
1.LiT:画像エンコーダを凍結してマルチモーダルな対象学習の性能を向上(2/2)まとめ
・転移学習は精度は高いがタスク毎に手間がかかり対照学習はその逆で性能面に難があった
・LiTは画像エンコーダの学習をロックする事でこの性能ギャップを半分埋める事ができた
・LiTは他にも堅牢性やデータ効率が向上し選考する対照手法研究に対して優位性がある
2.Locked-Image Tuningの性能
以下、ai.googleblog.comより「Locked-Image Tuning: Adding Language Understanding to Image Models」の意訳です。元記事は2022年4月14日、Andreas SteinerさんとBasil Mustafaさんによる投稿です。
今回のLiTの発見はGAN等の二つのニューラルネットワークを組み合わせる手法にも横展開が出来そうですね。また、人間が様々な事柄を基礎から応用に段階的に学習/訓練していくのはニューロ効率に優れているのでしょうか。
アイキャッチ画像のクレジットはPhoto by Jakob Owens on Unsplash
画像特徴表現を固定したチューニングで二兎を得る
前述したように、転移学習(transfer learning)は最先端の精度を達成しますが、タスク毎にラベル、データセット、学習が必要です。一方、対照学習(contrastive models)は柔軟性があり、規模拡大可能で、新しいタスクに容易に適応できますが、性能面では劣ります。例えば、本稿執筆時点では、転移学習を用いたImageNetの分類は90.94%ですが、対照学習型のゼロショットモデルでは76.4%となっています。
