
1.使える時はGPUを使ってビデオ会議の背景置き換えを精緻化(1/2)まとめ
・ビデオ会議の使用頻度は高り、背景置き換え機能はプライバシー保護に重要
・従来は何処でも使用できるようにCPUを使った推論で背景置き換えをしていた
・最新のGoogle Meetは使える際にはGPUを使ってより細かく置き換え可能を
2.WebGL経由でGPUを使用する際の効率化
以下、ai.googleblog.comより「High-Definition Segmentation in Google Meet」の意訳です。元記事の投稿は2022年8月25日、Tingbo HouさんとJuhyun Leeさんによる投稿です。
アイキャッチ画像はstable diffusionでビデオ会議をやっているトトロ
近年、ビデオ会議は多くのユーザーにとって、仕事とプライベートの両方のコミュニケーションにおいてますます重要な役割を果たすようになっています。過去2年間、当社はGoogle Meetにおいて、プライバシーを保護する機械学習(ML:Machine Learning)を利用して背景を隠す機能を導入し、このユーザー体験を強化してきました。
「バーチャルグリーンスクリーン」とも呼ばれ、ユーザーは背景をぼかしたり、他の画像に置き換えたりすることが可能です。この解決策のユニークな点は、追加のソフトウェアをインストールすることなく、ブラウザ上で直接動作することです。
これまで、このようなMLを使った機能は、ニューラルネットワークのスパース性を利用したCPUを使った推論に頼っていました。この解決策は、入門レベルのコンピューターからハイエンドのワークステーションまで、デバイスを問わず使える一般的なものです。これによって、私たちの機能を最も多くの人に届けることができるようになりました。
中級者向けパソコンや高級機には強力なGPUが搭載されていることが多いのですが、機械学習を使ったこの推論には利用されていません。利用可能な既存機能としては、Webブラウザがシェーダー(WebGL経由)でGPUにアクセスすることができます。
Google Meetの最新のアップデートでは、GPUの力を利用して、これらの背景効果の忠実度と性能を大幅に向上させることができるようになりました。論文「Efficient Heterogeneous Video Segmentation at the Edge」で詳しく説明しているように、これらの進歩は、2つの主要なコンポーネントによって支えられています。
1) 新しいリアルタイムビデオセグメンテーションモデル
2) WebGLを用いたブラウザ内MLアクセラレーションのための新しい高効率なアプローチ
この機能を利用して、フラグメントシェーダーによる高速なML推論を開発しました。この組み合わせにより、精度と応答速度が大幅に向上し、より鮮明な前景の境界を実現できます。

Google MeetのCPUを使ったセグメンテーションとHDセグメンテーションの比較
ビデオセグメンテーションモデルの高画質化へ
より細かい情報を予測するために、新しいセグメンテーションモデルは、低解像度の画像ではなく、高解像度(HD:High Definition)の入力画像で動作するようになり、以前のモデルよりも実質的に解像度が2倍になっています。
そのため、より詳細な特徴を抽出するために、モデルには高い能力が要求されます。大雑把に言えば、入力解像度が2倍になると、推論時の計算コストが4倍になります。
CPUで高解像度モデルの推論を行うことは、多くのデバイスで実現不可能です。CPUは高性能なコアをいくつか持ち、任意の複雑なコードを効率的に実行することができるかもしれませんが、HDセグメンテーションに必要な並列計算には限界があります。
これに対し、GPUは比較的低性能なコアを多数持ち、広いメモリインターフェースと相まって、高解像度の畳み込みモデルに独自に適しています。そこで、中級機やハイエンド機では、WebGLを用いて統合された、より高速な純粋なGPUパイプラインを採用しました。
この変更に伴い、モデル・アーキテクチャに関する事前の設計上の決定事項のいくつかを見直すことになりました。
・バックボーン
デバイス上のネットワークで広く使われているいくつかのバックボーンを比較した結果、WebGLでは非効率なコンポーネントであるスクイーズ&エキサイトブロック(squeeze-and-excitation block)を削除したEfficientNet-LiteがGPUに適していることがわかりました(詳細は後述)
・デコーダ
私たちは、単純なバイリニアアップサンプリング(bilinear upsampling)や、より高価なsqueeze-and-excitationブロックの代わりに、1×1畳み込みからなる多層パーセプトロン(MLP:Multi-Layer Perceptron)デコーダに切り替えました。MLPはDeepLabやPointRendなど他のセグメンテーションアーキテクチャで採用され成功しており、CPUとGPUの両方で効率的に計算することができます。
・モデルサイズ
新しいWebGL推論とGPUに適したモデルアーキテクチャにより、スムーズなビデオセグメンテーションに必要なリアルタイムフレームレートを犠牲にすることなく、より大きなモデルを余裕を持って使用することが出来ました。私達は、ニューラルアーキテクチャー探索を使用して、幅と深さのパラメータを探索しました。
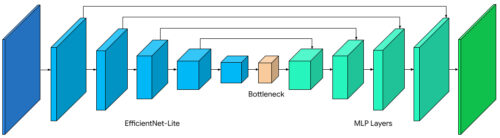
HDセグメンテーションモデルのアーキテクチャ
これらの変更により、Intersection over Union(IoU)の平均値が3%向上し、髪や指の周囲の境界がより鮮明になり、不確実性が減少しました。
3.使える時はGPUを使ってビデオ会議の背景置き換えを精緻化(1/2)関連リンク
1)ai.googleblog.com
High-Definition Segmentation in Google Meet
2)arxiv.org
Efficient Heterogeneous Video Segmentation at the Edge

