
1.皆のためのMLモデルの構築:機械学習の公平性を理解する(1/3)まとめ
・データと機械学習アルゴリズムに公平性を求める事は、安全で責任あるAIシステムの設計/構築に重要
・公平性は現実世界にモデルを展開した際に露わになる実務的な影響について理解する方法を提供
・製品展開が最後と考えるのではなくモデルの公平性を継続的に評価するライフサイクルを考える
2.データと機械学習アルゴリズムの公平性
以下、cloud.google.comより「Building ML models for everyone: understanding fairness in machine learning」の意訳です。元記事の投稿は2019年9月26日、Sara Robinsonさんによる投稿です。
データと機械学習アルゴリズムに公平性を求める事は、安全で責任あるAIシステムを一から設計/構築するために重要です。ビジネス業界もテクノロジー業界も双方のAI利害関係者は、AIが取り込んでしまうバイアスなどの問題に有意義に対処できるように、常に公正を追求しています。
精度は機械学習モデルの精度を評価するための1つの指標ですが、公平性は、現実世界にモデルを展開した際に露わになる実務的な影響について理解する方法を提供します。
公平性とは、データによってもたらされるバイアスを理解し、モデルが全ての人口統計学上のグループに偏りなく公平に予測を提供できるようにするプロセスです。
例えば、以下は典型的なMLの開発サイクルです。
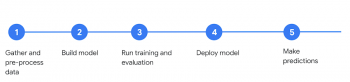
(1)データを集める→(2)モデル開発→(3)学習を行い評価する→(4)モデルを製品展開する→(5)予測を行う
以下に、黄色で、モデル開発のさまざまな段階でMのL公平性を適用できるいくつかの方法を示します。
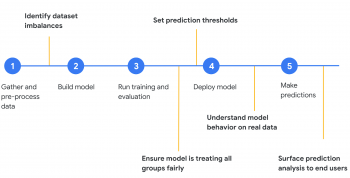
(1)データを集める→「データセットの不均衡を特定する」→(2)モデル開発→(3)学習を行い評価する→「モデルが全てのグループを公平に扱っている事を確認」→「予測閾値を設定する」→(4)モデルを製品展開する→「現実世界のデータを使った際のモデルの挙動を理解する」→(5)予測を行う→「エンドユーザーへの表面予測分析(Surface prediction analysis)」
モデルを製品展開する段階が最後と考えるのではなく、上記の手順を、モデルの公平性を継続的に評価し、新しいトレーニングデータを追加し、再トレーニングするためのライフサイクルと考えてください。お使いのモデルの最初のバージョンが展開されたら、それはモデルの性能に関するフィードバックを収集し、次のサイクルで公平性を改善するための措置をとる事をお勧めします。
このブログでは、上の図の最初の3つの公平性ステップに焦点を当てます。「データセットの不均衡の特定」、「全てのグループの公平な取り扱いの確保」、「予測しきい値の設定」です。公平性の観点からモデルを分析するための具体的な手法として、AIプラットフォームに展開されたモデルにWhat-ifツールを使用します。特に、What-ifツールの「Fairness&Performance」タブに注目します。このタブでは、個々の特徴ごとにデータをスライスし、モデルが様々なサブセットでどのように動作するかを確認できます。
この投稿では、Kaggleからダウンロードできる住宅データセットを使用して、What-ifツールで公平性の分析を実行する方法を示します。下のプレビューでわかるように、住宅の多くのデータ「面積(平方フィート)、寝室の数、キッチンの品質など」とその販売価格が含まれています。この演習では、住宅が$160kを上回るか下回るかを予測します。

本事例で扱う特徴は住宅に固有のものですが、この投稿の目的は、これらの概念を自分のデータセットに適用する方法について考える手助けをすることです。これは、データセットが人間を扱っている場合に特に重要です。
データセットの不均衡の特定
モデルの構築を開始する前に、What-ifツールを使用して、データセットの不均衡をよりよく理解し、さらにデータを追加する必要がある場所を確認できます。次のコードの断片を使用して、住宅データをPandas DataFrameとしてWhat-ifツールにロードします。
config_builder = (WitConfigBuilder(data.tolist(), data.columns.tolist()) WitWidget(config_builder, height=800)
視覚化データが読み込まれたら、「Features」タブに移動します。(カテゴリ列をPandasのダミー列に変換するための前処理をあらかじめ行っている事に注意してください)
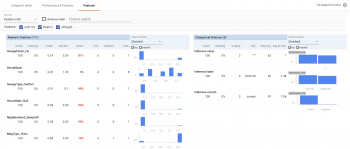
このデータセットには注意が必要な事がいくつかあります。
1)このデータセットは比較的小さく、合計1,460の事例があります。元々、回帰問題用のデータセットとして意図されて提供されていましたが、ほとんど全ての回帰問題は分類問題に変換できます。What-ifツールの機能をより強調するために、分類問題用のデータとして扱って、住宅の価値が$160kを上回るか下回るかを予測しています。
2)分類問題として扱う事にしたので、ラベルのバランスをできるだけ保つために、$160kの閾値を意図的に選択しています。715軒の住宅が$160k未満、745軒が$160k以上の価値があります。実世界のデータセットは常にそれほどバランスが取れているわけではありません。
3)このデータセットの住宅は全てアイオワ州エイムズに存在する家です。データは2006年から2010年の間に収集されました。モデルがどのような精度を達成しても、まったく異なる大都市圏、例えば、ニューヨークのような大都市の住宅価格の予測に使う事は賢明ではありません。
4)前述の留意点と似ていますが、このデータの「Neighborhood」列は完全にバランスが取れていません。NorthAmesの家の数が最も多く(225)、次のCollege Circleが150です。
5)モデルを改善する可能性のあるデータが欠落している場合もあります。例えば、元のデータセットには、この分析で除外した住宅の地下室のタイプとサイズに関するデータが含まれています。さらに、各家の以前の居住者に関するデータがあった場合はどうでしょうか?モデルにデータを与える際に何らかの特徴エンジニアリングが必要になるようなデータであっても、考えられる全てのデータソースについて考える事は重要です。
モデルのトレーニングを開始する前に上記のようなデータセット分析を行って、データセットを最適化し、潜在的なバイアスとそれを説明できるように認識しておく事をお勧めします。データセットの準備ができたら、モデルを構築してトレーニングし、What-ifツールに接続して、より詳細な公平性分析を行うことができます。
3.皆のためのMLモデルの構築:機械学習の公平性を理解する(1/3)関連リンク
1)cloud.google.com
Building ML models for everyone: understanding fairness in machine learning
2)www.kaggle.com
House Prices: Advanced Regression Techniques
3)developers.google.com
ホーム > プロダクト > Machine Learning Crash Course > Fairness
4)ai.google
Responsible AI Practices
5)cloud.google.com
インクルーシブ ML ガイド – AutoML
6)pair.withgoogle.com
Designing human-centered AI products

コメント