
1.多言語化対応したユニバーサルセンテンスエンコーダーで意味検索(2/2)まとめ
・USE-QAモジュールにより質問回答検索アプリケーションも実装可能
・「香り(fragrance)」と「匂い(smell)」など単語間の意味的類似性も捕捉
・モジュールはそのまま使用することも、固有データで微調整も可能
2.多言語化対応したユニバーサルセンテンスエンコーダー
以下、ai.googleblog.comより「Multilingual Universal Sentence Encoder for Semantic Retrieval」の意訳です。元記事の投稿は、2019年7月12日、Yinfei YangさんとAmin Ahmadさんによる投稿です。
質問回答検索のためのUSE
USE-QAモジュールはUSEアーキテクチャを質問/回答検索アプリケーションに拡張します。質問/回答検索アプリケーションは、一般的に質問を入力されると、文書レベル、段落レベル、更には文レベルで索引付けされた大量の文書から関連する回答を見つけ出します。
入力された質問は質問符号化ネットワークで符号化され、回答の候補は回答符号化ネットワークで符号化されます。
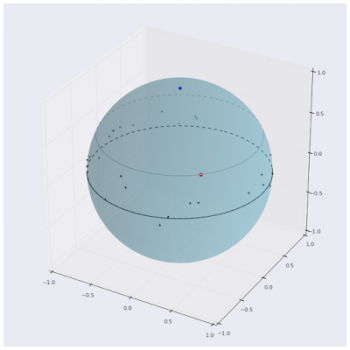
ニューラル回答検索システムの動作の視覚化。北極部の青い点は質問ベクトルを表します。他の点は様々な回答を表現しています。ここで赤で強調表示されている正解は、角距離を最小にするという点で、質問に「最も近い」ものです。この図のポイントは実際のUSE-QAモデルによって作成されたものです。ただし、読者の視覚的理解を助けるために、500次元ユークリッド空間から3次元ユークリッド空間に下方投影されています。
質問回答検索システムもまた、意味を理解する能力に依存しています。 たとえば、そのようなシステムの1つである2018年初めに開始され、10万冊以上の本に対して一文ずつ索引を付けたGoogle Talk to Booksを考えてみましょう。
「どんな香り(fragrance)」が記憶を呼び戻すのか?」という質問からは、「私にとっては、ジャスミンの匂い(smell)とパンのバニャット、それが心配する事など何もなかった子供時代を呼び覚ます」と、本から引用した結果を返します。
単語間の明示的な規則や代替規則を指定しないでも、ベクトル符号化は単語「香り(fragrance)」と「匂い(smell)」の間の意味的な類似性を捉えています。
USE-QAモジュールによって提供される利点は、このような質問回答検索タスクを多言語アプリケーションに拡張できることです。
研究者と開発者のために
Universal Sentence Encoderファミリの最新の追加情報を研究コミュニティと共有できることを嬉しく思います。また、どのようなアプリケーションがそれを用いて開発されるかを楽しみにしています。
これらのモジュールはそのまま使用することも、ドメイン固有のデータを使用して微調整することもできます。最後に、Cloud AI Workshopに自然言語ページ間のセマンティック類似性に関するワークショップを掲載しし、この分野の研究をさらに推進します。
謝辞
コアモデリングに関してMandy Guo, Daniel Cer, Noah Constant, Jax Law, Muthuraman Chidambaram、インフラとColabに関してGustavo Hernandez Abrego, Chen Chen, Mario Guajardo-Cespedes、モデルのアーキテクチャーに関する議論についてSteve Yuan, Chris Tar, Yunhsuan Sung, Brian Strope, Ray Kurzweilに感謝します。
3.多言語化対応したユニバーサルセンテンスエンコーダーで意味検索(2/2)関連リンク
1)ai.googleblog.com
Multilingual Universal Sentence Encoder for Semantic Retrieval
2)arxiv.org
Multilingual Universal Sentence Encoder for Semantic Retrieval
3)aihub.cloud.google.com
Semantic Similarity for Natural Language [AI Workshop Experiment]

コメント