
1.Reformer:効率的なTransformer(2/2)まとめ
・リバーシブルレイヤーは、レイヤーごとに2セットのアクティベーションを持つ事でメモリを節約
・LSHとリバーシブルレイヤーによりReformerは16GBのメモリで最大100万語の連続テキストを処理可能
・Reformerは超長文処理に加えて文書以外の処理でもTransformerモデルを使用するための基盤と成り得る
2.リバーシブルレイヤーとは?
以下、ai.googleblog.comより「Reformer: The Efficient Transformer」の意訳です。元記事の投稿は2020年1月16日、Nikita KitaevさんとŁukasz Kaiserさんによる投稿です。アイキャッチ画像のクレジットはPhoto by AndriyKo Podilnyk on Unsplash
メモリの問題
Locality-Sensitive-Hashingを使う事でAttentionの問題が解決しますが、メモリの問題が残っています。ディープニューラルネットワーク中の単一レイヤーは多くの場合、最大で数GBのメモリを必要とし、通常は単一GPUにマッチします。そのため、レイヤーが1つしかなければ長いシーケンスを持つモデルでも実行できます。ただし、勾配降下法を使用してマルチレイヤーモデルをトレーニングする場合は、各レイヤーのアクティベーションを保存して、逆伝播時に使用出来るようにする必要があります。典型的なTransformerモデルには12個以上のレイヤーがあるため、これらの各レイヤーの値を保存するためにメモリを使用すると、メモリはすぐに使い果たされます。
Reformerに実装される2番目の斬新なアプローチは、メモリ内に保存するのではなく、逆伝播中にオンデマンドで各レイヤーの入力を再計算することです。
これは、ネットワークの最後の層からのアクティベーションを使用して、任意の中間層でアクティベーションを回復するリバーシブルレイヤーを使用することで実現されます。
典型的な残差ネットワーク(Residual Network)では、スタック内の各レイヤーは、ネットワークを通過するベクトルに追加され続けます。 代わりに、リバーシブルレイヤーには、レイヤーごとに2セットのアクティベーションを持ちます。1つは今説明した標準的な手順に従ったやり方で、1つのレイヤーから次のレイヤーへと徐々に更新されますが、もう1つは最初のレイヤーへの変更のみをキャプチャします。従って、ネットワークを逆に実行するには、各レイヤーに適用されたアクティベーションを単純に差し引く事で実現できます。
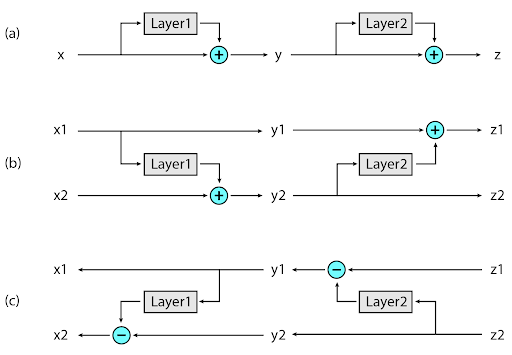
リバーシブルレイヤー:(A)標準の残差ネットワークでは、各レイヤーからのアクティベーションを使用して、次のレイヤーの入力を更新します。(B)リバーシブルネットワークでは、2セットのアクティベーションが維持され、各層の後に更新されるのは1セットのみです。(C)このアプローチにより、すべての中間値を回復するためにネットワークを逆に実行できます。
Reformerの応用
Reformerは、これら2つの斬新なアプローチを応用しているため、非常に効率的に実行可能で、わずか16GBのメモリを使用して、単一のアクセラレータで最大100万語の連続するテキストを処理できます。
Reformerは非常に効率が高いため、最新の言語関連データセットよりもはるかに大きなデータにも直接適用できます。おそらく、このような大規模なデータセットに対応可能なReformerの能力は、人工知能コミュニティを刺激してReformerを使った何かが作成されるでしょう。
大規模なコンテキストデータが十分に存在する研究領域の1つは画像生成であるため、画像を使ってReformerを実験しました。
colab「Reformer: Image Generation」では、Reformerを使用して部分的な画像を「完成」させる方法の例を紹介しています。下図の一番上の行に示されている画像の断片を入力に与えると、Reformerは完全な画像(一番下の行)を生成できます。

上図:Reformerに入力として与えた断片的な画像
下図:「完成した」画像。元の画像はImagenet64データセットに収録されているものです。
Reformerの画像処理及びビデオタスクへの適用は大きな可能性を示していますが、文章への適用はさらに刺激的です。Reformerは、小説全体を一度に1つのデバイスで処理できます。コラボ「Reformer: Text Generation」では、小説「犯罪と罰」の全体を一度のトレーニングで処理する方法を示しています。将来的には、トレーニング用の長いテキストデータセットが更に増えると、Reformerなどの手法により、一貫性のある文章を生成できるようになる可能性があります。
結論
私達はReformerは、超長文処理に加えて文書以外の処理でも、Transformerモデルを使用するための将来の基盤を提供すると考えています。オープンな研究を行うという私たちの伝統に従って、私たちはそれを更に長いシーケンスに適用する方法と、位置エンコーディングの処理を改善する方法の探索をすでに始めています。
Reformerに関する論文(ICLR 2020での口頭発表に採択)を読み、コードを調べて、独自のアイデアを開発してください。ディープラーニングで使用されている超長文データセットはまだほとんどありませんが、現実の世界では長文はどこにでもあります。Reformerの新しい応用が見つかるかもしれません。コラボ「Trax Quick Intro」から始めて、問題や質問があればコミュニティで発言してください。
謝辞
この研究は、Nikita Kitaev, Łukasz Kaiser そして Anselm Levskayaによって行われました。さらに、Afroz Mohiuddin、Jonni Kanerva、Piotr KozakowskiがTraxでの作業を行い、JAXチーム全体がサポートしてくれたことに感謝します。
3.Reformer:効率的なTransformer(2/2)関連リンク
1)ai.googleblog.com
Reformer: The Efficient Transformer
2)github.com
trax/trax/models/reformer/
3)colab.research.google.com
Trax Quick Intro
Reformer: Text Generation
Reformer: Image Generation

