
1.人工知能を創造するために生物の知能の仕組みを探求する試み(3/6)まとめ
・脳は機能的にも解剖学的にもモジュールとして分離した構造になっている
・現在のAIは平坦な構造であるため脳同等機能を実現するには不適かもしれない
・人工的知能と生物学的知能には学習に必要なデータ数についても違いがある
2.脳の構造からAIの手がかりを得る
以下、hai.stanford.eduより「The intertwined quest for understanding biological intelligence and creating artificial intelligence」の意訳です。元記事は2018年12月5日、Surya Ganguliさんによる投稿です。脳科学の用語が頻出しますが、わからない単語は読み飛ばしてしまう事を推奨です。読み難い部分は私の実力不足です。(2/6)からの続きです。(4/6)に続きます。
脳の構造がシステムレベルでモジュールに分離している事から手がかりを得る
多くの場合、現在の商用AIシステムは、ランダムな重みを与えられた白紙状態から始めて、比較的均質な層状または反復アーキテクチャを有するネットワークをトレーニングしていきます。しかしながら、このやり方でより複雑なタスクを解決する事はあまりにも難しいです。そして、確かに生物学的進化はこれと非常に異なった道をたどっています。
すべての脊椎動物の最後の共通の祖先は5億年前に存在しました。その初歩的な脳はそれ以来進化し続けており、約1億年前に哺乳類の脳、そして数百万年前に人間の脳に進化しました。この途切れない進化の連鎖は、高度に保たれた計算要素と、計り知れないシステムレベルのモジュール性を持つ複雑な脳構造をもたらしました。
実際、5億年の間に劇的に変化する環境に適応しつつ、脳は、複雑な感知、通信、制御、およびメモリネットワーク機能の規模と複雑さを継続的に拡大してきています。これがどのようにして実現されたか説明できるエンジニアリング的な設計原則は現在ありません。そのため、AIが脳のシステムレベルの構造から手がかりを得ることは非常に興味深い事になるかもしれません。
脳の重要な特性の1つは、機能的レベルと解剖学的レベルの両方におけるモジュール性です。脳は私たちの現在のAIアーキテクチャのように均質ではありません。海馬(エピソード記憶とナビゲーションの根底)、大脳基底核(強化学習と行動選択の根底)、そして小脳(教師あり学習を通じて熟練した運動制御とより高度な認識を自動化すると考えられている)のように個々に役割分担しているのです。
さらに、人間の脳の記憶システム(習慣的記憶、運動能力、短期記憶、長期記憶、エピソード記憶、意味記憶)も機能的にモジュール式です。例えば、ある特定の種類の記憶に障害を持つ患者達は、他の種類の記憶には問題がありません。
また、運動系では、ネストフィードバックループアーキテクチャが優勢であり、単純な速いループは脊髄を介して20ミリ秒で自動運動補正を実行します。その後、わずかに遅いスマートループは50ミリ秒以上をかけて運動皮質を介してより高度な運動補正を実行します。そして最後に、運動エラーの意識的な矯正を実行する脳全体を流れる視覚的フィードバックがあります。
最後に、すべての哺乳類の脳の主な特徴は、比較的類似した6層の皮質柱を多数含む大脳新皮質です。皮質柱は、標準的な計算モジュールにバリエーションを実装すると考えられています。
全体として、現代の哺乳類の脳の驚くべきモジュール性は、1億年の独立した進化によって様々に分離された種にわたって保存されており、このシステムレベルのモジュール性がAIシステムの実装に有益であるかもしれないことを示唆します。
ランダムな重みを与えられた白紙状態から均一なニューラルネットワークを訓練する現在のアプローチでは、より一般的な人間のような知性を達成する事が不可能である可能性が高いです。
実際、例として、システムレベルのモジュール性(解剖学的および機能的の両方)の組み合わせ、例えば異なったタイプのエラーを分離するネストループや、より動的に洗練されたシナプスは、前述の生物学的に確からしい貢献度分配問題の大きな課題を解決するための重要な要素です。
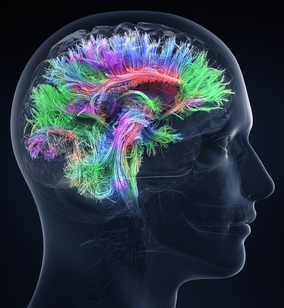
5億年前の脊椎動物の脳の進化は、非常に異質なモジュール式コンピューティングシステムを生み出しました。
教師なし学習、転移学習およびカリキュラム設計
現在のAIシステムと人間のようなAIシステムとの間にあるもう1つの大きな相違は、人間同等のパフォーマンスに近づくためにさえ、AIシステムは膨大な量のラベル付きデータを必要とすると言う事です。
例えば、最近の音声認識システムは、11,940時間の音声を並べ替えて訓練されました。私達が別の人がテキストを読み上げているのを見たり聞いたりして2人組で1日2時間学習したとすると、16年かかります。
AlphaGo zeroは、人間の碁のマスターを倒すために490万回のゲームをセルフプレイしました。人間が30年間毎日碁をプレイするとしたら、AlphaGo zeroと同じくらい練習するためには1日に450回ゲームをプレイしなければなりません。
また、最近の画像付きの質疑応答に関するデータセットには、0.25Mの画像、0.76Mの質問、および最大10Mの回答が含まれています。もし、私達が毎日画像に関する100の質問と回答を受け取ったとすると、このサイズのデータセットを終えるには274年かかります。
3つのケースすべてにおいて、人間は非常に少量のラベル付きトレーニングデータを使って学習し、音声を認識し、碁をプレイし、イメージに関する質問にかなり的確に答えることができます。
人工的知能と生物学的知能との間のこのギャップを埋めるためのいくつかの鍵は、ラベルのないデータから学習する能力(教師なし学習)、ならびに以前の課題を解決することで得られた強力な事前知識を基にして、その知識を新しい課題に移転する能力(移転学習)です。最後に、人間社会は知識の習得を容易にするために慎重に選択された一連のタスクの設計(カリキュラム設計)を含む教育システムを作り上げました。
人工システムでこれらの概念を効率的に具体化するためには、人間や他の動物が教師なし学習をする方法、タスク間で知識を移転する方法、そしてカリキュラムを最適化する方法についての深い理解と数学的定式化が必要です。コンピュータ科学者、心理学者、および教育者の相互協力を必要とするこれらの分野の進歩は、おそらく現在のAIシステムが法外なデータを必要とする問題を解決する鍵となるでしょう。そしてそれらは、ラベル付きデータが乏しい他の分野でAIを強化するために不可欠です。
![]()
タスクノミー:スタンフォードで行われた26の異なる視覚タスク間の移転学習の研究。CVPR2018のBest paper賞
(人工知能を創造するために生物の知能の仕組みを探求する試み(2/6)からの続きです)
(人工知能を創造するために生物の知能の仕組みを探求する試み(4/6)に続きます)
3.人工知能を創造するために生物の知能の仕組みを探求する試み(3/6)関連リンク
1)hai.stanford.edu
The intertwined quest for understanding biological intelligence and creating artificial intelligence
