
1.UVQ:YouTubeの知覚的なビデオ品質を機械的に測定(2/2)まとめ
・従来は手動で特徴量を設計しMOSでビデオ評価を行う手法が一般的だった
・3つのサブネットワークを自己教師学習させて統合する事で自動化を実現
・UGCの主観的評価の検証用にYouTube-UGCデータセットも公開している
2.UVQとは?
以下、ai.googleblog.comより「UVQ: Measuring YouTube’s Perceptual Video Quality」の意訳です。元記事は2022年8月23日、Yilin WangさんとFeng Yangさんによる投稿です。
アイキャッチ画像はstable diffusion
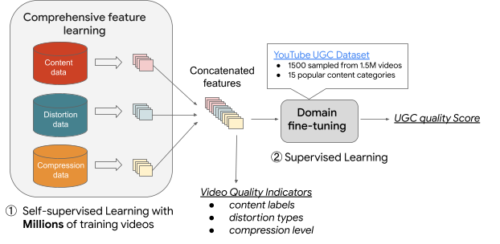
UVQモデルフレームワーク
映像の品質を評価する手法は、高度な特徴量を設計し、その特徴量を平均オピニオン評点(MOS:Mean Opinion Scores)に対応付ける方法が一般的です。
しかし、手作業で有用な特徴量を設計することは、専門家であっても難しく、時間がかかります。また、最も有用な既存の手作り特徴表現は、限られたサンプルからまとめられており、より広範なUGCのケースでうまく機能しない可能性があります。これに対し、機械学習は大規模なサンプルから自動的に特徴を学習することができるため、UGC-VQAにおいてより顕著になりつつあります。
簡単なアプローチは、既存のUGC品質データセットでゼロからモデルを学習することです。しかし、質の高いUGCデータセットが限られているため、これは実現不可能な場合があります。この限界を克服するため、私達はUVQモデルの学習時に自己教師付き学習ステップを適用します。この自己教師付き学習ステップにより、何百万もの生映像から、検証済MOSデータがなくとも、品質に関連する包括的な特徴を学習することができます。
主観的な映像品質評価(VQA:Video Quality Assessment)によって要約された品質関連カテゴリに従い、私達は4つの新規サブネットワークを持つUVQモデルを開発します。
ContentNet、DistortionNet、CompressionNetと呼ぶ最初の3つのサブネットワークは、品質の特徴(すなわち、コンテンツ、歪み、圧縮)を抽出するために用いられ、AggregationNetと呼ぶ4番目のサブネットワークは、単一の品質スコアを生成するために抽出した特徴をマッピングします。
ContentNetは、YouTube-8Mモデルによって生成されたUGC固有のコンテンツラベルを用いて、教師あり学習方式で学習されます。
DistortionNetは、一般的な歪み、例えば、ガウスぼかしやオリジナルフレーム内のホワイトノイズを検出するために学習されます。
CompressionNetは、ビデオ圧縮時に出来てしまう人工物に着目するようにし、異なるビットレートで圧縮されたビデオを学習データとしています。同じコンテンツの2つの圧縮されたバリエーションを使用してトレーニングされ、対応する圧縮レベル(より顕著な圧縮時人工物に対してより高いスコア)を予測するモデルに供給され、高いビットレートのバージョンでは圧縮レベルが低いという暗黙の仮定を持ちます。
ContentNet,DistortionNet,CompressionNetの各サブネットワークは、検証済み品質スコアを持たない大規模なサンプルで学習されます。ビデオの解像度も重要な品質要素であるため、解像度に敏感なサブネットワーク(CompressionNetとDistortionNet)は断片ベース(すなわち、各入力フレーム別々に処理される複数の不連続な断片に分割)であり、ダウンスケールせずに本来の解像度ですべての詳細を捕らえることが可能です。3つのサブネットワークは品質特徴を抽出し、4番目のサブネットワークであるAggregationNetによって連結され、YouTube-UGC領域の検証済みMOSの品質スコアを予測します。
UVQのトレーニングフレームワーク
UVQによる映像品質の分析
UVQモデルを構築した後、YouTube-UGCから取得したサンプルの映像品質を分析し、そのサブネットワークが、品質問題を理解するのに役立つ高レベルの品質指標とともに、単一の品質スコアを提供できることを実証します。
例えば、DistortionNetは、以下の中央のビデオについて、ジッターやレンズブラーなどの複数の視覚的アーティファクトを検出し、CompressionNetは、下のビデオが大きく圧縮されていることを検出します。

ContentNetでは、コンテンツラベルとそれに対応する確率(括弧内)を付与します。
すなわち、車(0.58)、車両(0.42)、スポーツカー(0.32)、モータースポーツ(0.18)、レース(0.11)です。

DistortionNetは、複数の視覚的歪みを検出し、括弧内の対応する確率でカテゴリ分類します。すなわち、ジッター(0.112)、色量子化(0.111)、レンズブラー(0.108)、ノイズ除去(0.107)です。

