
1.いいえ!人工知能は予言なんてしませんまとめ
・Google翻訳に意味のない入力をすると神の言葉を代弁し始めると話題に
・人工知能が意志を持ちはじめたとか人工知能脅威論を煽る人も
・宗教的な発言が出力される理由はマイナー言語では宗教的資料を使わざるを得ないから
2.何故、Google翻訳はまるで関連性がない宗教的文章に翻訳をする事があるのか?
Google翻訳を使ってマオリ語等のマイナーな言語から英語に翻訳しようとすると、「dog dog ・・・・ dog」等の意味のない文章が「終末の時計は12時3分を指ししめします。・・・イエスの再来が近づいています」
などと、元の文章と何の関連性も感じ取れないあたかも予言のような文章が出力される事がアメリカや日本でも一部で話題になっていました。
その理由を解説している方がいたので以下で意訳します。
2020年6月追記:本投稿にあるようなエラー(機械翻訳の幻覚)は直近のGoogle翻訳ではかなり減った事が解説された記事がこちらに投稿されています。
要約:いいえ!機械学習は予言なんてしません!でも機械学習翻訳の6つの問題について見ていきましょう。
私は今日、Motherboard.vice.comのTwitterのスレッドを見ました。「Google翻訳は何故、翻訳結果に奇妙で宗教的な文章を出力させる事があるのか?」この投稿はこの問いに対する回答ですが、私は「何故」の部分に少し時間を費やすつもりです。(機械学習を専門にしている人たちは何故なのか既に知っていると思いますが)そして、機械翻訳の実際の問題にも焦点を当てようと思います。
しかし、まず少し余談ですが責任あるAI文章として余談を。Google翻訳が宗教チックな訳を出力する事に関するヘッドライン、宣伝ツイート、沢山の記事は有名な「Facebookのフランケンシュタイン実験」に関する無責任な文章を思い起こさせます。
他のメディアがこのMotherboard.vice.comのTweetをピックアップし、人工知能脅威論/陰謀論に関するばかばかしい話をしても、私は驚かないでしょう。もしあなたがジャーナリストとしてAIについて書いているのであれば、あなたのウェブサイトのアクセス増をもたらすためにセンセーショナルな見出しを使うのは最悪です。
ほとんどの人は見出しだけを読んで「なんてこった! AIは私たちを殺してしまうだろう!」とソーシャルネットワーク上で誤った情報を更に拡散するのです。そしてこれは、AIが抱えている本当の問題、偏見、差別、武器化のような現実の害から私たちを逸らしてしまうのです・・・。
OK、十分にわめきましたかね、それでは技術的な話題に戻りましょうか。
では、何故、宗教的なテキストが出力されてしまうのでしょうか?
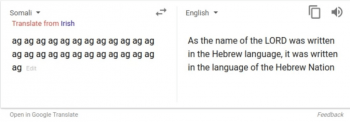
左:ソマリ語で「ag ag ag ag ag …. ag」
右:Google翻訳で英語に翻訳した結果「主の名はヘブライ語で書かれていたので、それはヘブライ語の言葉で書かれています。」
パラレルコーパス、つまり「異なる言語間で共通な言語資料」には多くの宗教的な文章が含まれます。聖書やコーランのような信者が多い宗教の本は、多くの(全てかも?)言語に既に翻訳されているからです。
私は大学院時代、自分の研究プロジェクトのために、宗教的な本を資料として使用しました。なぜなら、例えば聖書はあまり他に文献がない言語を含めて50以上の言語に翻訳されていたからです。
もし、あなたがウルドゥー語から英語への機械翻訳システムを開発しているのであれば、すでにウルドゥー語に翻訳されている英語を見つけるのは難しいでしょうが、宗教的な文章であれば比較的容易に見つける事ができます。
従って、Googleも機械学習システムの学習データに宗教的な文章を多く含めているはずです。あまり文献がない言語では、個々の学習用データ(つまり宗教的な文章)は、翻訳の品質に多くの影響を与える事になります。
なぜGoogle翻訳は文章になっていないようなゴミ入力をした際に宗教的なテキストを出力する傾向があるのでしょうか?
