
1.SpecAugment:音声認識のために学習データを水増しする(1/2)まとめ
・SpecAugmentにより学習データの追加でパラメータ等を変更せずともネットワークの性能向上が可能
・またSpecAugmentは故意に破損したデータを与えることによってネットワークの過学習を抑止する
・今回の研究により良い訓練方法を見つけてネットワークを訓練する研究が有望である事が示された
2.SpecAugmentとは?
以下、ai.googleblog.comより「SpecAugment: A New Data Augmentation Method for Automatic Speech Recognition」の意訳です。元記事は2019年4月22日、Daniel S. Park,さんとWilliam Chanさんによる投稿です。
SpecAugmentをテストするために、LibriSpeechデータセットを使用していくつかの実験を行いました。ここでは、音声認識に一般的に使用されるListen Attend and Spell(LAS)ネットワークを使用して2パターンの比較を行いました。ASRネットワークのパフォーマンスは、読み上げられる台本に対する音声認識ネットワークによって生成された台本の単語エラー率(WER:Word Error Rate)によって測定されます。
ここでは、全てのハイパーパラメータは同じに保たれ、ネットワークが使う学習用データだけが変更されました。その結果、SpecAugmentは、ネットワークやトレーニングパラメータを追加調整することなくネットワークパフォーマンスを向上させることがわかりました。
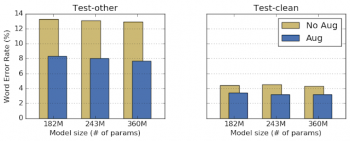
水増し増強の有(Aug)無(No Aug)によるLibriSpeechのネットワークの性能比較。 LibriSpeechは、Test-cleanとTest-otherの2つのデータセットでテストされました。後者のTest-otherには、ノイズの多い音声データが含まれています。
さらに重要なことに、SpecAugmentは故意に破損したデータを与えることによってネットワークが過学習する事を防ぎます。この例として、トレーニングセットと開発セットのWERが、データ水増しの有無によってどのように進化するかを以下に示します。
水増しなしでは、ネットワークはトレーニングセットでほぼ完璧なパフォーマンスを達成しながら、クリーンな開発セットとノイズの多い開発セットの両方で大幅にパフォーマンスが低下していることがわかります。
一方、水増しを行ったデータを使うと、ネットワークはトレーニングセットでは学習に苦労しますが、クリーンな開発セットではより良いパフォーマンスを示し、ノイズのある開発セットでも同等のパフォーマンスを示します。
これは、ネットワークがトレーニングデータに過剰に適合しなくなったこと、およびトレーニングパフォーマンスの向上がテストパフォーマンスの向上につながることを示唆しています。
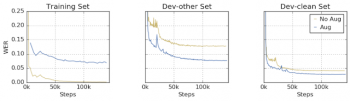
トレーニングデータセット、クリーンな開発データセット(dev-clean)およびノイズの多い開発データセット(dev-other)のデータ水増し有(Aug青線)無(No Aug黄色)の比較
最先端のスコア(State-of-the-Art Results)
以上の議論により、私達はトレーニングパフォーマンスの向上に焦点を当てることができます。これは、ネットワークをより大きくし、ネットワークのキャパシティを増やすことで実現できます。
これをトレーニング時間の増加と組み合わせて行うことで、LibriSpeech 960hおよびSwitchboard 300hのタスクに関する最先端の結果を得ることができました。

LibriSpeech 960hおよびSwitchboard 300hのタスクのワードエラー率(WER%)の比較。
両方のテストセットに、クリーン(clean/Switchboard)なデータとノイズが多い(other/CallHome)データを用意しました。比較対象とした従来の最先端のスコアは2019年のLi等、2018年のYang等、2018年のZeyer等によるスコアです。
我々が使用した単純な水増しスキームは驚くほど強力です。エンドツーエンドのLASネットワークは、従来のLibriSpeechやSwitchboardなどの小規模な学術データセットでは従来のASRモデルよりもはるかに優れたパフォーマンスを発揮することができます。
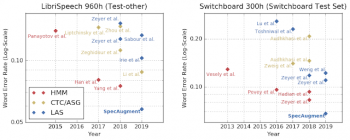
LibriSpeechおよびSwitchboardタスクに関する様々なネットワークのパフォーマンス比較。LASモデルの性能は、古典的モデル(例えば、HMM)および他のエンドツーエンドモデル例えば、(CTC/ASG)と比較する事ができます。
言語モデル(Language Models)
言語モデル、略してLMはテキストデータのみからなる大きな言語資料を使ってトレーニングされたモデルです。LMはテキストから得られた情報を活用することによってASRネットワークのパフォーマンスを向上させる上で重要な役割を果たしてきました。
ただし、LMは通常、ASRネットワークとは別にトレーニングする必要があり、使用するメモリの量も非常に大きくなる可能性があるため、スマートフォンなどの小型デバイスには適しません。私たちの研究の予想外の結果は、SpecAugmentを使って訓練されたモデルは、言語モデルの助けを借りなくても、以前の手法で達成された全てスコアを上回ったということでした。
私たちのネットワークはまだLMを追加する事で恩恵を受けますが、私たちの研究結果はLMの助けを借りずとも実用レベルの使用に耐えるネットワークを生み出せる可能性を示唆しており、励みになります。
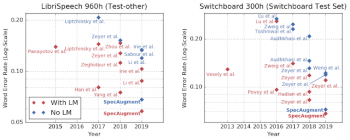
LMの有無で比較したLibriSpeechおよびSwitchboardタスクのワードエラー率。SpecAugmentは、言語モデルを使わずとも従来の最先端技術よりも優れています。
これまでのASRに関する作業の大部分は、より良いネットワーク構造を見つけて訓練することに焦点が当てられていました。私たちの研究は、良い訓練方法を見つけてネットワークを訓練する事が新たな研究分野として有望である事を示しています。
謝辞
私たちの論文の共著者である、Chung-Cheng Chiu, Ekin Dogus Cubuk, Quoc Le, Yu Zhang,そしてBarret Zophに感謝します。また、有意義な議論を提供してくれたYuan Cao, Ciprian Chelba, Kazuki Irie, Ye Jia, Anjuli Kannan, Patrick Nguyen, Vijay Peddinti, Rohit Prabhavalkar, Yonghui Wu and Shuyuan Zhangにも感謝します。
3.SpecAugment:音声認識のために学習データを水増しする(2/2)関連リンク
1)ai.googleblog.com
SpecAugment: A New Data Augmentation Method for Automatic Speech Recognition
2)arxiv.org
SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition

コメント