
1.Snorkel Drybell:既存知識を活用して機械学習用ラベル付きデータを自動作成(2/3)まとめ
・Snorkel DryBellでトレーニングデータをラベリングしたラベルは手作業のラベルより精度が低い
・しかし生成的モデリング手法を用いてground truthラベルなしでラベルの精度を向上させる事が出来る
・既存の情報源あるいはラベル付け可能な機械学習など様々な情報源をラベリング関数として利用可能
2.ground truthラベルなしでラベルの精度を高める
以下、ai.googleblog.comより「Harnessing Organizational Knowledge for Machine Learning」の意訳です。元記事の投稿は2019年3月14日、Alex RatnerさんとCassandra Xiaさんによる投稿です。
個々のデータを手作業でラベリングするよりも、Snorkel DryBellでトレーニングデータをラベリングするこのプログラムによる手法は、はるかに高速で柔軟性がありますが、手動で指定されたラベルよりも明らかに品質が劣ります。
これらのラベル付け関数によって生成されたラベルは、しばしば重なり合って矛盾します。(例えば、ある程度信頼性のあるデータとヒューリスティックな大体合ってるデータを混在させるなど)
ノイズの多いラベルの問題を解決するために、Snorkel DryBellは生成的モデリング手法を使用して、ラベル付け関数の正確さと相関を明確に一貫した方法で自動的に推定します。真の正解(ground truth)ラベルなしでこれを行うのです。そして、これを使用して、データポイントごとに出力を重み付けし、それらの出力を単一の確率的ラベルに結合します。各ラベリング関数のラベル付けの一致と不一致を利用し、新しい行列補完アプローチを使用して、出力を最もよく説明するラベリング関数の精度と相関パラメータを学習します。結果のラベルは、以下のシステム図に示すように、任意のモデルを訓練するために(例えばTensorFlowで)使用することができます。
(訳注:要は正解となるラベルがなくても、複数のラベル付け関数の出力を比較すると、最も確からしいラベルがわかって、それがそこそこ使えるレベルのラベルになるって事ですね)
弱い教師(Weak Supervision)としての多様な知識源の利用
Snorkel Drybellの有効性を調べるために、Webコンテンツ内のトピックの分類、特定の製品に関する言及の特定、および特定のリアルタイムイベントの検出を目的とした、3つのタスクと対応するデータセットを使用しました。Snorkel DryBellを使うと、私たちは以下のような既存の情報源、あるいは迅速にラベリングが可能な様々な情報源をラベリング関数として利用する事ができました。
・ヒューリスティックなルール
例:人が作成した特定分野に関する既存の規則
・トピックモデル、タグ付け、および分類子
例:特定分野または関連分野を分類する機械学習モデル
・集計統計
例:特定分野に関する追跡指標
・知識グラフまたはエンティティグラフ
例:特定分野に関する事実のデータベース
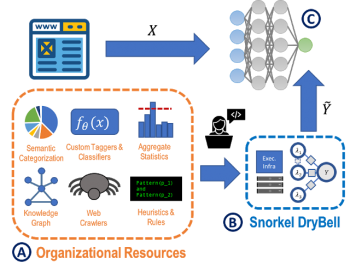
Snorkel DryBellの目標は、たとえばWebデータでコンテンツまたはイベントの分類を行うために、機械学習モデル(C)を訓練することです。これを行うためにトレーニングデータを手作業でラベリングするのではなく、Snorkel DryBellでは、ユーザーはさまざまな既存のナレッジリソースを表現するラベリング関数を作成し(A)、自動的に再重み付けして結合します(B)。
3.Snorkel Drybell:既存知識を活用して機械学習用ラベル付きデータを自動作成(2/3)関連リンク
1)ai.googleblog.com
Harnessing Organizational Knowledge for Machine Learning
2)hazyresearch.github.io
Snorkel: A System for Fast Training Data Creation

コメント