
1.DermGAN:機械学習トレーニング用に多様な皮膚状態の医療用画像を合成(2/2)まとめ
・患部を撮影した医療画像のピントがあっているかどうかは、正確な診断のために重要
・デジタルスライドは数千の小さなパーツを繋ぎ合わせて作成されておりパーツによって焦点特性が異なる
・この問題を解決するために「ピントが外れている効果を加えた合成画像」を生成する手法を開発
2.病理画像の焦点の品質の問題
以下、ai.googleblog.comより「Generating Diverse Synthetic Medical Image Data for Training Machine Learning Models」の意訳です。元記事の投稿は2020年2月19日、Timo KohlbergerさんとYuan Liuさんによる投稿です。アイキャッチ画像のクレジットはPhoto by Noah Buscher on Unsplash
様々なスキャナーで取り込んだ画像に対応する
患部を撮影した医療画像のピントがあっているかどうかは、正確な診断のために重要です。ピントがあっていない品質の低い画像では、機械学習ベースの正確性の高い転移性乳がん検出アルゴリズムであっても、誤検知や見逃しの問題を引き起こす可能性があります。
医療画像のピントが合っているかどうかの判断は、画像取得プロセスの複雑さなどの要因により困難です。
デジタルスライドの画像は、画像全体で見ると焦点が合っていない可能性がありますが、本質的には数千の小さな視界をつなぎ合わせて作成されているため、画像の他の部分とは異なる焦点特性を持つサブ領域を持つこともできます。
これにより、膨大な量の画像のピント品質を人間が目でチェックする事は非現実的になり、焦点が合っていないスライドを検出し、焦点が合っていない領域を特定する自動化アプローチが望まれます。
焦点が合っていない領域を特定すると、その領域を再撮影する事が可能になりますし、撮影中に使用されるフォーカスアルゴリズムを改善するヒントも得られます。
Journal of Pathology Informaticsで公開された論文「Whole-slide image focus quality: Automatic assessment and impact on AI cancer detection」では、私たちは、匿名化された巨大なサイズの病理画像の焦点の品質を評価する方法を議論しています。
これを実現するために、様々な組織タイプとスライドスキャナーの光学特性を表す半合成トレーニングデータでたたみ込みニューラルネットワークをトレーニングする必要がありました。ただし、このような機械学習ベースのシステムを開発する上での主要な障壁は、ラベル付きデータの欠如でした。ピントの品質を確実に評価することは難しく、ラベル付きデータセットは利用できませんでした。
問題を悪化させたのは、ピントの品質は画像の細部に影響を与えるため、特定のスキャナーを使って収集されたデータは、物理光学システムに違いがある他のスキャナーとは特性が異なる場合がある事です。物理光学システム以外にも画像撮影時の環境、ホワイトバランス、撮影後の賀三処理アルゴリズム、大きな病理画像を再作成するために使用されるステッチ手順などにも様々な違いがあります。
この問題を解決するために、「現実世界のピントが外れている画像と同じようにピントが外れている効果を加えた合成画像」を生成する新しいマルチステップシステムを開発することになりました。
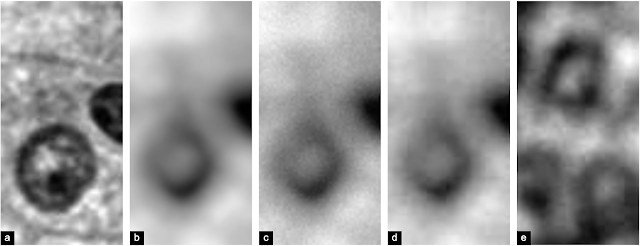
ピントをずらした画像を段階的に生成していく一連の流れ
ステップ間の違いを強調するために、画像をグレースケールで表示しています。まず、(a)焦点の合った画像を選択し、(b)ボケ効果を追加してぼやけた画像を作成します。次に、(c)センサーノイズを追加して実際のイメージセンサーをシミュレートし、(d)最後にJPEG圧縮を追加して、取得後のソフトウェア処理によって導入されたシャープなエッジをシミュレートします。(e)実際の焦点が合っていない画像を比較のために表示しています。
