
1.Stable Diffusion 1.5が公開されるも色々トラブるまとめ
・未公開版であったStable Diffusion1.5が従来と違うリポジトリで突然公開
・漏洩かと思われたが元々プロジェクトに関わっていた別会社によるものだった
・今後はStabilityAI系列とRunwayML系列のStable Diffusionに分裂しそう
2.Stable Diffusion 1.5とは?
オープンソースとして公開された画像生成人工知能であるStable Diffusionは当初、Version 1.1、1.2、1.3、1.4を公開していました。
一昨日、従来のリポジトリ(CompVis)と異なるリポジトリ(runwayml/stable-diffusion-v1-5)で1.5が突然公開されました。
現在、英語圏でも情報がやや錯綜しているのですが、私が把握できた限り流れは以下です。
Stable Diffusion 1.5公開の経緯
・Stable Diffusionの研究主体はCompVis(大学の研究グループ)で、StabilityAIとRunwayMLは資金提供と論文の共同執筆者であった。
・Stable Diffusion1.1、1.2、1.3、1.4がオープンソースとして公開されて有名になった。
・StabilityAIはStable Diffusionの有料webサービスとしてdreamstudio.aiを運営しており、そこではStable Diffusion 1.5が少し前から使用可能になっていたが、Stable Diffusion 1.5はオープンソースとしては公開されていなかった。
・一昨日、RunwayMLが突然(おそらくStabilityAIと未調整で)、Stable Diffusion 1.5を公開。
・StabilityAIがRunwayMLに公開を差し止めるよう請求をしたが、後にStabilityAIのCEOが差し止め請求を取り下げ。
・法的にはRunwayMLはStabilityAIと同等の権利を持っているので不正なリークというわけでなさそう。
私の理解ですと、StabilityAIにとっては公開を受けて有名にはなったけれども風当たりも強くて、職場閲覧注意画像(NSFW:Not Safe For Work)等を無くす努力をしていた最中に突然RunwayMLにリークに近いような形でリリースされてしまって対外的な信用を失う事を危惧しているという感じで、RunwayML的には権利的には全く問題ないのだから自分達も独自にリリースしたいって事なのだと思います。
すれ違いが完全に解決されたわけではなさそうなので、今後はStabilityAI系のStable DiffusionとRunwayML系のStable Diffusionに分裂しそうな気はします。(そもそも、dreamstudio.aiで使用されていたStable Diffusion 1.5と今回リリースされたStable Diffusion 1.5が同じものなのかもはっきりしません)
1.5は1.4と比べてどれだけ改善されているのか?
Web上では「凄い改善されている派」と「あまり変化が感じられない派」に分かれてますが、githubのrunwayml/stable-diffusionからグラフを引用すると下記です。
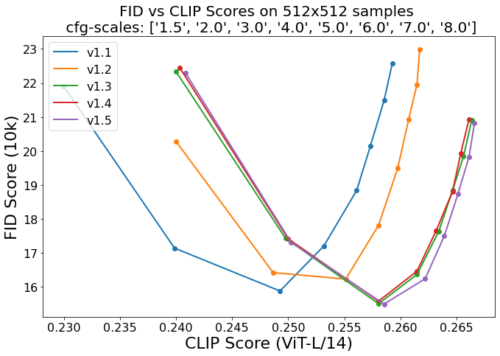
1.4も1.5も1.2がベースで、数字だけ見ると同じデータセットで370k step学習を増やしているだけなので大幅な改善と言うわけではなさそうです。
Stable-Diffusion-v1.5が動かせない人向け情報
前述のようにリリース時にややゴタゴタがあったせいか、現状、Stable-Diffusion-v1.4が動かせてるdiffusers環境でStable-Diffusion-v1.5を動かそうとしても従来見たことがないエラーが出る事があります。
私が遭遇したエラーとその回避策を以下に書いておきます。
(1)モデルがダウンロードできない
huggingface上で利用申請は完了していてページは見れており、huggingface-cli loginも完了しているのに上記のようなエラーが出る人
以下の手順でローカルにダウンロードしてきてフォルダを作った後に実行する事で解決できる可能性があります。
sudo apt-get install git-lfs git lfs install git clone https://huggingface.co/runwayml/stable-diffusion-v1-5 mkdir runwayml mv stable-diffusion-v1-5 runwayml/
Stable-Diffusion-v1.4が動かせている環境がある場合は上記手順で1.5モデルのダウンロードとフォルダ作成を行ってmodel_idだけ差し替える方が良いかもです。
model_id = "runwayml/stable-diffusion-v1-5" pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16, revision="fp16")
私のように「基本に戻って元サイトに書いてある手順で仮想環境を作り直そう」と考えてしまうと以下の様に逆に深みにはまります
(2)CUDAのエラーが出る
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
というエラーが出る人
github.com/runwaymlに書かれている
conda install pytorch torchvision -c pytorch
では私の環境RTX-3060 CUDA11.7ではうごかせませんでした。下記で動かせました。
conda install pytorch torchvision torchaudio cudatoolkit=11.6 -c pytorch -c conda-forge
(3)サンプルスクリプトがエラーになる
や
や
で困っている人
RunwayMLが使っているdiffusers等のVersionの違いかなと思うのですが、
https://huggingface.co/runwayml/stable-diffusion-v1-5
に書いてある以下のサンプルは動かないので参考にしない方が良いです。
from diffusers import StableDiffusionPipeline
import torch
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16, revision="fp16")
pipe = pipe.to(device)
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
以下で動く可能性があります。
↓
from diffusers import StableDiffusionPipeline
import torch
device="cuda"
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16, revision="fp16")
pipe = pipe.to(device)
prompt = "a photo of an astronaut riding a horse on mars"
from torch import autocast
with autocast("cuda"):
image = pipe(prompt)["sample"][0]
image.save("astronaut_rides_horse.png")
3.Stable Diffusion 1.5が公開されるも色々トラブる関連リンク
1)github.com
runwayml / stable-diffusion
2)huggingface.co
runwayml/stable-diffusion-v1-5