LiTチューニングはこのギャップを埋めるもので、事前に学習された画像エンコーダから得られる強力な特徴表現とよく一致する特徴表現を計算するためにテキストモデルを対照的に学習します。重要なのは、これがうまく機能するためには、画像エンコーダを「ロック(lock)」すること、つまり、学習中に更新してはいけないということです。
これは直感的でないかもしれません。なぜなら、人は通常、さらなる訓練による追加情報によって性能が向上すると考えるからです。しかし、私達は画像エンコーダをロックすることで、より良い結果が得られることを発見しました。
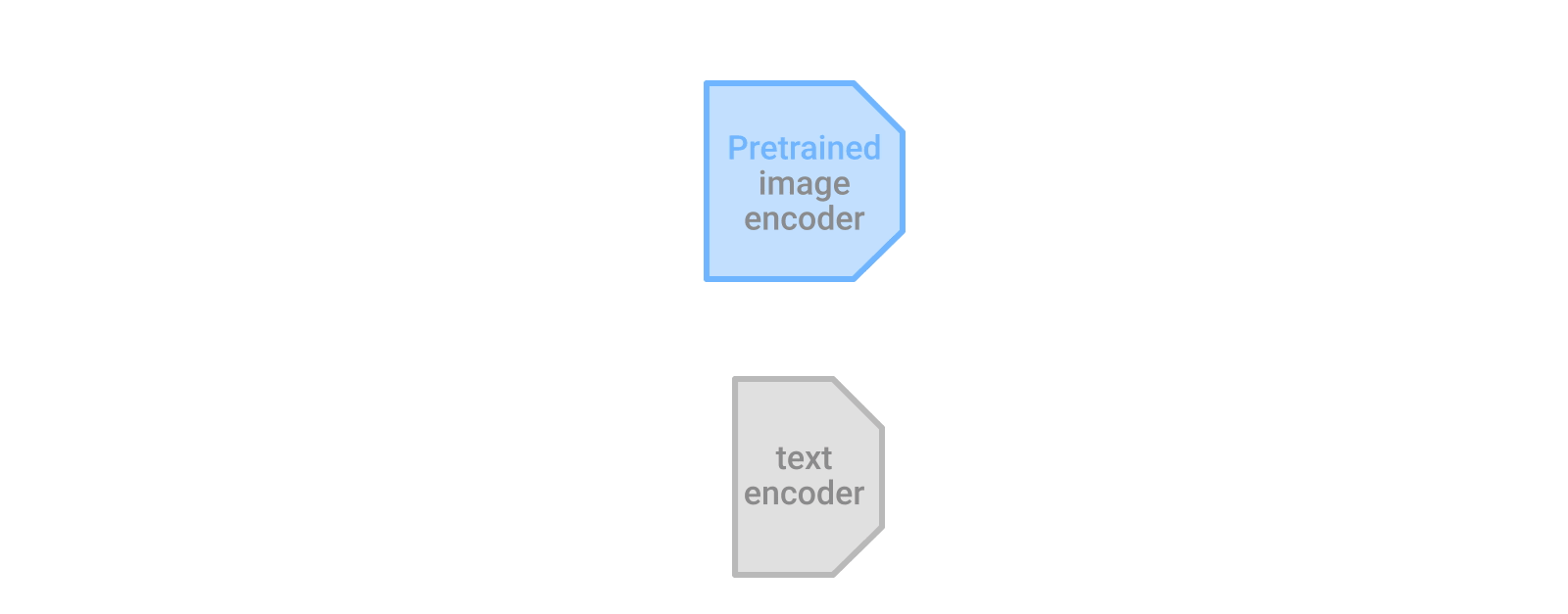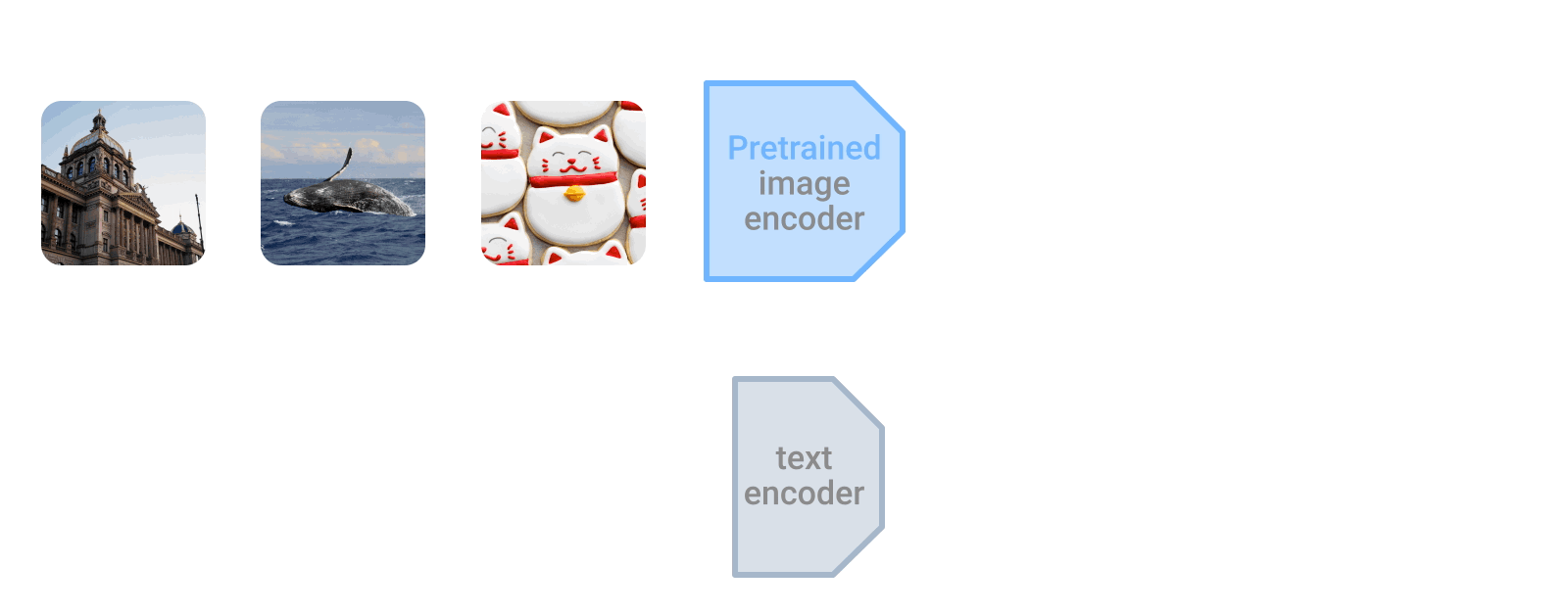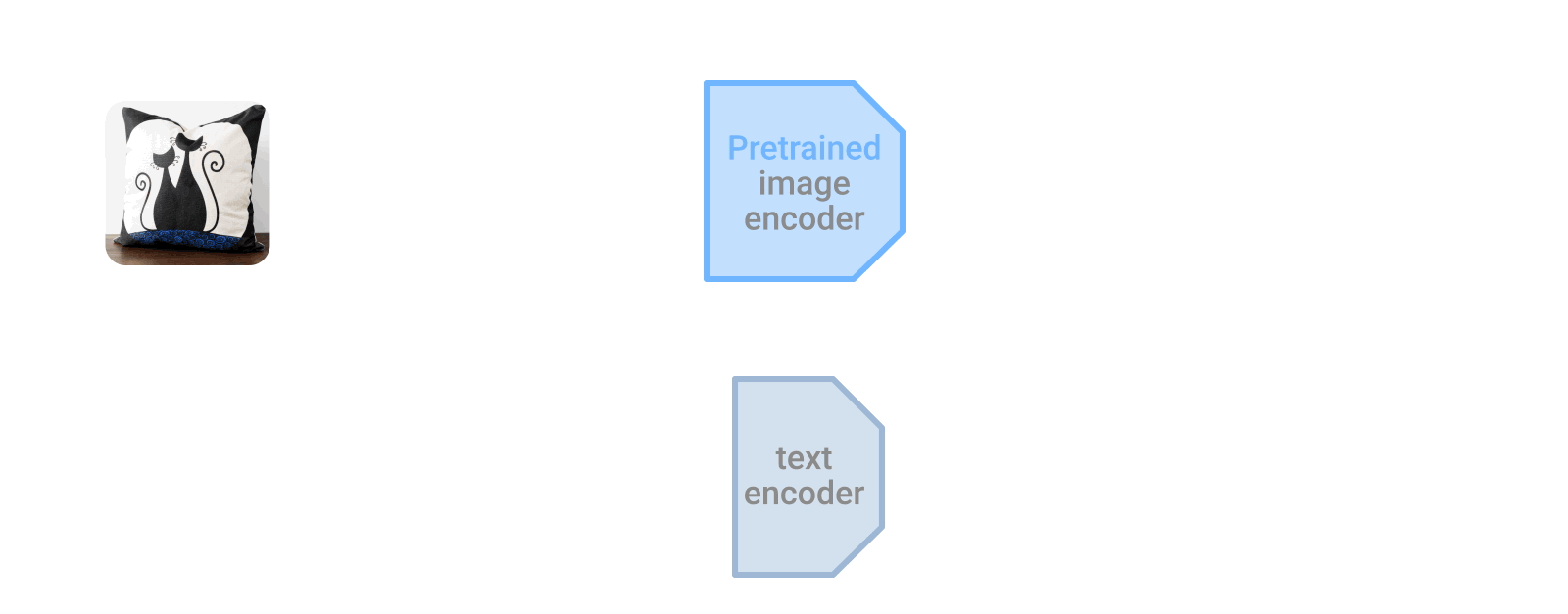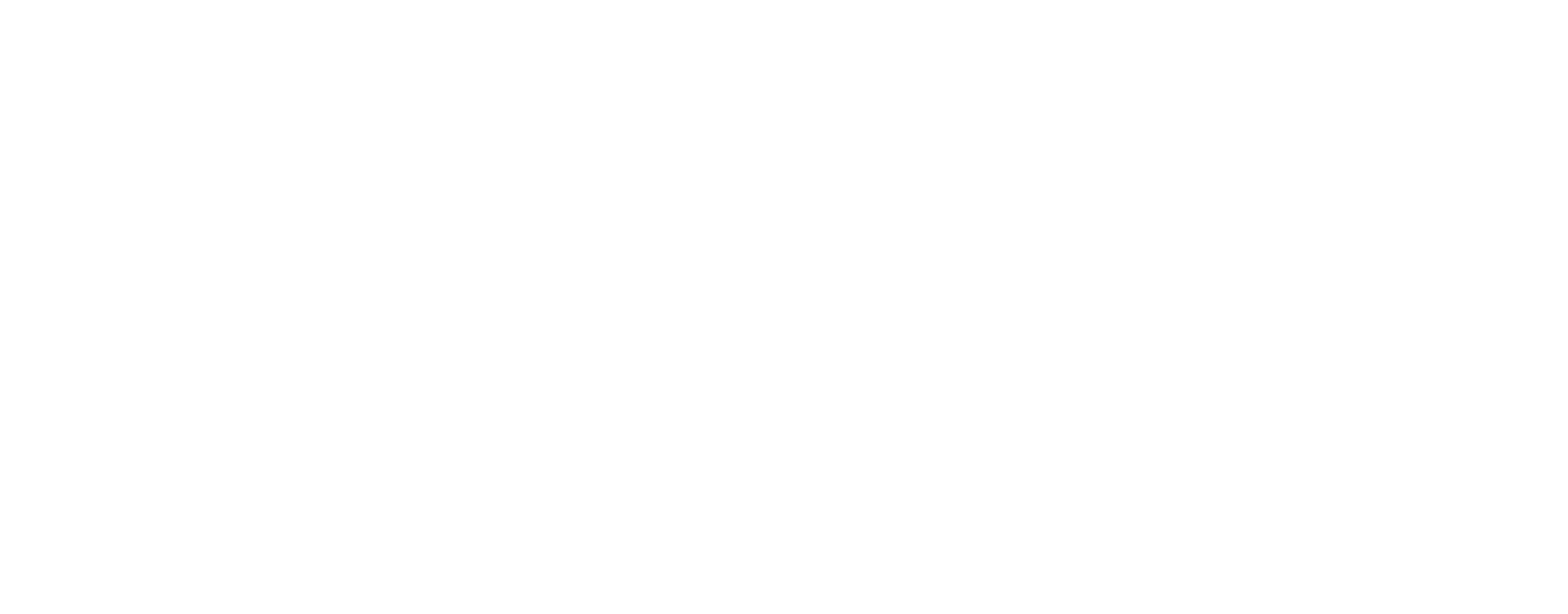
LiT-tuningは、事前に学習した画像エンコーダとテキストエンコーダを対照的に学習させます。テキストエンコーダーは、画像エンコーダーの特徴表現に近い特徴表現を計算するように学習します。
微調整は画像エンコーダを新しい分類タスクごとに個別に適応させますが、LiT-Tuningは一回でどのようなデータでも分類できるようにするので、微調整の代替と考えることができます。
LiT-tuningで調整されたモデルは、ImageNetの分類において84.5%のゼロショット精度を達成し、モデルを一から学習する従来の方法よりも大幅に向上し、微調整と対照学習の間の性能差を半減させました。
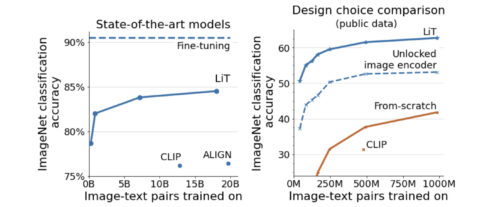
左:LiT-tuningにより、対照手法の最良モデルとラベルで微調整した最良モデルとの差が大幅に縮まります。
