
1.オープンデータと機械学習を使って研究する際の新しいワークフローまとめ
・生物の多様性研究のために様々な機関が様々なデータを提供して貢献している
・機械学習でそれらのデータを利用する際は引用と帰属を尊重する従来の文化に敬意を払う必要がある
・この状況に留意してMLを利用したい生物多様性研究機関向けに新しいワークフローを発表
2.引用と帰属のルール
以下、ai.googleblog.comより「A New Workflow for Collaborative Machine Learning Research in Biodiversity」の意訳です。元記事は2019年10月25日、Serge BelongieさんとHartwig Adamさんによる投稿です。
動植物を識別する機械学習(ML)は期待通りに実現に近づいており、生物の多様性研究におけるその変革の可能性を明らかにしています。FGVCやLifeCLEFなどの国際ワークショップでは、野生生物を仕掛けカメラで撮影した映像から押花シートの標本に至るまで、最高の分類アルゴリズムを開発するためのコンペを開催しています。これらの競争から生まれた有望な結果は、生物多様性データセットとMLモデルの利用可能性をワークショップ規模から地球規模に拡大するきっかけとなりました。
強力なMLアルゴリズムを必要とするコミュニティにもたらすためには、従来の「ビッグデータ+ビッグコンピューティング」方程式以上のものが必要です。
自然史博物館から市民による科学グループなど様々な機関は、データセットの収集と注釈付けに大きな労力を割いており、彼らが共有してくれるデータにより、多数の科学研究出版物の出版が可能になりました。
しかし、学術研究界は引用(citation)と帰属(attribution)に配慮する事が慣習であり、MLがその範囲をライフサイエンスに拡大するにつれて、それらの慣習に適切に対応する事が必要となります。より広くは、MLコミュニティ内でも倫理、公平性、透明性の重要性に対する認識が高まっています。特定機関が大規模にMLのアプリケーションを開発および展開する場合、これらを考慮して設計することが重要です。
今週のBiodiversity Nextでは、Global Biodiversity Information Facility(GBIF:地球規模生物多様性情報機構)、 iNaturalist、Visipediaと共同で、MLを利用したい生物多様性研究機関向けの新しいワークフローを発表します。
世界中の数十億種以上の生物種を数千の機関が収集しています。この中でGBIFは、データの集約、チーム間のコラボレーション、引用慣行の標準化など、このワークフローを実現する上で重要な役割を果たしています。
短期的には、最も重要な役割は、MLモデルのトレーニングに媒介データ(mediated data)を使用するために、従来の慣行に新たな文化的変化が起こった事に関連しています。
データを媒介するプロセスにおいて、GBIFは、MLのトレーニングデータセットが標準化されたライセンス条件に従い、互換性のある分類法とデータ形式を使用しており、複数のソースデータセットから潜在的にサンプリングすることにより、手元のMLタスクに公正かつ十分なデータカバレッジを提供していることを保証します。
この新しいワークフローは、次の2つの部品で構成されています。
1)マシンビジョンモデルの開発と改良を支援するために、GBIFはデータセットをパッケージ化し、ライセンスが尊重され引用が実践されるように注意します。トレーニングデータセットにはデジタルオブジェクト識別子(DOI)が発行され、DOI引用グラフを通じてリンクされます。
2)アプリケーション開発者を支援するために、GoogleとVisipediaはTensorFlow Hubに自由にアクセス可能なモデルを訓練し、文書と共に公開します。これらのモデルは、その後、生物多様性の研究と市民科学グループが利用できるようになります。
ケーススタディ:インタラクティブなキノコ判別機を使用して写真から菌類を認識する例
上記のワークフローの例として、菌類認識の例を示します。この場合のデータセットは、デンマーク菌学会によって収集され、GBIFによって整形、パッケージ化、共有されました。データセットの出所、モデルアーキテクチャ、ライセンス情報などの情報は、TF Hubのモデルページで見つけることができます。モデルページ内には、ユーザーが所有するキノコ画像を識別できるインタラクティブなデモンストレーションページもあります。
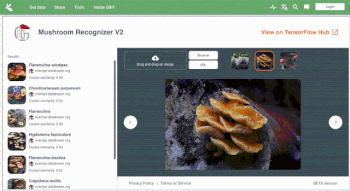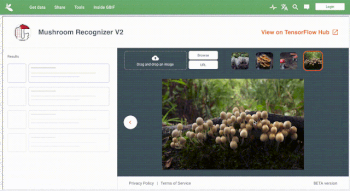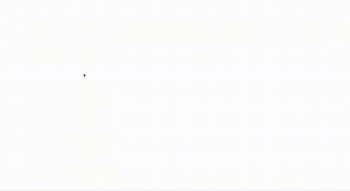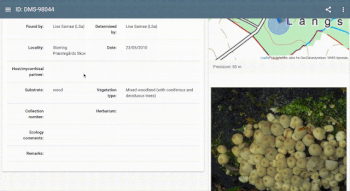
デンマーク菌学会が提供する菌類データセットでトレーニングされた公開モデルを使用した、ライブでインタラクティブなキノコ判別機の使用例
参加の招待
このイニシアチブの詳細については、GBIFのプロジェクトページをご覧ください。私たちは、生物多様性のためにMLの新しい革新的な使用方法を可能にするために、世界中の機関と協力することを楽しみにしています。
謝辞
このワークフローを開発するために協力してくれたGBIF、iNaturalist、Visipediaの協力者の皆さんに感謝します。Google社内では、Christine Kaeser-Chen, Chenyang Zhang, Yulong Liu, Kiat Chuan Tan, Christy Cui, Arvi Gjoka, Denis Brulé, Cédric Deltheil, Clément Beauseigneur, Grace Chu, Andrew Howard, Sara BeeryそしてKatherine Chouに感謝します。
3.オープンデータと機械学習を使って研究する際の新しいワークフロー関連リンク
1)ai.googleblog.com
A New Workflow for Collaborative Machine Learning Research in Biodiversity
2)www.gbif.org
Mediated Machine Vision
3)tfhub.dev
vision/embedder/fungi_V2

コメント