
1.機械学習で自撮りにリアルタイムに拡張現実を適用(2/3)まとめ
・TensorFlow LiteとGPUバックエンドアクセラレーションでパフォーマンス向上と消費電力削減を達成
・パフォーマンスと効率特性を変えた様々なモデルアーキテクチャを設計しサブサンプリングレートも調整
・その結果、最も複雑なモデルと軽量モデルの差がほとんどわからないレベルの効率化を達成
2.機械学習とAR
以下、ai.googleblog.comより「Real-Time AR Self-Expression with Machine Learning」の意訳です。元記事の投稿は2019年3月8日、Artsiom AblavatskiさんとIvan Grishchenkoさんによる投稿です。
3Dメッシュのために私達は転移学習を使い、いくつかの目的のためにネットワークを訓練しました。
ネットワークは、三次元の合成メッシュ座標とレンダリングデータ、注釈付きの二次元輪郭データを同時に予測します。これはMLKitが提供するのと同等の現実世界のデータです。結果として得られるネットワークは、合成だけでなく実世界のデータについても合理的な3Dメッシュ予測を提供してくれました。全てのモデルは、地理的人種的に多様なデータセットから得られたデータに基づいて訓練され、その後、定性的および定量的なパフォーマンスについて、バランスのとれた多様なテストセットでテストされます。
三次元メッシュネットワークは入力として切り抜いたビデオフレームを使用します。奥行情報を追加で必要としないため、事前に録画されたビデオにも適用できます。モデルは、3Dポイントの位置、および入力データ内に顔が存在し位置が間違っていない確率を出力します。
一般的な代替アプローチは、各目印について二次元ヒートマップを予測する事ですが、これは奥行情報の予測には適しておらず、非常に多くの点で高い計算コストを必要とします。
私達はその代わりに、反復的にブートストラップ(統計的推論)して予測を改良することにより、モデルの精度と堅牢性をさらに向上させました。こうすることで、データセットを、しかめっ面、斜めからのアングル、オクルージョン(重なり具合)など、より困難なケースに拡大することができます。
データセット拡張技術はまた、利用可能な真のデータを水増しし、カメラの不完全性や極端な照明条件などの人為的効果に対するモデルの回復力を高めます。
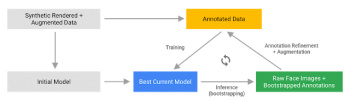
データセットの拡張と改善のパイプライン
ハードウェアに合わせた推論
私達はデバイス上でのニューラルネットワーク推論のためにTensorFlow Liteを使用しています。新しく導入されたGPUバックエンドアクセラレーションは、可能であればパフォーマンスを向上させ、消費電力を大幅に削減します。さらに、一般消費者用ハードウェアを幅広くカバーするために、パフォーマンスと効率特性を変えた様々なモデルアーキテクチャを設計しました。
より軽量のネットワークの最も重要な違いは、残差ブロックのレイアウトと許容される入力解像度(最も軽量のモデルでは128×128ピクセル、最も複雑なモデルでは256×256ピクセル)です。
また、レイヤ数とサブサンプリングレート(入力解像度がネットワークの深さに応じてどれくらい速く低下するか)も変化させます。
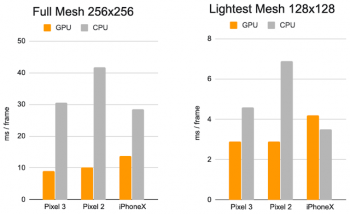
フレームあたりの推論時間:CPU vs. GPU
これらの最適化の結果、AR効果の品質低下を最小限に抑えながら、軽量のモデルを使用することによって大幅なスピードアップが実現できました。
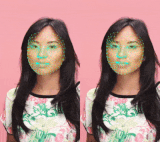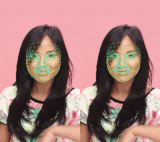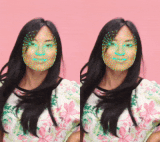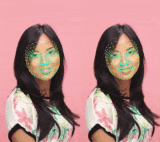
最も複雑なモデル(左)と最も軽いモデル(右)の比較。 軽いモデルでは、唇と目の追跡だけでなく時間的な一貫性もわずかに低下します。
3.機械学習で自撮りにリアルタイムに拡張現実を適用(2/3)関連リンク
1)ai.googleblog.com
Real-Time AR Self-Expression with Machine Learning
2)firebase.google.com
ML Kit の顔検出機能の説明

コメント