
1.FastText:テキストデータの特徴量抽出の実装(1/2)まとめ
・FastTextは2016年にFacebookによって最初に発表された素のWord2Vecモデルを拡張および改善したもの
・各単語をBag of Character n-gram(サブワードモデル)とみなしてベクトル化する
・計算量は多くなるがサブワードモデルのおかげで珍しい単語が出現しても対応できる可能性が高い
2.FastTextとは?
以下、www.kdnuggets.comより「Implementing Deep Learning Methods and Feature Engineering for Text Data: FastText」の意訳です。元記事の投稿は2018年5月、Dipanjan Sarkarさんによる投稿です。まだ一年もたっていませんが、BERTやELMOの出現により過去のテクニックになりつつあるのかもしれませんけれども押さえておきたいと思ったので。後編はこちら
全体の要約:FastTextは単語特徴表現を学習し、堅牢で高速かつ正確なテキスト分類を実行するためのフレームワークです。このフレームワークはFacebookによってGitHub上でオープンソース化されています。
本投稿はtowardsdatascience.comの「Understanding Feature Engineering (Part 4) – A hands-on intuitive approach to Deep Learning Methods for Text Data – Word2Vec, GloVe and FastText」の抜粋です。元文章にはより詳しい内容が含まれています。
The FastText Modelとは?
FastTextは、2016年にFacebookによって最初に発表され、素のWord2Vecモデルを拡張および改善したものと考えられています。Mikolovらによる論文「Enriching Word Vectors with Subword Information」は、このFastTextがどのように機能するのかを深く理解するための優れた読み物です。論文の主旨は「FastTextは単語特徴表現を学習し、堅牢で高速かつ正確なテキスト分類を実行するためのフレームワークです。このフレームワークはFacebookによってGitHub上でオープンソース化されています。」であり、FastTextには以下の機能が含まれています。
・最先端の英語単語ベクトル
・WikipediaおよびCrawlで訓練された157の言語のための単語ベクトル
・言語識別のモデルとさまざまな教師付き学習用タスク
私は研究論文に基づいてこのFastTextモデルをゼロから実装した事はありませんが、以下は、モデルがどのように機能するかについて私が学んだ事です。
一般に、Word2Vecモデルのような予測モデルは、通常、各単語を別個の概念(例えば、where)と見なし、その単語に対する密なembeddingを生成します。しかし、これは、語彙が非常に多く、学習に使用する言語資料(コーパス)にも滅多に使われない可能性が高い珍しい単語を多く持つ言語では、深刻な制限となります。
Word2Vecモデルは通常、各単語の形態的構造を無視し、単語を単一のエンティティと見なします。FastTextモデルは、各単語をBag of Character n-gramと見なします。本稿ではこれをサブワードモデルと呼びます。
単語の最初と最後に特別な境界記号<and>を追加します。 これにより、接頭語と接尾語を他の文字と区別することができます。我々はまた、各単語の特徴表現を学習するために、単語wそのものを「Character n-gram(文字ベースのn-gram)」とともにそのn-gramsに加えます。
単語<where>、そしてn=3の(tri-gram)の事例で解説します。Whereは文字ベースのn-gramでは<wh>、<whe>、<her>、<ere>、<re>と単語全体を表す特別なシーケンス<where>となります。単語<her>に対応するシーケンスは、単語whereのtri-gramの<her>とは異なることに注意してください。実際には、この論文ではn>=3とn<=6に対応する全てのn-gramを抽出することを推奨しています。これは非常に単純なアプローチなので、例えば、全ての接頭語と接尾語を取り除くなど、様々な異なったn-gramのセットを検討する事ができるでしょう。
通常、単語の各n-gramにベクトル表現(embedding)を関連付けます。つまり、単語をそのn-gramのベクトル表現の合計、またはn-gramのembeddingの平均で表すことができます。個々の単語からn-gramを得ている文字ベースのn-gramは、他のコーパスで同じ単語が出現した際に同じ表現になるはずなので、珍しい単語が適切なベクトル表現を得る可能性が高くなります。
機械学習タスクへのFastText機能の適用
gensimパッケージはgensim.models.fasttextモジュールでFastTextモデルを利用可能にする素敵なインターフェースを持っています。もう一度これを私たちの聖書コーパスに当てはめて、私たちの興味のある言葉とその最も類似した言葉を見てみましょう。
訳注:以下、元記事は一連のシリーズの抜粋なので、聖書コーパス等が既に作られてる前提のコードだったので、Colabでそのまま動かせるようにimport文等を補足してあります。
# original
# https://towardsdatascience.com/understanding-feature-engineering-part-4-deep-learning-methods-for-text-data-96c44370bbfa
# Fixed to copy and run on Colab
import nltk
import numpy as np
import re
from gensim.models.fasttext import FastText
from nltk.corpus import gutenberg
from string import punctuation
nltk.download('gutenberg')
nltk.download('punkt')
nltk.download('stopwords')
def normalize_document(doc):
# lower case and remove special characters\whitespaces
doc = re.sub(r'[^a-zA-Z\s]', '', doc, re.I|re.A)
doc = doc.lower()
doc = doc.strip()
# tokenize document
tokens = wpt.tokenize(doc)
# filter stopwords out of document
filtered_tokens = [token for token in tokens if token not in stop_words]
# re-create document from filtered tokens
doc = ' '.join(filtered_tokens)
return doc
wpt = nltk.WordPunctTokenizer()
stop_words = nltk.corpus.stopwords.words('english')
bible = gutenberg.sents('bible-kjv.txt')
remove_terms = punctuation + '0123456789'
normalize_corpus = np.vectorize(normalize_document)
norm_bible = [[word.lower() for word in sent if word not in remove_terms] for sent in bible]
norm_bible = [' '.join(tok_sent) for tok_sent in norm_bible]
norm_bible = filter(None, normalize_corpus(norm_bible))
norm_bible = [tok_sent for tok_sent in norm_bible if len(tok_sent.split()) > 2]
wpt = nltk.WordPunctTokenizer()
tokenized_corpus = [wpt.tokenize(document) for document in norm_bible]
# Set values for various parameters
feature_size = 100 # Word vector dimensionality
window_context = 50 # Context window size
min_word_count = 5 # Minimum word count
sample = 1e-3 # Downsample setting for frequent words
# sg decides whether to use the skip-gram model (1) or CBOW (0)
ft_model = FastText(tokenized_corpus, size=feature_size, window=window_context,
min_count=min_word_count,sample=sample, sg=1, iter=50)
# view similar words based on gensim's FastText model
similar_words = {search_term: [item[0] for item in ft_model.wv.most_similar([search_term], topn=5)]
for search_term in ['god', 'jesus', 'noah', 'egypt', 'john', 'gospel', 'moses','famine']}
similar_words
結果:

私たちのWord2Vecモデルの結果と多くの類似点があります。 興味深い関連付けや類似点も気づきましたか?
注:このモデルは沢山の計算が必要になります。各単語についてnグラムを考慮するため、通常はskip-gramモデルと比較して時間がかかります。これは、GPUまたは優れたCPUを使用して訓練した方がうまく機能します。私はこれをAWS p2.xインスタンスでトレーニングしましたが、通常のシステムでは2~3時間以上かかるのに対し、約10分で実行できました。
(訳注:p2.xlargeはオレゴン州価格で0.900USD/hなので10分だと20円程度でしょうか。Corabでも20分弱経過後に確認したら終わってました)
ここで、主成分分析(PCA)を使用して、embeddingの次元を2次元に減らし、それを視覚化してみましょう。
from sklearn.decomposition import PCA import matplotlib.pyplot as plt words = sum([[k] + v for k, v in similar_words.items()], []) wvs = ft_model.wv[words] pca = PCA(n_components=2) np.set_printoptions(suppress=True) P = pca.fit_transform(wvs) labels = words plt.figure(figsize=(18, 10)) plt.scatter(P[:, 0], P[:, 1], c='lightgreen', edgecolors='g') for label, x, y in zip(labels, P[:, 0], P[:, 1]): plt.annotate(label, xy=(x+0.06, y+0.03), xytext=(0, 0), textcoords='offset points')
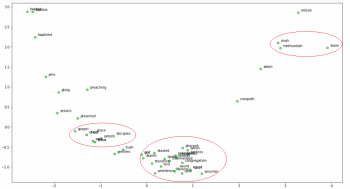
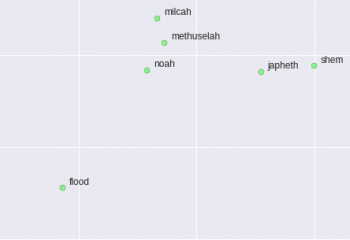
私たちはたくさんの面白いパターンを見ることができます! ノア、彼の息子シェムと祖父メトセラは互いに近い位置にいます。(右上の赤丸部分、noahはflood、つまり洪水にも近い)
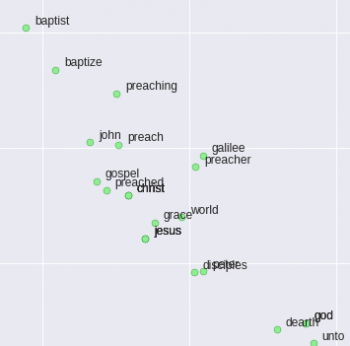
また、神がモーセとエジプトに関連付けられていて、エジプトは飢饉や疫病など聖書が記す疫病に耐えています。(中央下の赤丸、famine(飢饉)、pestilence(疫病)が近い)

また、イエスと彼の弟子の何人かは互いに親密な関係にあります。(左の赤丸、意外な事にgodはjesusとegyptの中間位に位置する)
(FastText:テキストデータの特徴量抽出の実装(2/2)に続きます)
3.FastText:テキストデータの特徴量抽出の実装(1/2)関連リンク
1)www.kdnuggets.com
Implementing Deep Learning Methods and Feature Engineering for Text Data: FastText
2)towardsdatascience.com
Understanding Feature Engineering (Part 4) – A hands-on intuitive approach to Deep Learning Methods for Text Data – Word2Vec, GloVe and FastText


コメント