右:学習済みの画像エンコーダの使用は常に有効です。事前に学習した画像エンコーダの使用は常に有用ですが、それをロックすることが成功への鍵であることに驚かされます。ロックされていない画像モデル(破線)は著しく低いパフォーマンスをもたらします。
対照モデルの印象的な利点は、堅牢性の向上です。ObjectNetやImageNet-Cなど、一般的に微調整されたモデルが苦手とするデータセットでも高い精度を維持することができます。同様に、LiT-tuningされたモデルは、ObjectNetで81.1%の最新精度を達成するなど、様々なバージョンのImageNetで高い性能を発揮します。
LiT-tuningには他にも利点があります。先行する対照手法研究では、大量のデータと非常に長い学習時間を必要としますが、LiTアプローチではデータ消費量を大幅に削減することができます。一般に公開されている2,400万の画像とテキストの組で学習したLiTモデルは、非公開の4億の画像とテキストの組で学習した先行モデルのゼロショット分類性能に匹敵します。また、ロックされた画像エンコーダは、より小さなメモリ容量でより高速な学習を可能にします。
そのため、より大きなデータセットで、画像特徴表現を事前に計算することができます。そして、学習中に画像モデルを実行しないことで、効率が向上し、また、より大きなバッチサイズを利用できるようになります。これは、モデルが見る「ネガティブ」の数を増やし、高性能な対照学習を実現する鍵となります。この方法は、様々な形式の画像事前学習(例えば、自己教師付き学習など)や、一般に入手可能な多くの画像モデルでうまく機能します。これらの利点により、LiTが研究者にとって素晴らしい実験プラットフォームとなることを期待しています。
まとめ