私達の研究では、各ステップのモデリングが複数のスキャナータイプで最適な結果を得るために不可欠であり、特筆すべき事に、実際のデータで見事に焦点が外れたパターンを検出できることが示されています。
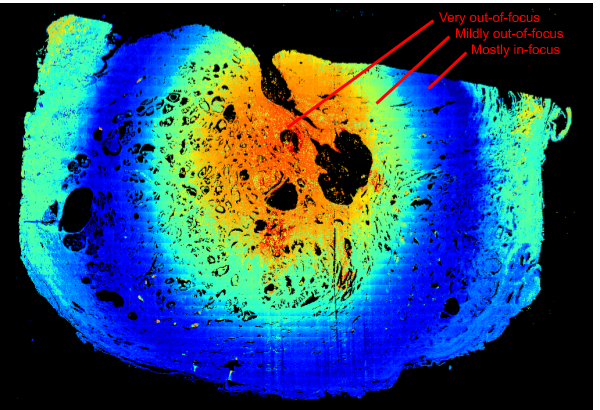
生体組織をスライスして撮影した全体画像で特に興味深い焦点外れのパターンの例。青色の領域は焦点が合っている(Mostly in-focus)とモデルによって認識されましたが、黄色(Mildy out-of-focus)、オレンジ色、または赤色(Very out-of-focus)で強調表示された領域は赤色が増すにつれて焦点が合わなくなっています。
この焦点のグラデーション(同心円で表されてます。焦点が合っていない赤とオレンジの中心部分は、緑や薄い青に囲まれ、更に焦点が合った青いリングが最外周です)は、周囲の生体組織を持ち上げている中央の硬い「石」によって引き起こされました。
今回の研究の意味と将来の展望
機械学習システムの開発に使用されるデータの量は、基本的にボトルネックになると見なされています。今回の研究では、機械学習モデルのトレーニングデータの多様性を改善し、それによって機械学習がより多様なデータセットで適切に機能する能力を向上させる事が出来るようになる合成データ生成手法を提示しました。
ただし、これらの方法で作成されたデータはモデルの性能を評価する際に使う検証データには適していません。合成データでのみで機械学習モデルが適切に機能して現実世界のデータでは機能しないようになってしまう事がないように注意する必要があります。
偏りのない統計的に厳密な評価を保証するには、十分な量と多様性の実データが依然として必要ですが、逆確率重み付けなどの手法(inverse probability weighting:例えば、胸部X線を扱う機械学習に関する研究で活用されている)が役立つ場合があります。
匿名化したデータをより効率的に活用して、データの多様性を改善し、医療用のMLモデルの開発における大規模なデータセットの必要性を減らすために、他のアプローチを引き続き検討しています。
謝辞
これらのプロジェクトには、ソフトウェアエンジニア、研究者、臨床医、職域を超えた貢献者の学際的なチームの取り組みが含まれていました。
これらのプロジェクトの主な貢献者にはTimo Kohlberger, Yun Liu, Melissa Moran, Po-Hsuan Cameron Chen, Trissia Brown, Jason Hipp, Craig Mermel, Martin Stumpe, Amirata Ghorbani, Vivek Natarajan, David CozそしてYuan Liuが含まれます。
著者はまた、Daniel Fenner, Samuel Yang, Susan Huang, Kimberly Kanada, Greg Corrado そして Erica Brandからの助言、Google Health皮膚科のメンバーと病理チーム、画像ラベル作成チームのAshwin KakarlaとShivamohan Reddy Garlapatiからの支援に感謝します。
3.DermGAN:機械学習トレーニング用に多様な皮膚状態の医療用画像を合成(2/2)関連リンク
1)ai.googleblog.com
Generating Diverse Synthetic Medical Image Data for Training Machine Learning Models
2)arxiv.org
DermGAN: Synthetic Generation of Clinical Skin Images with Pathology
3)www.jpathinformatics.org
Whole-slide image focus quality: Automatic assessment and impact on ai cancer detection


コメント