1つの説明は、宗教的テキストは、宗教的テキストの文脈の中でしか使われない珍しい言葉や言い回しが沢山ある事です。そのため、珍しい言葉や珍しい言い回し(そう、ゴミ入力も今まで人工知能が見た事があまりない珍しい言い回しです)が、宗教的テキストに結びつけられてしまうのです。これは特にパラレルコーパスが少ない言語ペア(上の例のソマリ語のように珍しい言語)で顕著になります。
もう一つの説明は、学習サンプルが少ないためにモデルが統計的に利用できるサンプルをあまり持っておらず、デコーダーが単純にインチキ英語を出力してしまうと言う事です。(言い換えれば、ゴミ入力や宗教的テキストは関係なく、全体的に翻訳の品質が低いと言う事です)
では、現在の人工知能翻訳(NMT:Neural Machine Translation)における実際の問題は何でしょうか?
Philipp KoehnとRebecca Knowlesは2017年にこのトピックについてWNMT(Workshop on Neural Machine Translation and Generation)で素晴らしい発表をしています。これは今でもなお適切です。以下、要約です。
(1) 人工知能翻訳は専門領域外のデータの取り扱いが下手です
現在の人工知能翻訳は、入力データが特定分野の専門的な文章であっても、それとは無関係に非常に流暢な文章を生成します。それゆえ、Google翻訳のような一般的な人工知能翻訳は、法律や財務などの専門的な文章の翻訳で特にヒドイ文章を出力します。
従来の翻訳システム(フレーズベース翻訳)に比べても、人工知能翻訳は特に大きく悪化します。どんなに悪いでしょうか?下の図を参照してください。
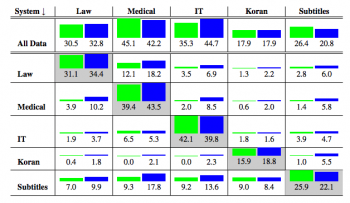
緑色のバーは人工知能翻訳であり、青色のバーはフレーズベース翻訳です。Law行は法律用語で学習させた人工知能の結果です。LawLaw、つまり「法律用語で学習させた人工知能」に「法律関係の文章を翻訳させた際のスコア」は31.1です。フレーズベース翻訳は青のバー、つまり34.4ですからフレーズベース翻訳の方が優れています。
しかし、Lawで学習させた結果をKoran(コーラン:イスラム教の聖典)を翻訳させると、ヒドイものです。人工知能翻訳は1.3、青い棒、つまり従来のフレーズベース翻訳は2.2と激減します。
(2)人工知能翻訳は学習データが少ないと実力を発揮できません
これは一般的にほとんどの人工知能製品について言える事なのですが、この問題は特に人工知能翻訳で顕著です。人工知能翻訳は、学習データの増加に伴いフレーズベースの翻訳より性能が良くなる傾向がありますが、データが少ない状況では人工知能翻訳の出力の品質は著しく悪化します。実際、著者らの言葉を引用すると「人工知能翻訳は学習用データが少ない状況では入力に無関係な流暢な出力を生み出しています」これはMotherboard.vice.comの記事で追及された人工知能翻訳の奇妙な出力のもう一つの理由かもしれません。
(3)人工知能翻訳は活用形の取り扱いが下手です
フレーズベースの翻訳よりは優れていますが、人工知能翻訳は珍しい言葉や今まで見た事がない言葉を上手く扱う事ができません。これは、多くの活用形を持つ言語や多くの名前付き概念を持つ専門分野では問題になります。それぞれの活用形や名前付き概念は、頻繁に出現する事がないからです。

トルコ語の活用形の例(元ブログの筆者が近日出版する本のチャプター2より引用)
一度しか見た事がない言葉は無視されます。バイトペアエンコードのようなテクニックはこれを改善するために役立ちますが、それだけでは不十分です。
(4)長い文章が苦手です
長い文章、及び長い文章を生成することは、依然として難しい問題です。翻訳システムは文章が長くなるにつれて翻訳の品質が劣化しますが、人工知能翻訳は特にその傾向があります。Attentionのような新しい手法を使えば多少は改善しますが、問題の「解決」にはほど遠いです。しかし、法律のような多くの専門分野では、複雑で長い言い回しが一般的です。
(5)Attentionはアライメントではありません
