
1.Parrotron:発声が困難な人のために音声コミュニケーションを改善する試み(2/3)まとめ
・Parrotronは二段階にわけて学習を行う
・第一段階は様々な音声データを単一の音声に変換する事前学習
・第二段階では話者に特有の発声、および言語パターンに適応させる
2.Parrotronの二段階学習
以下、ai.googleblog.comより「Parrotron: New Research into Improving Verbal Communication for People with Speech Impairments」の意訳です。元記事は2019年7月17日、Fadi BiadsyさんとRon Weissさんによる投稿です。
第一段階のトレーニングでは、何百万もの匿名化された発話ペアで構成される、30,000時間のコーパスが使用されます。このコーパスの文章部分に対して最先端のParallel WaveNet TTS systemを実行して自動合成音声データを作成し、コーパスの音声部分とペアにします。
このデータセットには、何千もの話者による、何百もの方言/アクセント、及び様々な音響状況での録音が含まれています。そのため、多種多様な音声、言語的および非言語的な内容、アクセント、およびノイズ状態を、「普通の発声」としてモデル化することができます。
結果として得られる変換モデルは、全ての非言語情報(録音された環境、話者固有の癖、特性など)を取り除き、「誰が」、「どこで」、または「どのように」発声したのかではなく、「発声された内容」だけを保持します。この基本モデルは、第二段階のトレーニングでパーソナライズをするための土台として使用されます。
第二段階のトレーニングでは、第一段階で使ったデータセットと同じ方法で生成された発話ペアのコーパスを利用します。
しかし、第二段階ではコーパスは、ネットワークを話者に特有の音響/発音、発声、および言語パターンに適応させるために使用されます。これには、例えば、対象とする話者が特定の母音または子音をどのように変更、置換、および削減または削除するかを学習する事が含まれる場合があります。
ALS(筋萎縮性側索硬化症)の音声特性を捉えるモデルを一般化するために、私達はProject Euphoniaから派生したALS音声コーパス内の音声データを使用しました。もし、私達が特定の話者専用にモデルを特化させたい場合は、その学習用コーパス(音声データ)はその人自身が提供する必要があります。使用できるコーパスの量が多ければ多いだけ、モデルが流暢な音声に正しく変換できる可能性が高くなります。
第一段階で事前トレーニングした基本モデルのパラメータを、この2番目の小さくパーソナライズされた並列コーパスを使用して更新し、最終的なパーソナライズモデルを学習させます。
特定話者の発声スペクトログラムを生成しながら、同時に特定音素を予測するようにマルチタスクにモデルをトレーニングすると、著しい品質改善をもたらすことを私達は見出しました。
このようなマルチタスクで訓練されたエンコーダは、入力音声の潜在的特徴表現を学習していると考えることができます。潜在的特徴表現とは、言語コンテンツに関する基礎的な情報でありエンコーダはそれを保持できているのです。
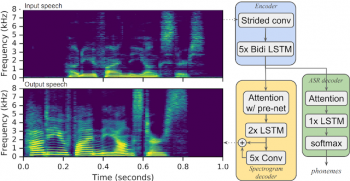
Parrotronモデルアーキテクチャの概要
入力音声のスペクトログラムは、エンコーダおよびデコーダニューラルネットワークを通過し、新しい音声で出力スペクトログラムが生成されます。
ケーススタディ
コンセプトを実証するため、私達は同僚のGoogleの研究科学者で数学者のDimitri Kanevskyと協力しました。Dimitri Kanevskyは、ロシア生まれでロシア語が母国語です。両親は聴覚に問題はありませんでしたが、彼は非常に若い頃に聴覚に困難を覚えるようになりました。
彼はティーンエイジャーの頃に英語を学びました。ロシアの発音記号やロシア語で英単語や英文の発音を学んだのです。例えば「The quick brown fox jumps over the lazy dog」はロシア語で「ЗИ КВИК БРАУН ДОГ ЖАМПС ОУВЕР ЛАЙЗИ ДОГ」となります。
結果として、Dimitriのスピーチはネイティブに英語を話す人とは相当に異なっており、それに慣れていないシステムや聞き手にとって理解するのが難しいかもしれません。
Dimitriは15時間のスピーチを行いコーパスとして録音しました。これはベースモデルを彼のスピーチに特有のニュアンスに適応させるために使用されました。このコーパスを用いて学習したParrotronシステムは、彼が他の人々やGoogleのASRシステムにより良く意思を伝達する事を助けました。
Parrotronの出力でGoogleのASRエンジンによる音声認識を実行したところ、Dimitriのテストセットによれば、単語誤り率は89%から32%に大幅に減少しました。以下は、ParrotronがDimitriからの入力音声を正しく変換した例です。
Dimitri「How far is the Moon from the Earth?」
Parrotron(男性版)の発声「How far are the Moon from the Earth?」
私達はまた、Google社員であり、体の動作に困難を持つ人々の社会参加を提唱しており、自らも筋ジストロフィー(進行性の筋力低下を伴い、時には発話にも影響を与える病気)であるAubrie Leeと協力しました。
Aubrieは1.5時間のスピーチを提供しました。これは、このspeech-to-speech技術の適応力が有望である事を示すのに役立ちました。 以下は、ParrotronがAubrieが入力した音声を正しく変換した例です。
Aubrie「Is morning glory a perennial plant?」
Parrotron(女性版)「Is morning glory a perennial plant?」
Aubrie「Schedule a meeting with John on Friday.」
Parrotron(女性版)「Schedule a meeting with John on Friday.」
また、ALSの患者達が提供してくれた音声データを使ってParrotronのパフォーマンスをテストしました。一人の音声データではなく、同様のスピーチ特性を共有する複数人の音声データによって事前学習モデルを学習させたのです。
私たちは予備的なリスニング検証を行いました。その結果、音声データを提供してくれたALS患者の大多数において、患者の通常の発声とParrotonモデルが出力する音声を比較すると、明りょう度が向上する事が観察されました。
3.Parrotron:発声が困難な人のために音声コミュニケーションを改善する試み(2/3)関連リンク
3)google.github.io
Audio samples from “Parrotron: An End-to-End Speech-to-Speech Conversion Model and its Applications to Hearing-Impaired Speech and Speech Separation”
4)docs.google.com
Google Project Euphonia – Interest Form
5)blog.google
How AI can improve products for people with impaired speech
6)www.als.net
ALS Research Organization | ALS Therapy Development Institute

コメント