
1.集積カプセルオートエンコーダー(6/6)まとめ
・SCAE、集積カプセルオートエンコーダーはPCAEとそれに続くOCAEで構成されています
・PCAEエンコーダ、OCAEエンコーダ、OCAEデコーダ、PCAEデコーダの機能から構成される
・SCAEはパーツを推論し、それをオブジェクト化することで視点等価性を持つ特徴表現を実現
2.集積カプセルオートエンコーダー
以下、akosiorek.github.ioより「Stacked Capsule Autoencoders」の意訳です。元記事の投稿は2019年6月23日、Adam Kosiorekさんによる投稿です。
集積カプセルオートエンコーダーまとめ
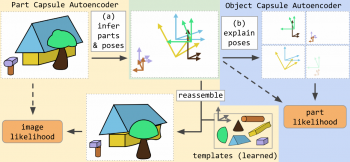
集積カプセルオートエンコーダー(SCAE:Stacked Capsule Autoencoder)は、PCAEとそれに続くOCAEで構成されています。画像をそのパーツに分解し、パーツをオブジェクトにグループ化することができます。
要約すると、SCAEは次のものから構成されています。
・PCAEエンコーダ:アテンションベースのプーリングを持つCNN
・OCAEエンコーダ:Set Transformer
・OCAEデコーダ:
・K個のMLP(オブジェクトカプセル毎に1つ)Set Transformerの出力からカプセルパラメータを予測
・オブジェクトとパーツの一定の関係を表すKxM個の3×3定数行列
・PCAEデコーダ:これはM個の定数パーツテンプレートで、各パーツカプセルに1つずつ
SCAEは特徴表現学習のための新しい方法を定義します。そこでは、任意のエンコーダがパーツとそれらのポーズを推論し、それらをオブジェクトにグループ化することによって視点等価性を持つ特徴表現を学習します。
この記事では、このアイデアの背後にある動機と高水準の直感、および手法の概要を説明しました。現在のところ、この手法の主な欠点は、パーツデコーダが固定テンプレートを使用することです。これは複雑な実世界の画像をモデル化するには不十分です。
これはまた、カプセルのより深い階層化およびカプセルデコーダを三次元ジオメトリに拡張することと共に、将来の研究が楽しみな道でもあります。
あなたが詳細に興味があるならば、私はあなたが論文の原本「Stacked Capsule Autoencoders」を読むことをお勧めします。
謝辞
この研究は、トロントにあるGoogle BrainのGeoff Hintonチームにインターンシップしている間に行われました。 私のコラボレーター、Sara Sabour、Yee Whye Teh、そしてGeoff Hintonに感謝します。 また、Ali EslamiとDanijar Hafnerに有益な議論をしていただいた事に感謝しますす。数式の作成や論文の編集を手伝ってくれたSandy H. Huangに感謝します。 Sandy、AdamGoliński、Martin Engelckeがこの投稿に関する広範なフィードバックを提供してくれました。
関連動画 Sara SabourさんによるCapsulesの解説
オマケのヒントン先生動画
ヒントン先生も凄い健脚なんですね、やっぱり運動大切
3.集積カプセルオートエンコーダー(6/6)関連リンク
1)akosiorek.github.io
Stacked Capsule Autoencoders
What is wrong with VAEs?
2)openreview.net
Matrix capsules with EM routing
3)arxiv.org
Group Equivariant Convolutional Networks
Spatial Transformer Networks
Set Transformer: A Framework for Attention-based Permutation-Invariant Neural Networks
4)medium.com
Understanding Hinton’s Capsule Networks. Part I: Intuition.
5)science.sciencemag.org
Human-level concept learning through probabilistic program induction


コメント