
1.MaxViTとMAXIM:ViTの効率を更に高めた視覚タスク用新モデル(2/2)まとめ
・MAXIMは低レベルの画像間予測タスクのために調整されたUNetに似たアーキテクチャ
・画像サイズが大きくなっても計算量は線形に増えるだけなので高解像度処理に効率的
・MaxViTは物体認識、セグメンテーション、美観評価、画像生成などで良好な性能を発揮
2.MAXIMとは?
以下、ai.googleblog.comより「A Multi-Axis Approach for Vision Transformer and MLP Models」の意訳です。元記事は2022年9月8日、Zhengzhong TuさんとYinxiao Liさんによる投稿です。
このモデル、かなり強力に見えますが、現時点で公開されているデモはノイズ除去等の低レベルタスク用で、高レベルタスクへ用のデモは現時点ではなかったです。しかし、低レベルタスク用のデモも十分、凄いです。
アイキャッチ画像はstable diffusion
MAXIM
私達の第2のバックボーンであるMAXIMは、低レベルの画像間予測タスクのために調整された汎用のUNetに似たアーキテクチャです。
MAXIMは、ゲーテッド多層パーセプトロン(gMLP:gated Multi-Layer Perceptron)ネットワーク(ゲート機構を持つ断片混合型MLP)を用いて、局所アプローチと大域アプローチの並列設計を探求しています。
MAXIMのもう一つの貢献は、2つの異なる入力信号間の相互作用に適用するために使用できるクロスゲーティングブロック(cross-gating block)です。このブロックは、計算量の多いクロスアテンションに頼らず、安価なゲーティング付きMLP演算子のみを用いて様々な入力と相互作用するため、クロスアテンションモジュールの効率的な代替手段として機能することが可能です。
さらに、MAXIMのゲート付きMLPとクロスゲーティングブロックを含むすべての提案コンポーネントは、画像サイズに対する線形複雑性を享受しており、高解像度の画像を処理する際にさらに効率的なものとなります。
成果
MaxViTは、様々な視覚タスクにおいて、その有効性を実証しています。画像分類においては、ImageNet-1Kの学習のみで86.5%のtop-1精度を達成し、ImageNet-21K(1400万画像、21000クラス)の事前学習では88.7%のtop-1精度を、JFT(3億画像、18000クラス)の事前学習では4.75億パラメータで最大モデルMaxViT-XLが89.5%の高精度な結果を達成する等、種々の設定において最先端の結果を得ることができました。
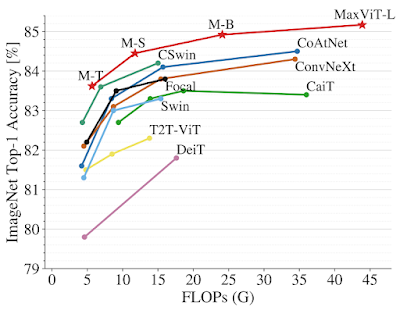
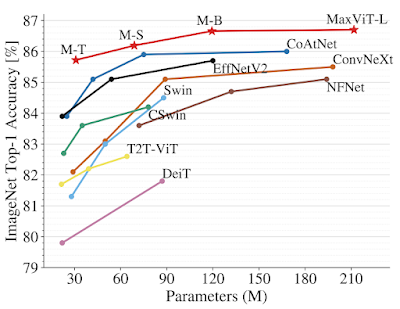
ImageNet-1KにおけるMaxViTと最先端モデルとの性能比較
上:224×224画像解像度での精度 vs. FLOPs性能と規模の関係
下:ImageNet-1Kの微調整設定における精度対パラメータ数と規模の関係
下流タスクでは、MaxViTをバックボーンとして用いることで、幅広いタスクで良好な性能を発揮することができました。COCOデータセットにおける物体検出とセグメンテーションでは、MaxViTバックボーンは53.4APを達成し、他の比較対象モデルを上回りながら、約60%の計算コストしか必要としませんでした。
画像の美観評価(image aesthetics assessment)では、MaxViTモデルは、人間の意見スコアとの線形相関の点で、最先端のMUSIQモデルより3.5%優れています。また、MaxViTは画像生成にも有効であり、ImageNet-1Kの無条件生成タスクにおいて、最新モデルのHiTよりも大幅に少ないパラメータ数で、より良いFIDとISスコアを達成しました。
また、画像処理タスク用にカスタマイズされたUNetに似たMAXIMバックボーンは、競合モデルよりも少ない、あるいは同等のパラメータ数とFLOP数で、ノイズ除去、デブラーリング、ディレイニング、デヘイズ、低光量強調などのテストした20データセットのうち15データセットで最先端の結果を実証しています。MAXIMによって復元された画像は、人工的な映り込みを抑えながら、より多くの細部を復元しています。

MAXIMによる画像のぼやけ除去(deblurring)、雨の影響の除去(deraining)、低光量増強の視覚結果
まとめ
ここ2年ほどの研究により、畳み込みネットワーク(ConvNets)とVision Transformerが同様の性能を達成できることが示されてます。私達の研究は、効率的な畳み込みと疎なAttentionという両者の長所を生かした統一的なデザインを提示し、その上に構築されたモデル、すなわちMaxViTが様々な視覚タスクにおいて最先端の性能を達成できることを実証しています。
さらに重要なことは、MaxViTは非常に大きなデータサイズにうまく対応できることです。また、MLP演算子を用いた別の多軸設計であるMAXIMが、広範な低レベル視覚タスクにおいて最先端の性能を達成することも示しています。
私達は視覚タスクの文脈でモデルを提示していますが、提案する多軸アプローチは、線形時間でローカルおよびグローバルな依存関係を捉える言語モデリングに容易に拡張することが可能です。この研究により、動画、点群、視覚言語モデルなど、より高次元のマルチモーダル信号における疎なAttentionの他の形態を研究することに意義があると期待されます。
我々は、効率的なAttention とMLPモデルに関する将来の研究を促進するために、MAXIMとMaxViTのコードとモデルをオープンソース化しました。
謝辞
共著者に感謝します。
Hossein Talebi, Han Zhang, Feng Yang, Peyman Milanfar,そして Alan Bovik。
また、Xianzhi Du, Long Zhao, Wuyang Chen, Hanxiao Liu, Zihang Dai, Anurag Arnab, Sungjoon Choi, Junjie Ke, Mauricio Delbracio, Irene Zhu, Innfarn Yoo, Huiwen Chang, そしてCe Liu による貴重な議論と支援に感謝いたします。
3.MaxViTとMAXIM:ViTの効率を更に高めた視覚タスク用新モデル(2/2)関連リンク
1)ai.googleblog.com
A Multi-Axis Approach for Vision Transformer and MLP Models
2)arxiv.org
MaxViT: Multi-Axis Vision Transformer
3)openaccess.thecvf.com
MAXIM: Multi-Axis MLP for Image Processing(PDF)
4)github.com
google-research / maxvit
google-research / maxim

