
1.時系列予測に機械学習を使用する際の落とし穴(1/3)まとめ
・時系列データは様々な分野で扱う事が多いデータで機械学習でも取り扱い方をしっておくべき重要なデータ
・しかし、時間成分によて追加情報がもたらされるが、他の予測タスクより処理するのが難しい事が特徴
・時系列データにR2スコアなどの一般的なエラー率測定基準を用いる事の危険性を解説
2.機械学習で時系列データを扱う際にやってはいけない事
以下、www.kdnuggets.comより「How (not) to use Machine Learning for time series forecasting: Avoiding the pitfalls」の意訳です。元記事は2019年5月、Vegard Flovikさんによる投稿です。
時系列予測における機械学習の一般的な落とし穴のいくつかを、時間遅延予測、自己相関、定常性、精度測定基準などを中心に概説します。
時系列予測は機械学習の重要な分野です。時間成分を含む予測問題が非常に多いので、これは重要です。しかしながら、時系列問題は時間成分によって追加の情報がもたらされる一方で、他の多くの予測タスクより処理するのが難しくなります。
この記事では、機械学習を使用した時系列予測、およびいくつかの一般的な落とし穴の回避方法について説明します。
具体的な例を挙げて、どのようにして良いモデルを作成し、それを実運用するかを説明します。実のところ、モデルに予測力がまったくない場合があります。そのため、具体的にモデルの精度を評価する方法にも焦点を当てます。
平均エラー率、R2スコアなど、一般的なエラー率測定基準に単純に頼る方法を示します。慎重に適用しなければ、これらの基準は非常な誤解を招く可能性があります。
時系列予測のための機械学習モデル
時系列予測に使用できるモデルにはいくつかの種類があります。今回の具体例では、LSTM Network(Long short-term memory network)、過去のデータに基づいて予測を行う特殊な種類のニューラルネットワークを用います。
これは、言語認識、時系列分析などの分野で人気があります。しかし、私の経験では、より単純なタイプのモデルでも実際に多くの場合で同じ程度に正確な予測が得られます。ランダムフォレスト、勾配ブースティング回帰および時間遅延ニューラルネットワーク(TDNN:Time delay neural network)などのモデルを使用すると時間情報は、入力データに遅延して追加する事が出来、これによりデータが異なる時点を表現できるようにします。これらの逐次的な性質により、TDNNはリカレントニューラルネットワークではなくフィードフォワードニューラルネットワークとして実装されています。
オープンソースソフトウェアライブラリを使用してモデルを実装する方法
私は通常、ニューラルネットワークのモデルを開発する際はKerasを使用します。これは、Pythonで書かれ、TensorFlow、CNTK、またはTheanoの上で実行可能な高レベルのニューラルネットワークAPIです。
その他のタイプのモデルを開発する際は、フリーソフトウェアの機械学習ライブラリであるScikit-Learnを通常使用しています。このライブラリはサポートベクターマシン、ランダムフォレスト、グラディエントブースト、k-means、DBSCANなど、さまざまな分類、回帰、およびクラスタリングアルゴリズムを備えており、Pythonの数値および科学ライブラリNumPyおよびSciPyと相互運用するように設計されています。
ただし、この記事の主なトピックは、時系列予測モデルを実装する方法ではなく、モデル予測を評価する方法です。このため、モデル構築などの詳細については説明しません。これらのテーマについてのブログ記事や記事が他にもたくさんあるからです。
事例:時系列データの予測
今回の事例で使用するデータを下図に示します。データの詳細については後で説明しますが、現時点では、このデータが年間の株価指数の推移を表していると仮定しましょう。
データはトレーニングデータとテストデータに分割され、最初の250日がモデルのトレーニングデータとして使用されます。その後、データセットの最後の部分をテストデータとして株価指数を予測します。

この記事ではモデルの実装に焦点を当てていないので、モデルの精度を評価するプロセスに直接進みましょう。上の図を視覚的に見るだけで、実際の数値の赤線と予測の青線がピッタリと重なっています。モデルが出力した予測は実際のインデックスに厳密に従っており、正確性が高いことを示しています。
ただし、もう少し厳密にするために、下の図のように散布図で実際の値と予測値をプロットすることでモデルの精度を評価し、良く使われるエラー測定基準であるR2スコアを計算することもできます。
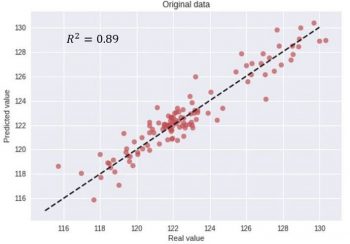
モデルの予測値から計算したR2スコアは0.89、この高いR2スコアは実際の値と予測された値との間が非常に良く一致している事を示しています。しかし、これから詳しく説明するように、この測定基準とモデルの評価は非常に大きな誤解を招く可能性があります。
3.時系列予測に機械学習を使用する際の落とし穴(1/3)関連リンク
1)www.kdnuggets.com
How (not) to use Machine Learning for time series forecasting: Avoiding the pitfalls

コメント