
1.ストリートビュー画像を道案内用AIの研究者に提供(3/3)まとめ
・Retouchdownは、TouchdownをStreetLearnに統合し、より使いやすく利用申請を簡略化したもの
・TouchdownをStreetLearnデータセットに統合した結果、14.4万のパノラマ画像が利用可能になった
・StreetLearnへの関心を申請フォームに記入して承認されるダウンロードリンクが提供される
2.Retouchdownとは?
以下、ai.googleblog.comより「Enhancing the Research Community’s Access to Street View Panoramas for Language Grounding Tasks」の意訳です。元記事の投稿は2020年2月25日、Harsh MehtaさんとJason Baldridgeさんによる投稿です。アイキャッチ画像のクレジットはPhoto by Jezael Melgoza on Unsplash
別の問題は、パノラマの間隔の粒度が異なることです。以下の図は、マンハッタンのStreetLearn(青)パノラマとTouchdown(赤)パノラマが重なり具合を示しています。黒で示されている部分が両方のデータセットで同じIDを共有する(全29,641枚中の)710パノラマです。 Touchdownはマンハッタンの半分をカバーし、パノラマの密度は似ていますが、各ノードの正確な位置は異なります。
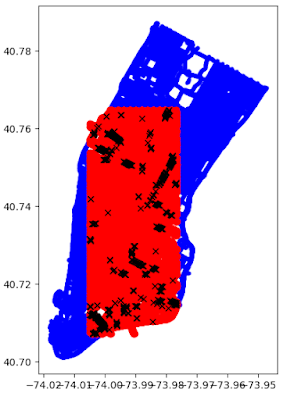
StreetLearnへのTouchdownパノラマの追加とモデルベースラインの検証
Retouchdownは、TouchdownをStreetLearnと同様に普及させやすくします。StreetLearnは、もともとGoogleと個人の権利を順守し、研究者の利用申請を簡素化し、再現性を向上させるために設計されました。Retouchdownには、より広範な研究コミュニティがTouchdownタスクを効果的に使用できるようにするためのデータとコードの両方が含まれています。最も重要なのは、データへのアクセスを確保し、再現性を容易にすることです。このため、TouchdownパノラマをStreetLearnデータセットに統合し、14.4万のパノラマ画像(26%の増加)を含むStreetLearnの新しいバージョンを作成しました。これらはすべて研究での使用が承認されています。
また、VLNとSDRのモデルを再実装し、元のTouchdownペーパーで得られた結果と同等またはそれ以上であることを示しました。これらの実装は、VALANツールキットの一部としてオープンソース化されています。以下の最初のグラフは、2019のChen等の研究のVLNタスクへの再実装です。また、SDTW測定基準が含まれており、これは、正常タスク完了と真の参照パスの忠実度を両方測定します。
以下の2番目のグラフは、SDRタスクについて同じ比較を行います。SDRの場合、precision@npxの測定値を示します。これは、モデルの予測が画像内の目標位置のnピクセル以内にある時間の割合を提供します。
モデルと処理に若干の違いがあるため、結果はわずかに改善されていますが、最も重要なことは、更新されたパノラマがTouchdownタスクの将来のモデリングを完全にサポートできることを示しています。
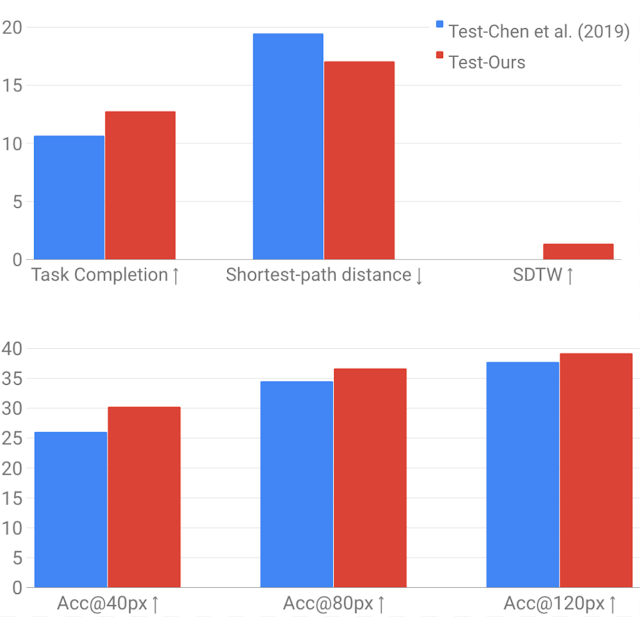
2019年のChen等による研究との性能比較
元のパノラマ(青)の使用とStreetLearnで使用可能なパノラマを使用した再実装(赤)
上:VLNの結果。ダイナミックタイムワーピングによって重み付けされたタスクの完了、最短パス距離および成功(SDTW)
下:SDRの結果。precision@npx測定基準
データの取得
パノラマの操作に関心のある研究者は、StreetLearnへの関心を申請フォームに記入する必要があります。承認されると、ダウンロードリンクが提供されます。これらの情報は、StreetLearnチームがデータの更新を通知できるように保持されています。これにより、Googleと参加研究者の両方が効果的かつ簡単に削除リクエストを尊重できます。指示とパノラマ接続データは、Touchdown githubリポジトリから取得できます。
これらの追加のパノラマをリリースすることにより、研究コミュニティがこれらの困難な実地言語理解タスクを更に前進させることができることを願っています。
謝辞
コアチームには、Yoav Artzi, Eugene Ie, そして Piotr Mirowskiが含まれます。Howard ChenがTouchdown の結果を再現してくれたことに感謝します。 Larry Lansing, Valts Blukis and Vihan Jainはコードとオープンソース化を支援してくれました。そしてGoogleリサーチの言語チーム、特にRadu Soricutはこの研究に貢献した洞察に富んだコメントを寄せてくれました。
また、データへのアクセスとデータのリリースをサポートしてくれたGoogleMapチームとGoogleストリートビューチーム、およびパノラマをレビューしてくれたデータコンピューティングチームにも感謝します。
3.ストリートビュー画像を道案内用AIの研究者に提供(3/3)関連リンク
1)ai.googleblog.com
Enhancing the Research Community’s Access to Street View Panoramas for Language Grounding Tasks
3)sites.google.com
StreetLearn Learning to navigate in cities without a map
4)github.com
VALAN: Vision and Language Agent Navigation
lil-lab/touchdown


コメント