
1.Deep Double Descent:ディープラーニングは二度、パフォーマンスが向上する(2/2)まとめ
・4.5倍以上のサンプルを使ってトレーニングをしているのにパフォーマンスが低下してしまう事もある
・逆により多くの学習をさせる事により過学習状態が解消される現象も見受けられる
・ディープニューラルネットワークの二重降下現象の背後にあるメカニズムは重要な未解決の問題
2.モデルサイズとデータ量とパフォーマンスの関係
以下、openai.comより「Deep Double Descent」の意訳です。元記事は2019年12月3日、Preetum Nakkiranさん、Gal Kaplunさん、Yamini Bansalさん、Tristan Yangさん、Boaz Barakさん、Ilya Sutskeverによる投稿です。
2.より多くのサンプルを使うとパフォーマンスが悪くなる状況が存在します。
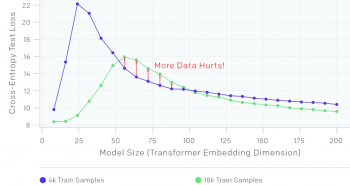
上のグラフは、ラベルにノイズが追加されていない言語翻訳タスクでトレーニングされたtransformerを示しています。予想どおり、サンプル数を増やすと、曲線はテストエラーが低くなる方向にシフトします。ただし、より多くのサンプルに適合するためにはより大きなモデルを必要とするため、サンプル数を増やすと、補間しきい値(およびテストエラーのピーク)も右にシフトします。
モデルのサイズが中間(赤い矢印で示されている50-100の区間)の場合、この2つの効果が組み合わされ、4.5倍以上のサンプルを使ってトレーニングをしているのにテストパフォーマンスが低下してしまう事がわかります。
3.より多くのトレーニングを行うと過学習が逆転する状況が存在します。
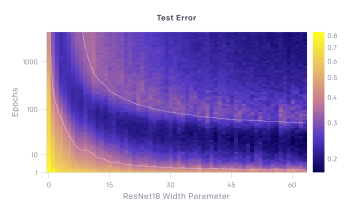
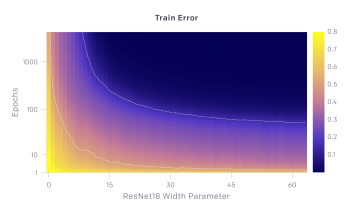
上のグラフは、テストエラーとトレーニングエラーの推移を示しています。モデルサイズがX軸で最適化ステップ数がY軸です。最適化ステップを固定すると(y座標を固定)、テストおよびトレーニングエラーはモデルサイズに応じて二重降下現象を示します。モデルサイズを固定すると(x座標を固定)すると、トレーニングが進むにつれて、テストエラーとトレーニングエラーが減少、増加、および減少します。 この現象をエポック単位の二重降下と呼びます。
訳注:オレンジ色がエラーが多く、紺色がエラーがない事を示しています。下図のTrain Error、つまり学習時のエラーは右上の方は紺色一色、つまり全くミスがない状態になっており、これは過学習で学習セットに特化しすぎてしまった状態に見えます。しかし、上図のTest Error、つまり検証セットで見てみると、過学習が起こったと思われる「し」の字型の薄いオレンジのラインを超えると再び紺色が増えており、特に右上の方、つまりパラメータ数が多いモデル且つ学習回数が多い場合にこの再び性能が向上する二重降下現象が起きている事がわかります。
一般に、モデルが学習データセットにかろうじて適合出来るサイズの場合、テストエラーのピークはどの辺りで出現するかあたりをつける事ができます。
私たちの直観は、補間しきい値近辺では、エポックデータセットに適合するモデルは事実上1つのみであり、わずかにノイズの多い、または誤って指定されたラベルに適合するように強制すると、そのグローバル構造が破壊されるという事です。
つまり、学習データを補間しつつ、且つテストデータセットで良好に機能する「良いモデル」はありません。
ただし、パラメーター数が過剰に多い状況では、エポックデータセットに適合する多くのモデルがあり、その中には「良いモデル」も存在します。更に、確率的勾配降下法(SGD)の暗黙のバイアスは、まだ解明されていない理由により、このような「良いモデル」を導きます。
ディープニューラルネットワークの二重降下現象の背後にあるメカニズムを完全に理解することは、重要な未解決の問題です。
謝辞
本研究を通して有益な議論とフィードバックをしてくれたMikhail BelkinとChris Olahに感謝します。
この投稿の拡張版は、Boaz Barakのブログ、Windows on Theoryにもあります。
3.Deep Double Descent:ディープラーニングは二度、パフォーマンスが向上する(2/2)まとめ
1)openai.com
Deep Double Descent
2)windowsontheory.org
Deep Double Descent (cross-posted on OpenAI blog)
