
1.音響的な手がかりと言語的な手がかりを使って発言者を特定する(3/3)まとめ
・TPUなどのアクセラレータとTensorFlowの効率的なアルゴリズムにより効率的な開発ができた
・統合モデルは音声認識と同じ様にトレーニングできるが発言者の役割を定義するタグが定義可能
・RNN-Tシステムは発言者の切り替わりや単語境界の誤りなど全てのエラーを大幅に改善した
2.RNN-Tシステムの性能
以下、ai.googleblog.comより「Joint Speech Recognition and Speaker Diarization via Sequence Transduction」の意訳です。元記事は2019年8月16日、Laurent El ShafeyさんとIzhak Shafranさんによる投稿です。
GPUやTPUなどのアクセラレータを使ってRNN-Tモデルをトレーニングすることは、損失関数の計算に順方向/逆方向アルゴリズムを実行する必要があるため、重要です。この計算には、入力シーケンスと出力シーケンスの全てのアライメントが含まれ膨大な計算が必要になります。
この問題は、TPUの利用に適した順方向/逆方向アルゴリズムが最近実装された事で解決されました。このアルゴリズムは、計算を連続する行列乗算として再割り当てします。 また、TensorFlowが実装したRNN-T損失の効率的な計算は、モデルの開発を迅速にトライアンドエラーで繰り返しながら実行する事を可能にし、非常にディープなネットワークをトレーニングする事ができました。
統合モデルは、音声認識システムと同じ様にトレーニングできます。トレーニング用に参照する写しには、発言者の言葉に続いて、発言者の役割を定義する<タグ>が含まれています。例えば、「宿題の期限はいつですか?<学生>」、「明日、授業が始まる前に提出することを期待しています<先生>」のようにです。
音声サンプルと対応する写しを使用してモデルをトレーニングする事で、ユーザーは会話の記録を入力すると、同様の形式で出力が表示されることを期待できます。
私達の分析は、RNN-Tシステムが、短い間隔での発言者の切り替わり、単語境界での音声データ分割、複数の音声が含まれている場合に誤った発言者を割り当てる事、音質の低下など、全てのエラーを改善することを示しています。
更に、RNN-Tシステムは、会話全体で一貫したパフォーマンスを示し、従来のシステムと比較して、会話ごとの平均エラー率のばらつきが大幅に低くなりました。
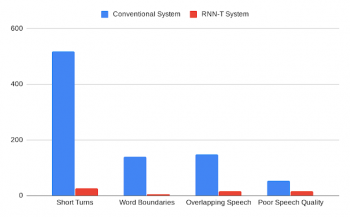
人間の注釈作業者によって分類された、従来のシステムとRNN-Tシステムがミスしたエラーの比較
更に、この統合モデルは、自動音声認識システムが聞き取ったテキストを読みやすくするためにも利用できます。例えば、適切なトレーニングデータを使用して、句読点や大文字を使用して英文を読みやすく改善することができました。この結果は、個別にトレーニングしてASRの後処理としてこれらの処理を実現していた従来のモデルよりも句読点と大文字の誤りが少ないです。
今回のモデルは現在、医療会話を理解するプロジェクトの標準コンポーネントになっており、非医療系音声サービスでもより広く採用されています。
謝辞
私たちは、Hagen Soltauに感謝したいと思います。彼の貢献がなければこの作業は不可能だったと思います。この作業は、Google BrainおよびSpeechチームと共同で実施されました。
3.音響的な手がかりと言語的な手がかりを使って発言者を特定する(3/3)関連リンク
1)ai.googleblog.com
Joint Speech Recognition and Speaker Diarization via Sequence Transduction
2)arxiv.org
Joint Speech Recognition and Speaker Diarization via Sequence Transduction

コメント