
1.Teaching BERT to Wait:「え~」や「あ~」を識別して言語モデルのパフォーマンスを向上(1/2)
・インタビューなどの自然なスピーチは文章にすると流暢でない箇所があり読みにくい
・機械学習を使って話し言葉中の非流暢な箇所を特定し余分な単語を削除する事できた
・これにより文章を読みやすくし、自然言語処理アルゴリズムの性能向上も達成できた
2.話し言葉内のフィラーを識別
以下、ai.googleblog.comより「Identifying Disfluencies in Natural Speech」の意訳です。元記事は2022年6月30日、Dan WalkerさんとDan Lieblingさんによる投稿です。
「ええと~」や「あの~」等の会話中に出てくる意味を持たないつなぎ言葉を「fillする物(間を埋める物)」の意から、フィラー(filler)と言いますが、日本語ではフィラーに相当する言葉って無いですね。
アイキャッチ画像のクレジットはPhoto by Dorrell Tibbs on Unsplash
人は、話し言葉と同じように書くことはありません。書き言葉はコントロールされた意図的なものですが、インタビューなどの自然なスピーチを転記した文章は、スピーチの乱れや流暢でない箇所があるため、読みにくいのです。特に読みにくいのは、自己修正、繰り返し、間を埋める言葉(「うーん」、「つまりね」等)など、非流暢な部分です。以下は、LDC CALLHOMEコーパスに含まれる、非流暢さ(disfluency)を含む話し言葉の例です。
「しかし、それは……違うんだ、違うんだ、それは、えーと、これは先ほどの言葉遊びのようなものなんだ。(But that’s it’s not, it’s not, it’s, uh, it’s a word play on what you just said.)」
この文章を理解するには時間がかかります。聞き手は余計な単語をフィルタリングし、すべてのnotが何を意味するか解決しなければなりません。流暢でない言葉を取り除くことで、この文章はずっと読みやすく、理解しやすくなります。
「しかし、これは先ほどの言葉遊びのようなものなんだ。」
人々は通常、日常会話では非流暢さに気づきませんが、計算言語学の初期の基礎研究により、非流暢さがいかに一般的であるかが明らかになりました。1994年、Elizabeh ShribergはSwitchboardコーパスを用いて、10-13語の文に50%の確率で非流暢さが含まれ、その確率は文の長さとともに増加することを実証しました。
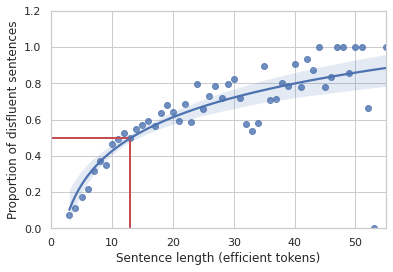
Switchboardデータセットから、少なくとも1つの非流暢さを含む文の割合を、文中の非非流暢さ(つまり効率的)なトークンで測定した文の長さに対して図にしたものです。文が長くなればなるほど、非流暢性が含まれる可能性が高くなります。
論文「Teaching BERT to Wait: Balancing Accuracy and Latency for Streaming Disfluency Detection」では、話し言葉を転記した文章を「クリーンアップ」する方法について研究成果を発表しています。
私たちは、人の話し言葉の中の非流暢さを発見し、それを取り除くことで、より読みやすい原稿と説明文を作成します。ラベル付けされたデータを使って、機械学習(ML:machine learning)アルゴリズムを作成し、人の話し言葉の中の非流暢さを特定しました。
その結果、余分な単語を削除し、読みやすい原稿にすることができました。また、自然言語処理(NLP:natural language processing)アルゴリズムの性能も向上させることができます。私たちの研究は、これらのモデルがモバイルデバイスで動作することを保証することに特に重点を置いており、ユーザーのプライバシーを保護し、ネットワーク通信が難しい状況でもパフォーマンスを維持することができます。
ベースモデルの概要
ベースモデルの中核は、1億890万のパラメータを持つ事前学習済みのBERT BASEエンコーダです。標準的なトークン分類器設定を使用し、バイナリ分類ヘッドに各トークンのシーケンスエンコーディングが供給されます。
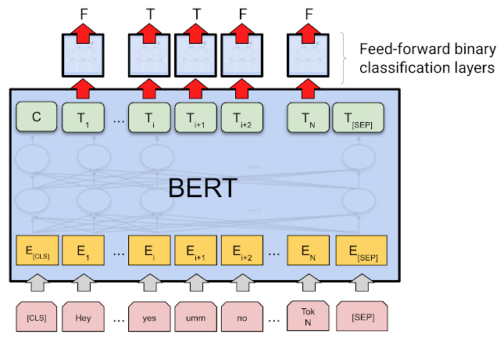
テキスト中のトークンが数値のembeddingsとなり、それが出力ラベルとなるイメージ図
2019年からPushrift Redditデータセットのコメントを使って事前学習を継続し、BERTエンコーダを改良しました。Redditのコメントは音声データではありませんが、wikiや書籍のデータよりもくだけた会話的な文章です。これにより、くだけた言語をよりよく理解するためにエンコーダを訓練できますが、データに固有の偏見などを学んでしまうリスクを冒す可能性があります。しかし、私達の特定の用例では、このモデルはテキストの内容ではなく、構文や全体的な形式を捉えるだけなので、データの意味レベルの偏見に関連する潜在的な問題を回避することができます。
私達は、上記のSwitchboardコーパスのような手書きラベル付けコーパスの流暢性分類のために、モデルを微調整しました。ハイパーパラメータ(バッチサイズ、学習率、学習エポック数など)は、Vizierを用いて最適化した。
また、「自己学習(self training)」と呼ばれる知識抽出の手法を用いて、モバイルデバイスで使用するための様々な「小型」モデルを作成しています。私達の最高の小型モデルは、310万のパラメータを持つSmall-vocab BERTの変種をベースにしています。この小型モデルは、1%のサイズ(MiB単位)でベースラインと同等の結果を達成しました。このモデルの小型化を実現した方法については、2021年のInterspeechの論文で詳しく説明されています。
3.Teaching BERT to Wait:「え~」や「あ~」を識別して言語モデルのパフォーマンスを向上(1/2)関連リンク
1)ai.googleblog.com
Identifying Disfluencies in Natural Speech
2)arxiv.org
Teaching BERT to Wait: Balancing Accuracy and Latency for Streaming Disfluency Detection

