
1.iterative co-tokenization:動画内でボウルに注がれた2番目の食材が何か答えられるようにする(2/2)まとめ
・反復的共同トークン化アルゴリズムは他の最新モデルよりも性能とサイズに優れる
・計算量も他の手法よりも低く抑える事が可能でX3Dモデルよりも2倍以上効率がよい
・V空間と時間の関係についての質問に答えるためにマルチストリーム入力が重要
2.co-tokenizationによる性能の向上
以下、ai.googleblog.comより「Efficient Video-Text Learning with Iterative Co-tokenization」の意訳です。元記事は2022年8月9日、AJ PiergiovanniさんとAnelia Angelovaさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Brooke Lark on Unsplash
効率的なビデオ質問回答
ビデオと言語の反復的共同トークン化アルゴリズムを、MSRVTT-QA、MSVD-QA、IVQAという3つの主要なVideoQAベンチマークに適用し、この手法が他の最新モデルよりも優れた結果を達成し、かつサイズが控えめであることを実証しました。
更に、反復的な共同トークン化学習により、ビデオ-テキスト学習タスクの計算量を大幅に削減することができます。この手法は67ギガFLOPs(GFLOPS)しか使用しません。これは、一般的な3D-ResNetビデオモデルをテキストと併用する場合に必要な360GFLOPSの6分の1であり、X3Dモデルよりも2倍以上効率がよいです。これは、最先端の手法を凌駕する高精度の結果を出しながら達成した数値です。
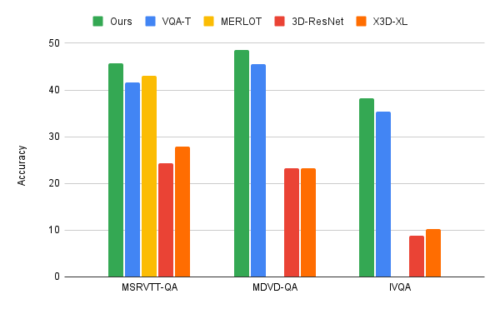
MERLOTやVQA-Tなどの従来手法、およびResNet-3DやX3D-XLを用いたベースラインと、反復的共同トークン化手法の比較
マルチストリームビデオ入力
VideoQAやビデオ入力を伴う他の多くのタスクでは、空間と時間の関係についての質問に正確に答えるために、マルチストリーム入力が重要であることが分かっています。
本手法では、解像度とフレームレートの異なる3つのビデオストリームを使用します。
低解像度で高フレームレートの入力ビデオストリーム(毎秒32フレーム、空間解像度64×64、これを32x64x64とします)、高解像度で低フレームレートのビデオ(8x224x224)、その中間のもの(16x112x112)です。
3つのストリームを処理することで、一見すると情報量が多くなるにもかかわらず、反復的な共同トークン化アプローチにより、非常に効率的なモデルが得られています。
同時に、これらの追加ストリームにより、最も適切な情報を抽出することができます。
例えば、下図に示すように、時間内の特定の活動に関連する質問は、解像度は低いがフレームレートの高いビデオ入力で高い活性度を生じますが、一般的な活動に関連する質問は、フレーム数が非常に少ない高解像度入力から答えることが可能です。このアルゴリズムのもう一つの利点は、質問によってトークン化が変化することです。
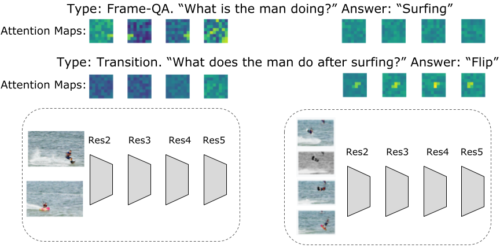
ビデオとテキストの共同トークン化時にレイヤーごとに学習されたAttentionマップの可視化同じビデオでも質問によってAttentionマップは異なります。例えば、質問が一般的な活動(例えば、上の図ではサーフィン)に関連している場合、高解像度低フレームレート入力のAttentionマップはよりアクティブで、よりグローバルな情報を考慮しているように見えます。
一方、質問がより具体的である場合、例えば、あるイベントの後に何が起こるかを尋ねる場合、特徴マップはより局所的で、高フレームレートのビデオ入力がアクティブになる傾向があります。さらに、低解像度高フレームレートのビデオ入力は、ビデオ内の活動に関連する情報をより多く提供していることがわかります。
まとめ
私達はビデオ-言語学習への新しいアプローチとして、ビデオとテキストによる入力情報を横断する共同学習に焦点を当てたものを紹介します。私達は、ビデオ質問回答という重要かつ困難なタスクに取り組みます。私達のアプローチは、より効率的であるにも関わらず、現在の最先端モデルを凌駕する高い効率性と精度を有しています。
私達のアプローチは控えめなモデルサイズで結果を出し、より大きなモデルやデータで更なる改善を得ることができます。私達は、この研究が視覚-言語学習におけるさらなる研究のきっかけとなり、視覚に基づくメディアと滑らかに相互作用が可能にすることを期待しています。
謝辞
この研究は、AJ Pierviovanni, Kairo Morton, Weicheng Kuo, Michael Ryoo 及び Anelia Angelovaによって実施されました。本研究の共同研究者、そして貴重なコメントと提案をいただいた Soravit Changpinyo、提案とサポートをいただいたClaire Cuiに感謝します。また、Tom Smallによる視覚化にも感謝します。
3.iterative co-tokenization:動画内でボウルに注がれた2番目の食材が何か答えられるようにする(2/2)関連リンク
1)ai.googleblog.com
Efficient Video-Text Learning with Iterative Co-tokenization
2)arxiv.org
Video Question Answering with Iterative Video-Text Co-Tokenization