私達はLocked-image Tuning(LiT)を発表しました。これは、事前に学習された強力な画像エンコーダから得た画像特徴表現に合わせてテキストエンコーダを対照的に学習させるものです。この単純な方法は、データと計算の効率が良く、既存の対照学習アプローチと比較して、ゼロショット分類性能を大幅に向上させることができます。

デモ画面
自由形式のテキスト説明文と画像のマッチングに使用し、あなた自身のゼロショット分類器を構築してください。
LiTでチューニングしたモデルをブラウザでお試しいただけるよう、小さなインタラクティブ・デモを用意しました。また、より高度なユースケースと大規模なモデルを含むColabも提供しています。
謝辞
LiTの論文の共著者であり、その開発のあらゆる側面に関わったXiaohua Zhai, Xiao Wang, Daniel Keysers, Alexander Kolesnikov, Lucas Beyer、およびZürichのBrainチームに感謝します。また、このブログ記事で使用されているアニメーションを作成してくれたTom Smallに感謝します。
3.LiT:画像エンコーダを凍結してマルチモーダルな対象学習の性能を向上(2/2)関連リンク
1)ai.googleblog.com
Locked-Image Tuning: Adding Language Understanding to Image Models
2)arxiv.org
LiT: Zero-Shot Transfer with Locked-image text Tuning
3)google-research.github.io
LiT: Zero-Shot Transfer with Locked-image Tuning

