
1.GPT-2:より良い言語モデルとそれが暗示する事(2/3)まとめ
・GPT-2はWinograd Schema、LAMBADA、およびその他の言語モデリング用タスクで最先端のスコアを達成
・質問回答、読解力、要約、翻訳などの他の言語タスクでもチューニングなしに素晴らしいスコアを出した
・他の言語タスクのスコアは現状、最先端の専用モデルには敵わないが今後の改良で向上する可能性がある
2.GPT-2の性能
以下、blog.openai.comより「Better Language Models and Their Implications」の意訳です。元記事は2019年2月14日、ALEC RADFORDさん、JEFF WUさん、DARIO AMODEIさん、DANIELA AMODEIさん、JACK CLARKさん、MILES BRUNDAGEさんとILYA SUTSKEVERさんによる投稿です。数日前からAI関連ニュースとしてかなり話題になっているGPT-2を開発元であるOpenAIが紹介した記事です。前編はこちら。後編はこちら。
前述のサンプルが示すように、私たちのモデルは、様々な入力文を元に人間が作成した文章の品質に近い一貫性のある文章を1ページ以上にわたって作成する事ができます。しかし、私達は、文章の繰り返しや間違った世界モデル(例えば、水中で起きた火災についての文章など)、および不自然な話題の切り替えなど、さまざまな失敗も観察しました。言語モデルが持つこの種の弱点を探ることは、自然言語処理業界で活発に研究されている分野です。
全体的に見て、良い文章を得るには数回の試行が必要ですが、試行回数はモデルが文脈にどの程度精通しているかによって異なります。データ内で非常によく現れるトピック、Brexit(イギリスのEU脱退を意味する造語)、Miley Cyrus(マイリー・サイラス、アメリカの人気女性歌手)、Lord of the Rings(指輪物語、映画にもなったファンタジー小説)などを使用して最初の文章を作成して与えると、約50%の確率でもっともらしい文章を生成できるようです。逆もまた真です。高度に技術的または難解な種類のコンテンツでは、モデルのパフォーマンスが低下する可能性があります。
微調整を行うと、生成されたサンプルをさらに詳細に制御できる可能性があります。たとえば、Amazon ReviewsデータセットでGPT-2を微調整して、星の評価やカテゴリなどの条件に基づいてレビューを書くことができます。
これらの事例は、現実世界に大きな影響を与えます。大規模言語モデルは、スケーラブルでカスタマイズされた一貫性のあるテキスト生成を行うように軌道修正する事がますます容易になってきています。これは、悪意のある方法と同様に多くの有益な方法で使用できる可能性があります。これらの影響を以下でさらに詳しく説明し、この状況を考慮しながら私達が行っている実験について概説します。
ゼロショット
GPT-2は、さまざまな分野固有の言語モデリングタスクで最先端のスコアを達成します。GPT-2は、これらの多様なタスクのいずれにおいても分野固有のデータを使って訓練されておらず、そのままテスト及び評価されているだけです。 これは「ゼロショット」セッティングとして知られています。
GPT-2は、特定分野固有のデータセット(ウィキペディア、ニュース、書籍など)でトレーニングされたモデルより、優れたパフォーマンスを出す事ができます。もし、その試験がその分野固有のデータセットを用いた試験であってもです。以下に、最新のゼロショット試験の結果を全て表示します。
(+)記号はその試験では数字が大きいほうが良いスコアである事を示します。(-)記号は数字が小さいほうが良いスコアである事を意味しています。
| データセット名 | 基準 | GPT-2のスコア | 以前のハイスコア | 人間のスコア |
| Winograd Schema Challenge | 正確性(+) | 70.70% | 63.70% | 92%+ |
| LAMBADA | 正確性(+) | 63.24% | 59.23% | 95%+ |
| LAMBADA | 単語絞り込み性能(-) | 8.6 | 99 | ~1-2 |
| Children’s Book Test Common Nouns(validation accuracy) | 正確性(+) | 93.30% | 85.70% | 96% |
