
1.分類精度が高すぎるモデルは知覚的類似度を予測する用途に不向き(1/2)まとめ
・画素の違いから画像の類似性を推定する方法は人の知覚とあまり一致しない
・画像分類器内の中間特徴表現を使うと知覚的類似性に近い分類が出来る
・どのような画像分類器が高い知覚的類似性を持つか調査したら驚きの結果
2.知覚的類似度とは?
以下、リニューアルされたai.googleblog.comより「Do Modern ImageNet Classifiers Accurately Predict Perceptual Similarity?」の意訳です。元記事は2022年10月19日、Manoj KumarさんとEkin Dogus Cubukさんによる投稿です。
これもまたかなり衝撃的なお話で、転移学習は慣例的に行われているけれども実際にはまだよくわかってない部分もあるのだな、と言う事を改めて実感します。
アイキャッチ画像はstable diffusionの1.5版で微妙に違うけれども知覚的類似度としては似ているトトロ
画像間の類似性を決定するタスクは、コンピュータビジョンにおける未解決の問題であり、機械で生成された画像のリアルさを評価するために重要です。
画像の類似性を推定する方法はいくつかありますが(例えば、FSIMやSSIMのような画素の違いを測定する低レベル指標)、多くの場合、これらの手法で測定された類似性の差は人が知覚する差と一致することはありません。
しかし、より最近の研究では、ImageNet上で学習したAlexNet、VGG、SqueezeNetなどのニューラルネットワーク分類器の中間特徴表現が、全体的な性質として知覚的類似性を示すことが示されています。すなわち、ImageNetで学習したモデルによって符号化された画像特徴表現間のユークリッド距離は、画像の画素から直接知覚的類似性を推定するよりも、画像間の差異に関する人の判断とはるかに良い相関を示すのです。
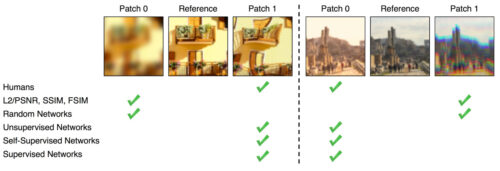
BAPPSデータセットからのサンプル画像の2セット。低レベルの指標(PSNR、SSIM、FSIM)と比較して、訓練されたネットワークは人間の判断とより一致します。画像ソース(Zhang et al. 2018)。
Transactions on Machine Learning Researchに掲載された論文「Do better ImageNet classifiers assess perceptual similarity better?」において、私達はImageNet分類器の精度と、知覚的類似性を捉えるその全般的な性質との関係に関する広範な実験研究を寄稿しました。
この出現する性質を評価するために、私達は先行研究に従い、BAPPSデータセット上で画像の類似性に関するモデルと人間の嗜好の相関である知覚スコア(PS:Perceptual Scores)を測定します。先行研究では、AlexNet、SqueezeNet、VGGなどの第1世代のImageNet分類器を研究していましたが、私達はResNetsやVision Transformers(ViTs)などの最新の分類器を取り入れ、幅広いハイパーパラメータで分析範囲を大幅に拡大しました。
精度と知覚的類似度の関係
ImageNetで学習した特徴表現は、多くの下流タスクにうまく転移されることがよく知られており、ImageNetを使った事前学習は標準的なレシピになっています。さらに、ImageNetでの精度が高いほど、通常の破損に対する頑健性、分類外データに対する汎化、より小さな分類データセットでの転移学習など、様々な下流タスクでの性能が向上することが一般的であることを意味します。
ImageNetで高い検証精度を持つモデルは、他のタスクにもよく移行する可能性があることを示唆する汎用的な証拠があります。しかしながら、驚くべきことに、私達は検証精度が控えめなImageNetモデルからの特徴表現が、最高の知覚スコアを達成することを見出しました。
