
1.PI-ARS:視覚移動タスクに進化型の学習を採用して高速移動を実現(1/2)まとめ
・進化戦略は自然界の仕組みに発想を得た最適化技術で強化学習に勝る点もある
・しかし高次元の感覚入力を必要とする問題への適用が困難な事が弱点であった
・PI-ARSは特徴表現学習と進化戦略を組み合わせる事この課題の解決を目指した
2.PI-ARSとは?
以下、ai.googleblog.comより「PI-ARS: Accelerating Evolution-Learned Visual-Locomotion with Predictive Information Representations」の意訳です。
元記事は2022年10月20日、Wenhao YuさんとKuang-Huei Leeさんによる投稿です。
アイキャッチ画像はstable diffusionの1.5版の生成で、四本足で歩く猫っぽいバス、すなわち猫バス生成を目指したのですが、バスの上に乗ったり、バスと融合したり、遂にはバイクに乗り始めたりとあまり言う事を聞いてくれなかったトトロ
進化戦略(ES:Evolution Strategy)は、自然界の淘汰の考え方に触発された最適化技術の一種です。
ESでは、最適化の目的によりよく適応するために、通常、問題を解決する可能性を持つ集団が何世代にもわたって進化していきます。ESは、脚式運動、回転翼4基搭載型無人機の制御、さらには電力系統制御など、様々な困難な意思決定問題に適用されてきました。
勾配に基づく強化学習(RL:Reinforcement Learning)手法、例えばPPO(Proximal Policy Optimization)やSAC(Soft Actor-Critic)と比較すると、ESにはいくつかの利点があります。
まず、ESは制御パラメータの探索空間を直接探索できます。一方、勾配に基づく手法はしばしば限られた行動空間を探索し、その結果が制御パラメータに間接的な影響を与えます。直接的な探索は、学習性能を高め、並列計算による大規模なデータ収集を可能にすることが示されています。
第二に、RLの大きな課題に、長期的な視点での「貢献度分配(credit assignment)」があります。貢献度分配とは、例えば、ロボットが最終的にタスクを達成したとき、過去に行ったどの行動が最も重要だったのか?、何により大きな報酬を割り当てるべきかを決定することです。ESは直接的に総報酬を考慮するため、研究者は明示的に貢献度を割り当てる必要から解放されます。
また、勾配情報を用いないため、勾配が滑らかでない目標や、メタ強化学習のような勾配計算が自明でない制御アーキテクチャを自然に扱うことができます。しかし、ESに基づくアルゴリズムの大きな弱点は、複雑な視覚入力を持つロボットの訓練など、環境が大きな変化を符号化するために高次元の感覚入力を必要とする問題への拡張が困難であることです。
本研究では「PI-ARS: Accelerating Evolution-Learned Visual-Locomotion with Predictive Information Representations」を提案します。ここでは特徴表現学習(representation learning)とESを組み合わせた学習アルゴリズムで、高次元問題を規模拡大して効率よく解決することができる事を示します。
特徴表現学習の目的である予測情報(predictive information)を活用して、高次元の環境変化のコンパクトな特徴表現を獲得し、学習したコンパクトな特徴表現をロボットの行動に変換するために、ESアルゴリズムとして有名な拡張ランダム探索(ARS:Augmented Random Search)を適用することがコアとなるアイデアです。
私達は、PI-ARSを足歩行ロボットの視覚を用いた移動という難問に適用し、検証を行いました。PI-ARSは、様々な困難な環境を踏破できる高性能な視覚ベースの移動制御を高速に学習することが可能です。さらに、シミュレーション環境で学習させたコントローラを実際の四足歩行ロボットに移植することに成功しました。
PI-ARSは、実世界に転移可能な信頼性の高い視覚-運動ポリシーを学習します。
予測情報(predictive information)
ポリシー学習のための優れた特徴表現は、生の観測データから学習するよりもはるかに低次元の問題を解くことに集中できる圧縮性と、学習されたコントローラが最適な動作を学習するために必要なすべての情報を持つタスク重要性の両方を備えている必要があります。入力データが高次元になるロボット制御問題では、ロボット自身とその周囲の物体の両方の動的情報を含む環境を理解することが、ポリシーにとって重要です。
そこで、私達は、生の入力観測データから情報を保存する観測エンコーダ(observation encoder)を提案します。このエンコーダを用いることで、ロボットは環境の将来の状態を予測することができ、これを予測情報(PI:Predictive Information)と呼びます。
より具体的には、「ロボットが過去に見た事と計画した事を符号化したもの」が、「ロボットが将来見る事と受けるかもしれない報酬」を正確に予測できるように、エンコーダを最適化します。
このような特性を表現する数学的ツールの1つが相互情報量(mutual information)であり、ある確率変数Xについて、別の確率変数Yを観測することで得られる情報量を測定します。
私達の場合、XとYはロボットが過去に見て計画したもの、そしてロボットが未来に見て受けとる報酬です。
相互情報量目標を直接最適化することは困難な問題です。なぜなら、私達は通常、確率変数のサンプルしか入手できません。その大元となる分布にはアクセスできないからです。本研究では、相互情報量の対変分境界(contrastive variational bound)であるInfoNCEを用いた以前のアプローチに倣います。
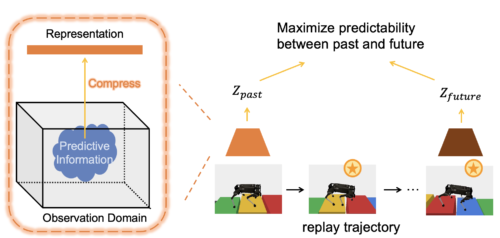
左図:特徴表現学習を用いて、環境のPIを符号化します。
右図:リプレイバッファから軌跡を再生し、過去の観測と運動計画、未来の観測と軌跡の報酬の間の予測可能性を最大化することで、特徴表現を学習します。
拡張ランダム探索を用いた予測情報
次に、予測情報(PI:Predictive Information)と拡張ランダム探索(ARS:Augmented Random Searchを組み合わせます。ARSは、困難な意思決定タスクに対して優れた最適化性能を示すアルゴリズムです。ARSの各反復では、摂動が加えられたコントローラパラメータの母集団をサンプリングし、テスト環境におけるそれらの性能を評価し、より良い性能を示したものにコントローラを移動させる勾配を計算します。
3.PI-ARS:視覚移動タスクに進化型の学習を採用して高速移動を実現(1/2)関連リンク
1)ai.googleblog.com
PI-ARS: Accelerating Evolution-Learned Visual-Locomotion with Predictive Information Representations
2)arxiv.org
PI-ARS: Accelerating Evolution-Learned Visual-Locomotion with Predictive Information Representations

