
1.M4:超多言語、大規模ニューラル機械翻訳(2/3)まとめ
・使用可能なすべてのデータを使用してトレーニングすると低リソース言語の翻訳品質が劇的に向上
・超多言語モデルは一般化に効果的であり多言語全体の特徴表現の類似性を捕捉できている可能性が高い
・異なる言語間で多言語モデルの特徴表現を比較して言語間の類似性を視覚化する事も可能
2.超多言語モデルの性能
以下、ai.googleblog.comより「Exploring Massively Multilingual, Massive Neural Machine Translation」の意訳です。元記事は2019年10月11日、Ankur BapnaさんとOrhan Firatさんによる投稿です。
使用可能なすべてのデータ(103の言語から250億以上の例)を使用してトレーニングすると、低リソース言語への強い積極的な転移が観察されます。利用可能なデータが少ない30以上の言語の翻訳品質が平均5 BLEUポイント、劇的に向上しました。
この向上効果はすでに知られていますが、バイリンガルベースライン(特定の言語ペアのみを使ってトレーニングされたモデル)と、単一の多言語モデルの比較を考えると、驚くほど勇気づけられます。(多言語モデルであっても特徴表現能力は単一のバイリンガルモデルに似ています)
この発見は、超多言語モデルが一般化に効果的であり、多数の言語全体で特徴表現の類似性を捕捉できることを示唆しています。

103の言語ペアのそれぞれに対してトレーニングされたバイリンガルベースラインに対する単一の超多言語モデルの翻訳品質の比較。
EMNLP’19の論文「Investigating Multilingual NMT Representations at Scale」では、異なる言語間で多言語モデルの特徴表現を比較しています。多言語モデルは、外部の制約を必要とせずに言語的に類似した言語の共有表現を学習できるので、これらの類似性を活用して長年の直観と経験的な結果を検証しました。
論文「Evaluating the Cross-Lingual Effectiveness of Massively Multilingual Neural Machine Translation」では、これらの学習された特徴表現が、下流タスクでの言語間の転移に関して有効である事を更に示しています。
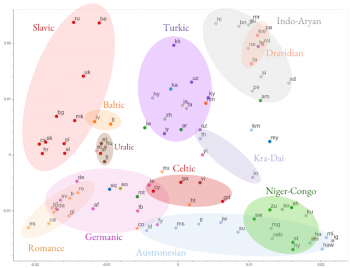
特徴表現の類似性に基づいて103の言語全てをグループ分けした図。近い言語同士で色分けされています。
3.M4:超多言語、大規模ニューラル機械翻訳(2/3)関連リンク
1)ai.googleblog.com
Exploring Massively Multilingual, Massive Neural Machine Translation
2)arxiv.org
Massively Multilingual Neural Machine Translation in the Wild: Findings and Challenges
Evaluating the Cross-Lingual Effectiveness of Massively Multilingual Neural Machine Translation

コメント