
1.L2P:継続学習にプロンプトを導入してコンパクトな記憶を実現(1/2)まとめ
・継続学習はデータ分布が変化する状況で単一のモデルを学習する手法で破局的忘却がネック
・従来手法は過去データをリハーサルバッファに格納して現在のデータと混ぜて学習させる
・L2Pは継続的に再学習せずタスク関連のプロンプトを学習して継続学習を行う新手法を提供
2.Learning to Promptとは?
以下、ai.googleblog.comより「Learning to Prompt for Continual Learning」の意訳です。元記事は2022年4月19日、Zifeng WangさんとZizhao Zhangさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Jed Villejo on Unsplash
教師あり学習は、機械学習(ML:Machine Learning)の一般的なアプローチで、手元のタスクに対して適切にラベル付けされたデータを用いてモデルを学習させるものです。通常の教師あり学習は独立同分布(IID:Independent and Identically Distributed)データで学習します。この場合、すべての学習事例は決まったクラスの集合から抽出され、モデルは学習段階全体を通じてこれらのサンプルにアクセスできます。
これに対して、継続学習(continual learning)は、変化するデータ分布に対して単一のモデルを学習する問題であり、異なる分類課題が順次提示されます。これは、例えば、実世界のシナリオにおいて、自律型エージェントが連続的な情報の流れを処理し、解釈することを可能にするために特に重要です。
教師あり学習と継続学習の違いを説明するために、2つの課題を考えてみましょう。
(1)ネコとイヌの分類
(2)パンダとコアラの分類
です。IIDを用いた教師あり学習では、モデルは両タスクの学習データを与えられ、1つの4クラス分類問題として扱います。しかし、継続学習では、これら2つのタスクは順次到着し、モデルは現在扱っているタスク用の学習データにしかアクセスできません。その結果、このようなモデルでは、前のタスクに対する性能が低下する傾向があります。これは、破局的忘却(catastrophic forgetting)と呼ばれる現象です。
主流の解決策は、過去のデータを「リハーサルバッファ(rehearsal buffer)」にバッファリングし、現在のデータと混ぜてモデルを学習させることで、破局的忘却に対処しようとするものです。
しかし、これらの解決策の性能はバッファのサイズに大きく依存し、場合によっては、データのプライバシーに関する懸念から、全く不可能なこともあります。別の研究分野では、タスク間の干渉を避けるために、タスク固有のコンポーネントを設計します。しかし、これらの方法は、テスト時のタスクが既知であることを前提とすることが多く、必ずしもそうではない事、また、多くのパラメータを必要とすることが特徴です。これらのアプローチの限界は、継続学習にとって重要な問題を提起します。
(1)過去のデータのバッファリングにとどまらない、より効果的でコンパクトな記憶システムは可能か?
(2)そのタスクの正体を知ることなく、任意のサンプルに対して、関連する知識コンポーネントを自動的に選択することは可能か?
CVPR2022で発表された論文「Learning to Prompt for Continual Learning」では、これらの疑問に対する回答を試みています。
自然言語処理におけるプロンプト技術からヒントを得て、Learning to Prompt(L2P)と呼ばれる新しい継続学習の枠組みを提案します。
L2Pでは各タスクのモデル重みを継続的に再学習する事はしません。その代わりに、事前トレーニングされたバックボーンモデルに指示として、タスク関連の「指示」(つまり、プロンプト)を提供します。学習しながらプロンプトを貯め込み、ため込んだプロンプトを用いてタスクを実行します。
L2Pは様々な困難な継続学習の設定に適用可能であり、全てのベンチマークにおいて一貫して従来の最先端手法を凌駕しています。また、リハーサルに基づく手法に対して競争力のある結果を達成するとともに、よりメモリ効率が高いです。最も重要なことは、L2Pがプロンプトの概念を継続学習の分野に初めて導入したことです。
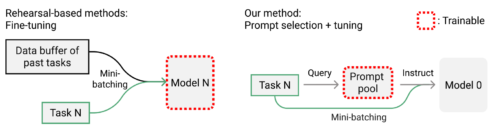
L2Pは、リハーサルバッファを用いてモデルの全体または一部の重みをタスクに逐次適応させる一般的な手法に比べ、凍結した1つの基幹モデルを用い、条件付きでモデルを指示するプロンプトプールを学習します。「モデル0」は、基幹モデルが最初から固定されていることを示します。
プロンプトプールと実体単位のクエリ
事前に学習されたTransformerモデルが与えられると、「プロンプトベースの学習(prompt-based learning)」は固定されたテンプレートを使って元の入力を修正します。
例えば、感情分析タスクに「I like this cat」という入力が与えられたとしましょう。プロンプトベースの手法は入力を「I like this cat. It looks X.」ここで「X」は予測される空のスロット(例えば、「nice」、「cute」など)であり、「It looks X」はいわゆるプロンプトです。入力にプロンプトを追加することで、事前学習させたモデルに条件を追加して、多くの下流タスクを解決することができます。
固定プロンプトの設計には試行錯誤と予備知識が必要ですが、プロンプトチューニングでは、入力embeddingに学習可能なプロンプトのセットを付加し、事前学習済みのバックボーンに単一の下流タスクを学習するように転移学習させます。
3.L2P:継続学習にプロンプトを導入してコンパクトな記憶を実現(1/2)関連リンク
1)ai.googleblog.com
Learning to Prompt for Continual Learning
2)arxiv.org
Learning to Prompt for Continual Learning