| Children’s Book Test Named Entities(validation accuracy) | 正確性(+) | 89.05% | 82.30% | 92% |
| Penn Tree Bank | 単語絞り込み性能(-) | 35.76 | 46.54 | unknown |
| WikiText-2 | 単語絞り込み性能(-) | 18.34 | 39.14 | unknown |
| enwik8 | 文字絞り込み性能(-) | 0.93 | 0.99 | unknown |
| text8 | 文字絞り込み性能(-) | 0.98 | 1.08 | unknown |
| WikiText-103 | 単語絞り込み性能(-) | 17.48 | 18.3 | unknown |
GPT-2は、Winograd Schema、LAMBADA、およびその他の言語モデリング用タスクで最先端のスコアを達成しました。
質問回答、読解力、要約、翻訳などの他の言語タスクでは、訓練済モデルを正しく指示するだけで、モデルを微調整することなく驚くべき結果を得ることができました。(以下の例を参照)とはいえ、我々はまだそれぞれのタスクに特化した専用システムの最先端のスコアには及びません。
読解力試験:与えられた例文についての設問に答える
データセット:CoQA
例文:
2008年夏季オリンピックの聖火リレーは、2008年夏季オリンピックに先立ち、2008年3月24日から8月8日まで開催され、「ひとつの世界、ひとつの夢」をテーマにしていました。リレーの計画は2007年4月26日に中国の北京で発表されました。主催者によって「調和の旅」とも呼ばれていたこのリレーは、129日間続き、聖火を137,000km(85,000マイル)運びました。これは伝統が1936年の夏季オリンピック前に始まって以来、どんなオリンピックの聖火リレーよりも長い距離です。
3月24日にオリンピックの発祥の地であるギリシャのオリンピアで着火された後、聖火はアテネのPanathinaikoスタジアムに旅をし、そして3月31日に北京に到着しました。北京から、聖火は6つの大陸を通るルートをたどっていきました。聖火はシルクロード沿いの都市を訪れました。これは中国と世界の他の地域との古代のつながりを象徴しています。このリレーには、中国側からネパールとチベットの国境にあるエベレスト山の頂上への炎を上らせる事も含まれていました。
設問
Q1:テーマは何ですか?
A1:「ひとつの世界、ひとつの夢」
Q2:レースの長さはいくつですか?
A2:「137,000km」
Q3:以前のものより大きかったですか?
A3:「いいえ」
Q4:どこからレースは始まりましたか?
A4:「ギリシャのオリンピア」
Q5:彼らは次にどこに行きましたか?
A5:「アテネ」
Q6:レースは何日でしたか?
A6:「7」
Q7:彼らは注目すべきランドマークを訪問しましたか?
A7:「Panathinaikoスタジアム」
Q8:そして彼らは山を登ったのですか?
A8:「エベレスト」
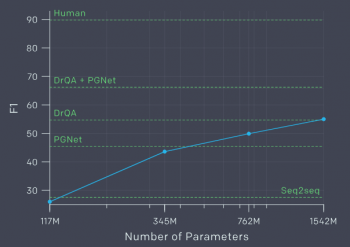
これらのタスクは一般的な言語モデリングのサブセットであるため、計算量やデータが増えるにつれてパフォーマンスがさらに向上すると私達は予想しています。他の人たちも同様の仮説を発表しています。私達は、徹底的な実験で確かめたわけではありませんが、細かい調整がこれらのタスクのパフォーマンスを向上する事を期待しています。
(GPT-2:より良い言語モデルとそれが暗示する事(1/3)からの続きです)
(GPT-2:より良い言語モデルとそれが暗示する事(3/3)に続きます)
3.GPT-2:より良い言語モデルとそれが暗示する事(2/3)関連リンク
1)blog.openai.com
Better Language Models and Their Implications

訳注:分野Aでニューラルネットワークを学習させた後に分野Bでそのニューラルネットワークを使う(つまり転移学習)際に、分野Bのデータで一回も学習させていない事をzero-shotと言います。一回学習させるとone-shot、N回学習させるとN-shot、と呼称が変わります。日本語で言えば「初見」です。