CompressionNetは、上のビデオについて0.892の高圧縮レベルを検出します。
さらに、UVQは断片ベースのフィードバックを提供し、品質の問題を突き止めることができます。以下では、UVQは最初の断片(時刻t = 1の断片)の品質は圧縮レベルが低く、良好であることを報告しています。しかし、このモデルでは、次の断片(時間t = 2の断片)に重い圧縮時の人工物があることが確認されています。
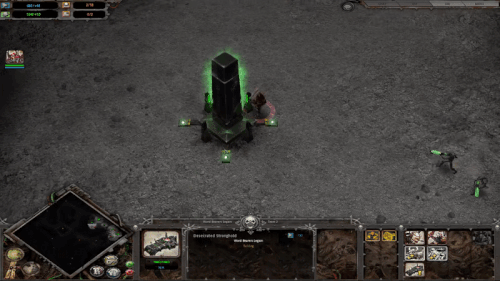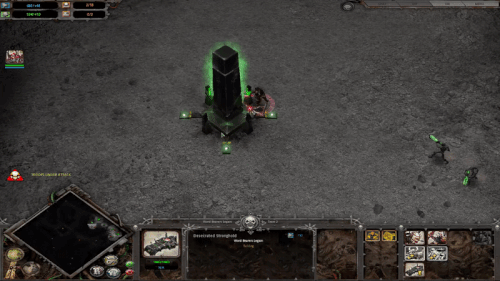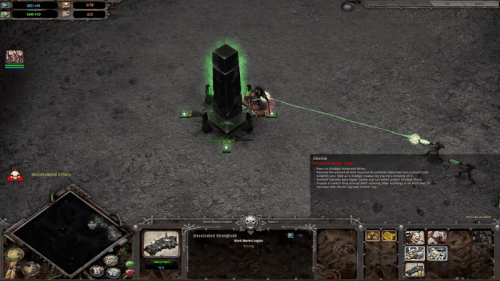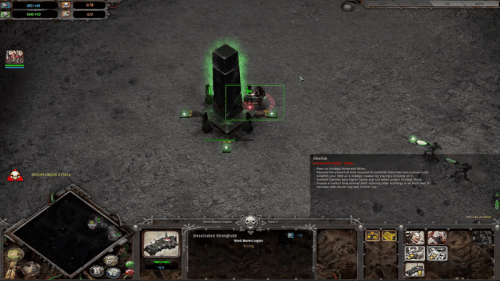

時刻t = 1の断片
圧縮レベル = 0.000

時間t = 2の断片
圧縮レベル = 0.904
UVQは、局所的な断片部に対して急激な品質劣化(高圧縮レベル)を検出します。
実務的には、ビデオの診断レポートを生成することができます。ビデオのコンテンツ(例:戦略ビデオゲーム)、歪み解析(例:映像がぼやけている、画素が多い)、圧縮レベル(例:低圧縮、高圧縮)などがあります。
以下、UVQの報告では、個々の特徴を見るとコンテンツの品質は良いが、圧縮と歪みの品質が低いということになります。3つの特徴を組み合わせた場合、全体的な品質は中~低となります。
これらの結果は、社内のユーザー評価の専門家がまとめた根拠と近いことがわかり、UVQが品質評価を通して推論し、かつ単一の品質スコアを提供できることが実証されました。
UVQの診断レポート
ContentNet(CT):ビデオゲーム、戦略ビデオゲーム、World of Warcraftなど
DistortionNet(DT):乗法性ノイズ、ガウスブラー、彩度、ピクセルレートなど。
CompressionNet(CP):0.559(中-高圧縮)
1から5の範囲の予測品質スコア:(CT, DT, CP) = (3.901, 3.216, 3.151),
(CT+DT+CP) = 3.149 (中-低 品質)。
まとめ
UGCビデオの知覚品質を解釈するために使用できる品質スコアと知見を含むレポートを生成するUVQモデルを紹介します。UVQは、何百万ものUGCビデオから品質に関連する包括的な特徴を学習し、参照ビデオなしと参照ビデオあり両方のケースについて、品質解釈の一貫した視点を提供します。詳細については、私達の論文をお読みいただくか、私達のウェブサイトでYT-UGCビデオとその主観的品質データをご覧ください。また、強化されたYouTube-UGCデータセットにより、この分野での研究がさらに進むことを期待しています。
謝辞
この研究は、Google の複数のチームによるコラボレーションによって実現されました。主な貢献者は以下の通りです。YouTube の Balu Adsumilli、Neil Birkbeck、Joong Gon Yim、Google Research の Junjie Ke、Hossein Talebi、Peyman Milanfar です。Ross Wolf, Jayaprasanna Jayaraman, Carena Church, Jessie Lin の貢献に感謝します。
3.UVQ:YouTubeの知覚的なビデオ品質を機械的に測定(2/2)関連リンク
1)ai.googleblog.com
UVQ: Measuring YouTube’s Perceptual Video Quality
2)openaccess.thecvf.com
Rich features for perceptual quality assessment of UGC videos(PDF)
3)media.withyoutube.com
YouTube dataset for video compression research

