
1.Grasp2Vec:物体を掴む事により認知能力を高める自己監視型強化学習(2/2)まとめ
・Grasp2Vecは物体をベクトル表現する事で物体同士のベクトル演算を可能にする
・これによりGrasp2Vecは物体同士の類似性や指定物体の場所の特定ができる
・今後、ロボット工学は自己管理型学習の新しい学習パラダイムを機械学習にもたらす
2.掴む事と様々な認知機能の発達の関係
以下、ai.googleblog.comより「Grasp2Vec: Learning Object Representations from Self-Supervised Grasping」の意訳です。元記事は2018年12月11日、Eric JangさんとColine Devinさんによる投稿です。前半はこちら。
この認識問題を解決するためには、教師なしで物体を視認する知覚システムが必要になります。この知覚システムは、人間が付与したラベルが存在しない、構造化されていない画像(様々な角度から撮影された様々な物体の画像が使われるので体系的に整理ができない画像)であっても、そこから意味のある物体の概念を抽出できる必要があります。
キーとなるアイディアは、教師なし学習アルゴリズムです。なぜなら、データに対して構造的な仮定を作る必要があるからです。
画像を取り扱う際には以下の仮定が広く一般的に認識されています。「画像は扱いやすいように低次元ベクトルに圧縮する事が可能である」「ビデオのフレームは前のフレームから予測する事ができる」。しかし、これらの仮定は暗黙のうちに画像やデータが連続している事を前提としています。そのため、これらは通常、画像内からオブジェクトを知覚する学習の際には使えません。
ロボットを使って物体同士を物理的に分離させながらデータを収集するとどうなるでしょうか?
ロボティクスの分野は特徴表現学習(representation learning)のための素晴らしい機会を提供します。何故なら、ロボットは物体を動かす事が出来るので、特徴表現学習の学習データに必要な様々な変動要因を提供する事ができるためです。
Grasp2Vecは、「物体を掴むと物体は風景内から消える」という洞察が発想の元になっています。
つまり、物体を掴む事により、以下が生み出されます。
1)物体を掴む前の風景
2)物体を掴んだ後の風景
3)掴まれた物体だけの風景

左:掴む前の複数物体、中央:掴んだ後の複数物体、右:掴んだ物体
次に、画像から物体の「集合」を抽出する埋め込み関数を考案すると、次の減算関係が成り立ちます。
![]()
「掴む前の複数物体」-「掴んだ後の複数物体」=「掴んだ物体」
私達は完全な畳み込みアーキテクチャと単純な評価学習アルゴリズムを使用して、この等価関係を実装しました。以下に示すように、トレーニング時に「掴む前の画像」と「掴んだ後の画像」を密な特徴マップに拡張します。このマップを更にベクトル化し、「掴む前のベクトル」と「掴んだ後のベクトル」の差で物体をべクトル表現する事ができるようになります。このベクトルおよび掴んだ物体をベクトル化したものをN-Pairs Lossを用いて比較します。
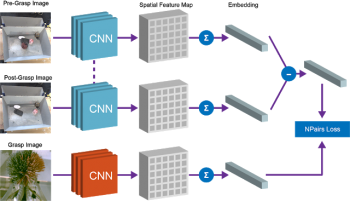
いったん訓練が完了すると、私達のモデルからは2つの有用な特性が自然に浮かび上がります。
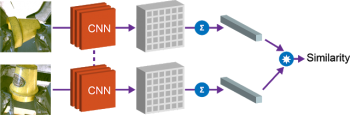
(1)物体同士の類似性
第1の特性は、ベクトル間の余弦距離を用いて、物体を比較し、それらが同一であるかどうかを判断する事が出来るようになる事です。強化学習のための報酬関数の実装に使う事が出来、人間が各画像にラベル付けせずともロボット自ら学習して物体を掴む事ができるようにするために使用できます。
(2)指定物体の位置の特定
第2の特性は、容器内のベクトルと物体のベクトルを組み合わせて、容器内のどこに指定した物体が存在するか場所の特定ができる事です。容器内の特徴量のベクトルと物体のベクトルの要素的な積をとることによって、指定した物体と容器の「一致する」空間を見つけることができます。
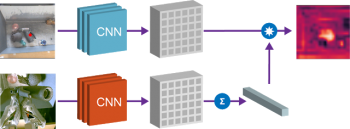
Grasp2Vecのembeddingsを利用してシーン内に存在する物体を特定します。左上の画像には、容器内の複数物体が表示されています。左下の画像には、ロボットに掴ませたい対象物体の画像が表示されています。対象物体のベクトルと容器内画像ベクトルの内積を計算することによって、画像の特定の領域がどれほど対象の物体と類似しているかについて、画素毎のヒートマップ(右上の画像)を得る事ができます。このヒートマップを参照すれば、ロボットは掴みたい物体がどこにあるのか知ることができます。
この手法は、指定した物体に一致する物体が複数ある場合、または指定した物体が複数の物体(2つのベクトルの平均)で構成されている場合にも機能します。たとえば、容器内の複数のオレンジ色のブロックを検出する例を次に示します。

得られたヒートマップを使用して、対象物体にロボットのアームを近づける方法を計画することができます。Grasp2Vecの上記2特性と「何でも良いから掴め」と設定したポリシーを組み合わせると、学習時に見た事がある物体では80%、ロボットが以前に見た事がない新規物体では59%の成功率で物体を掴む事に成功しました。
結論
私達の論文では、ロボットで物体を掴む事を応用して、オブジェクト中心の特徴表現学習用データを生成する方法を示しました。更に特徴表現学習を応用して物体を把握するような複雑なスキルを、強化学習させる事ができます。
最近発表された論文の中には、私たちの論文以外にも、実験環境内の物体を掴んだり、押したり、操作することによってもたらされる相互作用を利用して特徴表現学習を獲得する方法を研究している論文があります。今後は、機械学習がより良い知覚と制御の手段をロボット工学にもたらすだけでなく、ロボット工学が自己管理型学習の新しいパラダイムを機械学習にもたらしていく事に興奮しています。
謝辞
この研究はEric Jang, Coline Devin, Vincent Vanhoucke, and Sergey Levine. We’d like to thank Adrian Li, Alex Irpan, Anthony Brohan, Chelsea Finn, Christian Howard, Corey Lynch, Dmitry Kalashnikov, Ian Wilkes, Ivonne Fajardo, Julian Ibarz, Ming Zhao, Peter Pastor, Pierre Sermanet, Stephen James, Tsung-Yi Lin, Yunfei Bai,およびGoogle、及びGoogle Xの皆さん、本研究の改善に貢献した幅広いロボットコミュニティの皆さんのお力により実現されました。
(Grasp2Vec:物体を掴む事により認知能力を高める自己監視型強化学習(1/2)からの続きです)
3.Grasp2Vec:物体を掴む事により認知能力を高める自己監視型強化学習(2/2)関連リンク
1)ai.googleblog.com
Grasp2Vec: Learning Object Representations from Self-Supervised Grasping


「representation learning」は慣例的に「表現学習」と訳されるのが一般的なようですが、ベストセラーになった「人工知能は人間を超えるか」では、冒頭にわざわざ断り書きをいれて「特徴表現学習」という訳語を導入しておられます。「表現学習」より「特徴表現学習」の方がわかりやすいので私もなるべく「特徴表現学習」に訳語統一していこうと思います。ここでは「モヤモヤした状態から、何らかの特徴を捉えて、ある概念を認知し、それを形作っている表現を学ぶ」言うイメージで良いかと思います。