。つまり、compound divergenceは、「複合分布の難度」を表していると見なす事ができます。
0~0.7(最大値)の範囲のcompound divergenceを持つCFQデータセットを使用して、トレーニングセットとテストセットをアルゴリズム的に生成しました。
要素の相違を非常に小さく修正します。次に、難度の異なる各train-test分割について、3つの標準MLアーキテクチャ(LSTM + attention、Transformer、およびUniversal Transformer)のパフォーマンスを測定しました。結果を下のグラフに示します。
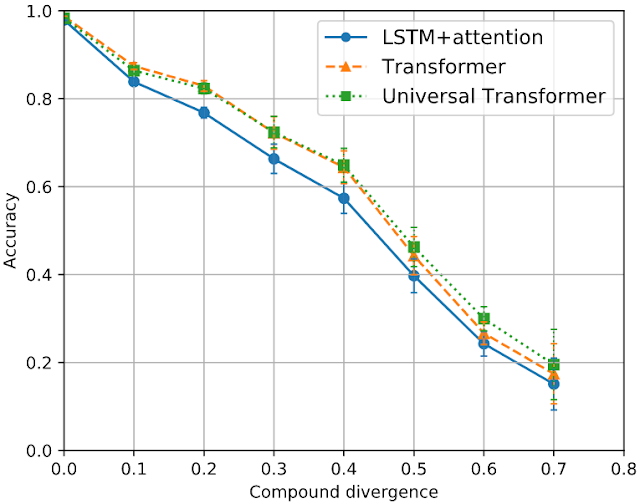
3つのMLアーキテクチャのcompound divergenceと精度
compound divergenceと精度の間には、驚くほど強い負の相関があります
モデルによって出力された文字列と正解を比較することにより、モデルのパフォーマンスが測定できます。compound divergenceが非常に低い場合(つまり簡単な場合)、全てのモデルで95%を超える精度が達成されています。
最高のcompound divergenceのケース(つまり一番難しい場合)の平均精度は、全てのアーキテクチャで20%未満です。これは、train-testの間で同様の要素分布を持つ大規模なトレーニングセットでも、アーキテクチャを十分に一般化するには不十分であることを意味します。
全てのアーキテクチャで、compound divergenceと精度の間に強い負の相関があります。これは、compound divergenceが、これらのMLアーキテクチャが組成を一般化するために克服できていない困難の核心部分をうまく捕捉していることを示しているようです。
将来の研究に有望な方向性は、入力言語または出力クエリに教師なしの事前トレーニングを適用するか、syntactic attentionなど、より多様な、またはよりターゲットを絞った学習アーキテクチャを使用することです。
このアプローチを視覚的推論などの他のドメインに適用することも興味深いでしょう。CLEVRに基づいて、または曖昧な組成要素、否定、定量化、比較、追加の言語、および他の垂直領域の使用を含む言語理解のより広範なサブセットへのアプローチを拡張できます。
この研究により、他の研究者がベンチマークを使用して学習システムの組成の一般化能力を向上させることを期待しています。
3.組成の一般化能力の測定(3/3)関連リンク
1)ai.googleblog.com
Measuring Compositional Generalization
2)openreview.net
Measuring Compositional Generalization: A Comprehensive Method on Realistic Data
3)github.com
google-research/cfq/
4)arxiv.org
Generalization without systematicity: On the compositional skills of sequence-to-sequence recurrent networks

コメント