
1.動画用ニューラルネットワークを自動で探索する試み(2/3)まとめ
・AssembleNetでは、様々なサブネットワークを融合する新しい方法を検討した
・目的は、ビデオの外観と動きの視覚的な手がかりをまとめて、より優れた特徴表現を学習すること
・この結果、従来の手動設計の2ストリームモデルを圧倒する最先端のスコアを達成した
2.動画用のニューラルアーキテクチャ探索
以下、ai.googleblog.comより「Video Architecture Search」の意訳です。元記事の投稿は2019年10月17日、Michael S. RyooさんとAJ Piergiovanniさんによる投稿です。
私たちの実験結果は、異種のモジュールを進化させることによって得られるこのようなビデオCNNアーキテクチャの利点を確認します。
このアプローチでは、複数の並列層で構成される重要なモジュールが、人間が手で設計したモジュールよりもより高速で優れたパフォーマンスを発揮する事がよくあります。
もう1つの興味深い側面は、進化の結果、パフォーマンスが高くとも余分な計算を必要としない多様なアーキテクチャが多数得られた事です。
それらを使用してアンサンブルを形成すると、パフォーマンスがさらに向上します。 並列性のため、モデルのアンサンブルでさえ、(2+1)D ResNetなどの他の標準的なビデオネットワークよりも計算効率が高くなります。私たちはコードをオープンソース化しました。
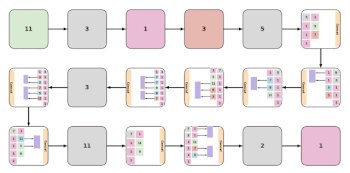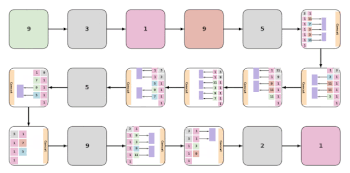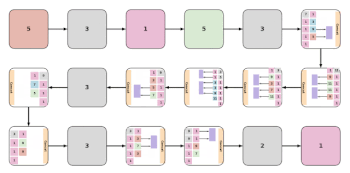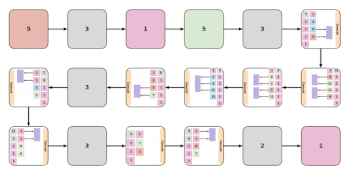
まざまなEvaNetアーキテクチャの例。各色付きボックス(大小)はレイヤーを表し、ボックスの色はそのタイプを示します。青:3D conv、オレンジ:(2+1)D conv、緑:iTGM、灰色:max pooling、紫色:averaging、ピンク:1×1コンバージョン。多くの場合、レイヤーはグループ化されてモジュール(大きなボックス)を形成します。 各ボックス内の数字は、フィルターサイズを示します。
AssembleNet:より強力で優れたマルチストリームモデルの構築
論文、「AssembleNet: Searching for Multi-Stream Neural Connectivity in Video Architectures」では、様々なサブネットワークを融合する新しい方法を検討します。これらのサブネットワークは様々な入力経路(RGBやオプティカルフローなど)と時間解像度を持っています。
AssembleNetはターゲットタスク用に最適化されている一方で、学習可能なアーキテクチャの「ファミリ」であり、入力経路を横断して特徴表現間の「接続性」を学習する一般的なアプローチを提供します。
様々な形式のマルチストリームCNNを有向グラフとして表現できる一般的な定式化を導入し、効率的な進化アルゴリズムと組み合わせて、高レベルのネットワーク接続を探索します。
目的は、ビデオの外観と動きの視覚的な手がかりをまとめて、より優れた特徴表現を学習することです。
AssembleNetは、過度に接続(overly-connected)された、マルチストリーム、マルチ解像度のアーキテクチャを進化させながら、接続の重み学習によって突然変異を導きます。この方法は、後期融合(late fusion)または中間融合(intermediate fusion)を使用する従来の手動設計の2ストリームモデルとは異なります。
私達は様々な中間接続を備えた4ストリームアーキテクチャを最初の試みとして検討しました。この4ストリームアーキテクチャーはRGBおよびオプティカルフロー毎に2つのストリームを持ち、それぞれが異なる時間解像度を持っています。
次の図は、50 – 150ラウンドにわたってランダムな初期マルチストリームアーキテクチャのプールを進化させることによって発見されたAssembleNetアーキテクチャの例を示しています。 AssembleNetを、非常に人気のある2つのビデオ認識データセットであるCharadesとMoments-in-Time(MiT)でテストしました。MiTでのパフォーマンスは34%を超えています。Charadesでのパフォーマンスは、平均平均精度(mAP)58.6%でさらに印象的ですが、従来の最もよく知られているスコアは42.5および45.2です。
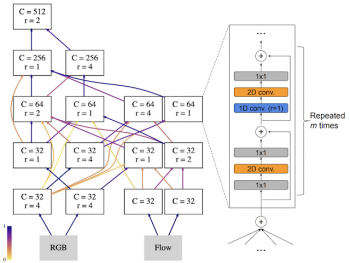
代表的なAssembleNetモデルは、Moments-in-Timeデータセットを使用して進化しました。
ノードは時空間畳み込み層のブロックに対応し、各エッジは接続性を指定します。エッジが暗いほど、接続が強くなります。AssembleNetは、学習可能なマルチストリームアーキテクチャのファミリであり、ターゲットタスク用に最適化されています。
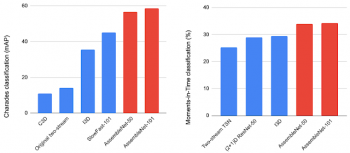
AssembleNetとCharades(左)およびMoments-in-Time(右)データセットの最新の手動設計モデルを比較した図。AssembleNet-50またはAssembleNet-101には、2ストリームのResNet-50またはResNet-101と同等の数のパラメーターがあります。
3.動画用ニューラルネットワークを自動で探索する試み(2/3)関連リンク
1)ai.googleblog.com
Video Architecture Search
2)arxiv.org
Evolving Space-Time Neural Architectures for Videos
AssembleNet: Searching for Multi-Stream Neural Connectivity in Video Architectures
Tiny Video Networks
3)github.com
google-research/evanet
