
1.MorphNet:学習済みニューラルネットワークをより速くより小さく改良(2/2)まとめ
・MorphNetは圧縮対象をサイズや計算量などから選べる事に加えて3つの重要な特徴がある
・ネットワークの構造そのものを変更する事がある、大規模なネットワークに直接適用が可能
・元のネットワークが固有の学習ステップで学習する必要があってもMorphNetは影響を受けない
2.MorphNetの強み
以下、ai.googleblog.comより「MorphNet: Towards Faster and Smaller Neural Networks」の意訳です。元記事は2019年4月17日、Andrew PoonさんとDhyanesh Narayananさんによる投稿です。
何故MorphNetなのか?
MorphNetが提供する4つの重要な価値は以下です
1)Targeted Regularization
MorphNetが正規化で用いるアプローチは、他のsparsifying regularizers手法よりも目的を持って実行する事ができます。MorphNetのアプローチは、特定のリソース(計算機資源やモデルサイズなど)の削減を目的とする事ができるのです。
これは、MorphNetにより誘発されるネットワーク構造最適化の方向性の制御を可能にします。そして、アプリケーションや適用分野で大きく異なる固有の制約を満たすために最適化する事ができます。
例えば、以下では左図はJFTデータセットでトレーニングした一般的なResNet-101アーキテクチャを使用した基準となるネットワークを示しています。FLOP(中央図:40%計算量を削減)、つまり計算量をターゲットにしたときにMorphNetによって生成された構造と、モデルサイズ(右図:43%重みを削減)をターゲットにした時では劇的に構造が異なります。
計算コストを最適化するとき、ネットワーク下層の高解像度を扱うニューロンは、上層の低解像度を扱うニューロンよりも大きく削減される傾向があります。モデルサイズに最適化する時、この傾向は逆になります。
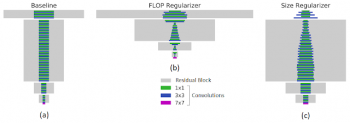
MorphNetによるターゲット正則化。長方形の幅は、レイヤー内のチャンネル数を表しています。下部の紫色のバーは入力レイヤーの数です。左図:MorphNetへの入力として使われる基準となるネットワーク。中央:FLOP最適化を適用した出力。右図:サイズ最適化を適用した出力
MorphNetは、特定のパラメータを最適化の対象とすることができる数少ない利用可能なソリューションの1つとして際立っています。これにより、特定の実装のパラメータをターゲットに最適化することができます。例えば、対象となる装置に固有の計算時間およびメモリ操作時間をパラメータに組み込むことによって、反応速度を優先する最適化を行う事ができます。
2)Topology Morphing
MorphNetがレイヤーあたりのニューロン数を学習した結果、アルゴリズムがレイヤー内の全てのニューロンを削減するという特殊なケースに遭遇する場合があります。層にニューロンが存在しない時、MorphNetは、これをネットワークから切り離すことによってネットワークのトポロジー(訳注:ネットワークの形状)を効果的に変更します。
たとえば、ResNetアーキテクチャの場合、MorphNetはスキップ接続を維持しながら、以下に示すように残差ブロックを削除することがあります(左)。Inceptionスタイルのアーキテクチャでは、MorphNetは右に示すように並列タワー全体を削除することがあります。
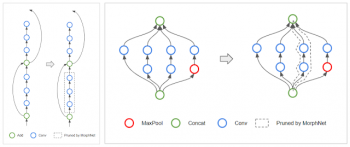
左:MorphNetはResNetスタイルのネットワークで残差ブロックを削除することができます。
右:インセプションスタイルのネットワークでは、並列タワーを削除することもできます。
3)Scalability
MorphNetは1回のトレーニングで新しい構造を学習します。トレーニング予算が限られている場合は、これが優れたアプローチです。MorphNetは高価なネットワークやデータセットに直接適用することもできます。たとえば、前述の例では、MorphNetはResNet-101に直接適用されました。このResNet-101は、JFTデータセットを使い100個のGPUで一カ月かけてトレーニングしたものです。
4)Portability
MorphNetは、ゼロから再訓練することを目的としており、その重みはアーキテクチャの学習手順に結び付けられていないという意味で、「移植可能」なネットワークを生み出しています。チェックポイントをコピーしたり、特別なトレーニングレシピに従うことを心配する必要はありません。通常どおり新しいネットワークをトレーニングするだけです。
Morphing Networks
デモンストレーションとして、FLOPをターゲットにしてImageNetでトレーニングしたInception V2にMorphNetを適用しました(下記参照)。比較対象となるベースラインアプローチに、width multiplierで各畳み込み(赤)の出力数を均等に縮小することによって、精度とFLOPをトレードオフしていきます。
MorphNetのアプローチはFLOPを直接ターゲットにしており、モデルを縮小するとより良いトレードオフ曲線が得られます(青)。この場合、FLOPコストはベースラインと同じ精度で11%から15%減少します。
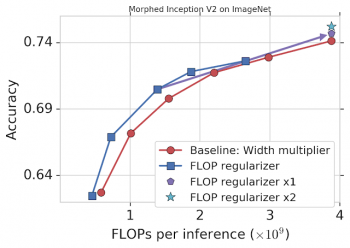
MorphNetをImageNetのInception V2に適用したグラフ。 FLOP正則化演算を単独で(青)適用すると、ベースライン(赤)に比べて11-15%パフォーマンスが向上します。正則化(圧縮)とwidth multiplier(拡大)の両方を適用するフルサイクルでは、同じコスト(“x1”:紫色)で精度が向上し、2回目のサイクル(“x2”:明るい水色)でも継続的に改善されます。
この時点で、あなたはより小さなFLOP制限を満たすためにこれ以上の最適化をストップし、MorphNetネットワークの1つを選ぶ事ができます。 あるいは、ネットワークを次は拡大して同じコスト(紫色)でより高い精度を達成し、1サイクルを完了することもできます。MorphNetの縮小/拡大サイクルをもう一度繰り返すと、精度がさらに向上し(明るい水色)、合計精度は1.1%向上します。
まとめ
Googleでは、MorphNetをいくつかの製品展開されている画像処理モデルに適用しました。 MorphNetを使用すると、品質をほとんどまたはまったく損なうことなく、モデルサイズ/ FLOPが大幅に削減されました。オープンソースのTensorFlowの実装はgithubで見つけることができます。また、MorphNetの論文で詳細を読むこともできます。
謝辞
このプロジェクトは、コアチームによる共同作業です。Elad Eban, Ariel Gordon, Max Moroz, Yair Movshovitz-Attias, そしてAndrew Poon。私達はまた私達の共同研究者、研修生、およびインターンに特別な感謝をしています。Shraman Ray Chaudhuri, Bo Chen, Edward Choi, Jesse Dodge, Yonatan Geifman, Hernan Moraldo, Ofir Nachum, Hao Wu, そしてTien-Ju Yang、彼らの本プロジェクトへの貢献に感謝します。
3.MorphNet:学習済みニューラルネットワークをより速くより小さく改良(2/2)関連リンク
1)ai.googleblog.com
MorphNet: Towards Faster and Smaller Neural Networks
2)arxiv.org
MorphNet: Fast & Simple Resource-Constrained Structure Learning of Deep Networks
3)github.com
google-research/morph-net

コメント