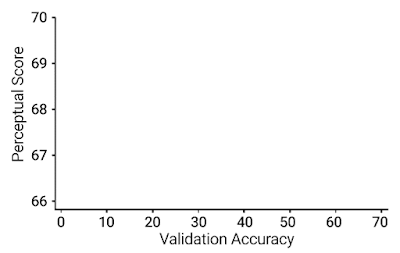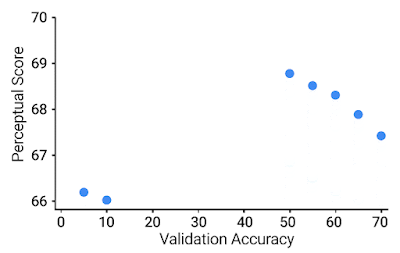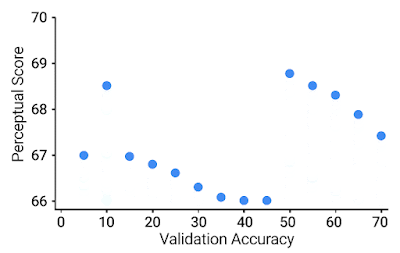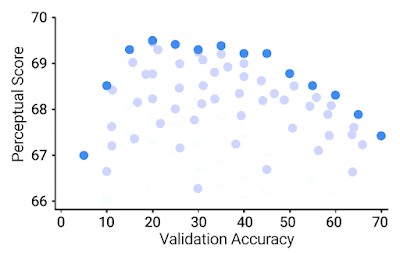
64 x 64のBAPPSデータセットにおける知覚スコア(PS)をy軸、ImageNetの64×64検証精度をx軸にしたグラフ。青い点はImageNetの分類器を表しています。より良いImageNet分類器は、ある時点(紺色)まではより良いPSを達成し、それ以降は精度を向上させることでPSが低下します。最高のPSは、中程度の精度(20.0-40.0)を持つ分類器によって達成されます。
私達は、ニューラルネットワークのハイパーパラメータ(幅、深さ、学習ステップ数、重み減衰、ラベルスムージング、ドロップアウト)の関数として知覚スコアの変動を研究します。各ハイパーパラメータに対して、精度を向上させるとPSが向上する最適な精度が存在します。この最適値はかなり低く、ハイパーパラメータゆっくり変化させてもかなり早い段階で達成されます。この点を超えると、分類器の精度の向上はPSの悪化に繋がります。
下図に、ResNetの学習ステップとViTsの幅という2つのハイパーパラメータに対するPSの変化を示します。ResNet-50とResNet-200のPSは、学習の最初の数エポックで非常に早くピークに達っします。このピークを過ぎると、より優れた分類器のPSはより急激に減少します。ResNetは、学習ステップの関数として精度が段階的に上昇するような学習率スケジュールで学習されます。興味深いことに、ResNetsはピークを境にPSが段階的に減少しますが、これはこの段階的な精度上昇と一致します。
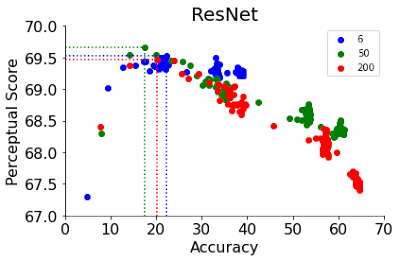
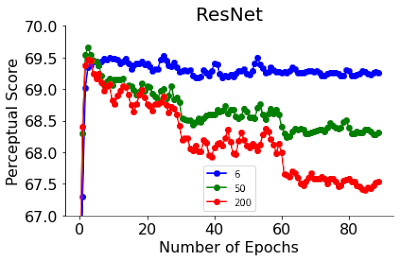
6、50、200の異なる深さでも最高のPSを達成するのは早期停止した時です。
ViTは、入力画像に適用するtransformerブロックを積み重ねたものです。ViTのモデル幅は、1つのtransformerブロックの出力ニューロンの数です。この幅を大きくすることは、精度を向上させるために有効な手段です。ここでは、B/8とL/4(パッチサイズ4のBaseモデルと8のLarge ViTモデル)の幅を変化させ、精度とPSの両方を評価しました。
早期停止したResNetsでの観測と同様に、精度の低い幅の狭いViTは、デフォルトの幅よりも良い性能を示しました。驚くべきことに、ViT-B/8とViT-L/4の最適な幅は、デフォルトの幅の6%と12%です。ResNetsとViTの幅、深さ、学習ステップ数、重み減衰、ラベルスムージング、ドロップアウトなど、他のハイパーパラメータを含むより包括的な実験のリストについては、私達の論文をご覧ください。
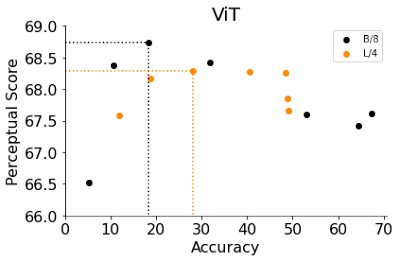
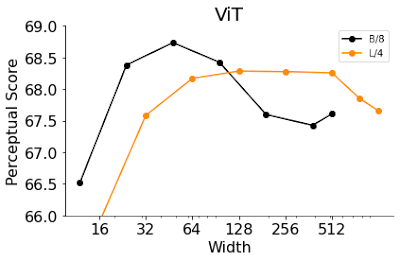
幅の狭いViTが最高のPSを達成します
3.分類精度が高すぎるモデルは知覚的類似度を予測する用途に不向き(1/2)関連リンク
1)ai.googleblog.com
Do Modern ImageNet Classifiers Accurately Predict Perceptual Similarity?
2)openreview.net
Do better ImageNet classifiers assess perceptual similarity better?(PDF)

