
1.グラフデータを機械学習で扱いやすくするための革新(3/3)まとめ
・グラフのembedding手法は有用であるが手動で設定しなければならない多数のハイパーパラメータを持つ
・第二の論文で紹介している「Watch Your Step」はハイパーパラメータを自動で調整する新手法
・「Watch Your Step」はニューラルアーキテクチャ探索は使っていないがAutoMLファミリーと見なせる
2.Watch Your Stepとは?
以下、ai.googleblog.comより「Innovations in Graph Representation Learning」の意訳です。元記事は2019年6月25日、Alessandro EpastoさんとBryan Perozziさんによる投稿です。
Attentionを介してグラフのハイパーパラメータを自動で調整
グラフのembeddingは、リンク予測やノード分類など、さまざまな機械学習ベースのアプリケーションで優れた性能を示していますが、手動で設定しなければならない多数のハイパーパラメータを持ちます。
たとえば、embeddingを学習する際、近くにあるノードは、遠くにあるノードよりもどのくらい重要と設定すべきでしょうか?グラフを専門に研究している研究者であればこれらのハイパーパラメータをチューニングすることができるかもしれませんが、そうでない人であっても各グラフに対してこういった調整をしなければなりません。このような手作業を回避するために、私達の2番目の論文では、最適なハイパーパラメータを自動的に学習する方法を提案しました。
具体的には、DeepWalkのような多くのグラフembedding手法は、ランダムウォークを使用して特定のノード周辺を探索します。(例、直接隣接するノード、隣接するノードの隣接ノードなど)
このようなランダムウォークは、グラフの局所探索のチューニングを可能にする多くのハイパーパラメータを持つことができ、このようにして、近隣ノードのembeddingによって与えられるAttentionを調整します。
異なるグラフは、異なるAttention最適化パターンを持ち、したがって異なるハイパーパラメータ最適化を持ち得ます。(下の図を見てください。ここでは、2つの異なるAttention分布が示されています)
第二の論文で紹介している「Watch Your Step」は、上記のハイパーパラメータに基づいてembeddingの性能モデルを定式化します。次に、標準的な誤差逆伝播法を使用して、ハイパーパラメーターを最適化し、モデルによって予測されるパフォーマンスを最大化します。
私達は、誤差逆伝播法によって得られた値が、グリッドサーチによって得られた最適なハイパーパラメータと一致することを見出しました。
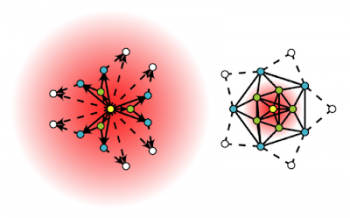
ハイパーパラメータを自動でチューニングする新手法である「Watch Your Step」では、Attentionモデルを使用してさまざまなグラフコンテキスト分布を学習します。
上に示されているのは、中心ノード(黄色)と、モデルによって学習されたコンテキスト分布(赤いグラデーション)についての2つのローカル近傍の例です。
左側のグラフは、より拡散したAttentionモデルを示していますが、右側の分布は直接隣接するノードに集中したモデルを示しています。
この作業は、機械学習の実務における一般的な問題であるハイパーパラメータ最適化に関する負担を軽減したいという、成長し続けるAutoMLファミリーの範疇に属します。
多くのAutoML手法はニューラルアーキテクチャ探索を使用しますが、本論文では少し変わった形で実現しています。私達は、「embeddingにおけるハイパーパラメータ」と「グラフ理論的行列定式化(graph-theoretic matrix formulations)」の間の数学的関係を使用します。「Auto」の部分は、誤差逆伝播法によってグラフのハイパーパラメータを学習する事で対応します。
私達は私達の貢献が様々な方向へのグラフembeddingの研究の状況をさらに前進させると信じています。複数のノードembeddingを学習する私達の方法は、重複コミュニティ検出などの事例豊富でよく研究されている分野との関連性を引き出します。そして私達が信じる直近のグラフembeddingの進歩は将来の実りある研究をもたらすと信じています。
この分野における未解決の問題は、分類問題のために多重embeddingを使用する事です。さらに、ハイパーパラメーターの自動学習に対する私達の貢献は、手間のかかる手動調整の必要性を減らすことによってグラフembeddingの採用を促進します。これらの論文やコードの発表が、研究コミュニティがこれらの方向性を追求するのに役立つことを願っています。
謝辞
この研究に貢献し、現在はUSCのPh.D.であるSami Abu-el-Haijaに感謝します。
Graph Miningチーム(Algorithm and Optimizationチームの一部)の詳細については、当社のページを参照してください。
3.グラフデータを機械学習で扱いやすくするための革新(3/3)関連リンク
1)ai.googleblog.com
Innovations in Graph Representation Learning
2)arxiv.org
Is a Single Embedding Enough? Learning Node Representations that Capture Multiple Social Contexts
3)papers.nips.cc
Watch Your Step:Learning Node Embeddings via Graph Attention(PDF)
4)github.com
google-research/graph_embedding/
5)ai.google
Graph Mining

コメント