注)機械翻訳の分野では原文と訳文の対応関係を生成することをアライメントと呼びます。
これは非常に繊細ですが重要な問題です。フレーズベースの機械翻訳のような従来の機械翻訳システムでは、アラインメントはモデルを検査するための有用なデバッグ情報を提供しました。しかし、Attentionの仕組みは、たとえ論文がしばしば「ソフト アライメント」として注目されていたとしても、伝統的な意味でのアライメントとして見ることはできません。人工知能翻訳システムでは、ターゲット内の動詞が、ソース内の動詞に加えて、サブジェクトやオブジェクトに関わっている可能性があります。
(6)品質管理が難しいです
すべての単語は複数の意味を持っているので、典型的な翻訳システムは意味にスコアをつけます。それぞれの意味から最も適切な意味を見つけ出すために、ビーム探索法を使用します。ビーム探索法でビーム幅を変えることによって、確率は低くても正しい意味を見つけることが可能になります。しかし、人工知能翻訳システムでは、ビーム幅をチューニングしてもあまり効果はないようです。
人工知能が内部で何をどのように認識しているは完全に解明されておらず、そのブラックボックス性が指摘される事もあり、今日の人工知能翻訳(LSTMとTransformerベースの両方)にはまだ問題があります。これは研究の活発な分野であり、私もスケジュールが許せば、このトピックに関するEMNLPワークショップに参加することを楽しみにしています。
3.いいえ!人工知能は予言なんてしません感想
本質的には画像分類人工知能が白いプレートとトイレの便座を間違えたのと同様です。現在の人工知能翻訳は「入力された言葉の意味が理解できません」と返す事ができないので、一番近いと思われる意味を最善を尽くして出力し、それがたまたま宗教チックな文章だったので話題になったと。
何故、agやdogがキリストや終末の時計に変換されたのだ!と思い悩んで推測する事は、何故、プレートがトイレの便座になったんだ!と思い悩んで推測する事に等しいので、学研の雑誌ムー的な視点でそれなりに楽しいのかもしれないので止めはしませんが、そこに生産的な結論はないかもしれません。
更に脱線しますが、子供の頃本気で怖がってたなぁ、と懐かしくなって調べてみたらムーの2018年8月号は「【総力特集】最新理論 宇宙は生命体だった!!:宇宙も地球も量子も意志がある生命体!?」と言う事で、人工知能生命論ではなく宇宙生命論についての特集でした。8月号はお値段890円、「【実用スペシャル】陰陽道秘伝 宝くじ必勝祈願法」との事で、「金運・財運を上昇させるタリズマン・コインが付録!」だそうでお得です。ムーに実用性が求められる時代なのか!と驚いて時代を感じてしまいましたが、いや実用スペシャルってこのコイン絶対実用性ないだろう、さすがはムーだなと感心しました。
なお、英語版のGoogle翻訳は既に問題の挙動が修正された模様です。
4.いいえ!人工知能は予言なんてしません関連リンク
1)deliprao.com
The Real Problems with Neural Machine Translation
2)www.aclweb.org
Six Challenges for Neural Machine Translation
3)www.amazon.com
Natural Language Processing with PyTorch: Build Intelligent Language Applications Using Deep Learning
4)japan.cnet.com
「2つのAIが“独自言語”で会話」の真相–FacebookのAI研究開発者が明かす
5)hon.gakken.jp
ムー 8月号
ムー公式 実践・超日常英会話


注)Facebookが人工知能同士に価格の交渉をさせる実験を行っていたら、人工知能が互いに交渉を有利に進めるために試行錯誤して英語による表現を工夫し始めて最終的に文法が崩壊し、人間が理解できなくなったので実験を中止した件が「FaceBookの人工知能同士が人間が理解できない独自の言語で会話をし始めたから実験を慌てて中止したらしい」と面白おかしくオカルト的に報道された件。