
1.ALX:大規模な行列計算をTPU上で実現(1/3)まとめ
・行列分解を使う手法は単純ではあるが性能が良いので推薦システムなどに昔から使われている
・ALSは行列分解のパラメータを学習するための基本的なアルゴリズムで規模拡大の効率が良い
・利用可能なTPUコアの数を拡張することで大規模行列分解問題に対応できる分散ALS設計を探求
2.ALXとは?
以下、ai.googleblog.comより「Large-Scale Matrix Factorization on TPUs」の意訳です。元記事は2022年4月8日、Harsh Mehtaさんによる投稿です。
映画のMatrix(行列)をイメージしたアイキャッチ画像のクレジットはPhoto by Brian Wangenheim on Unsplash
行列因子分解(Matrix factorization)は、ユーザーの評価から曲や映画などのアイテムを推薦する方法を学習するための、最も古い技術の1つですが、今でも広く使用されています。
その基本的な形式は、ユーザーとアイテムの関係を表現する大きな疎な(つまり、ほとんどの項目が空の)行列を、アイテムとユーザーの特徴を表す2つの小さな密な行列の積で近似するものです。これらの密な行列は、ユーザがまだ接触したことのないアイテムをユーザに推薦するために利用されます。
行列分解はアルゴリズムが単純であるにもかかわらず、推薦システムの能力を図るベンチマークとして、競争力のあるパフォーマンスを達成することができます。
交互最小二乗法(ALS:Alternating least squares)、特にその陰的変形(implicit variation)は、行列分解のパラメータを学習するための基本的なアルゴリズムです。ALSは行、列、非ゼロの項目数に応じて線形に規模拡大できるため、高い効率性で知られています。
したがって、このアルゴリズムは大規模な課題に非常によく適しています。しかし、非常に大規模な実世界の行列分解データセットの場合、単一マシンでは性能が不十分であるため、大規模な分散システムが必要になります。ALSを用いた行列分解の分散実装のほとんどは、既製のCPUデバイスを利用しており、問題が本質的に疎(入力行列がほとんど空)である事から、当然のように利用されています。
一方、近年の深層学習の成功は、計算能力の向上を示しており、TPU(Tensor Processing Units)などのハードウェアアクセラレータの研究と進歩に新たな波を起こしました。TPUは、特に密な行列演算を大量に行う深層学習のようなユースケースにおいて、専用ハードウェアを使った高速化を可能にします。
特に、SPMD(Single Program Multiple Data)方式でSGD(Stochastic Gradient Descent)を用いてモデルを学習するような従来のデータ並列ワークロードでは、大幅な高速化を実現することが可能です。
SPMDアプローチは、勾配降下アルゴリズムによるニューラルネットワークのトレーニングなどの計算で人気を博しています。SPMDは、データ並列計算とモデル並列計算の両方に使用でき、利用可能なデバイスにモデルのパラメータを分散させることができます。
とはいえ、TPUはSGDに基づく手法にとって非常に魅力的ですが、多数の分散スパース行列乗算を必要とするALSを高性能に実現し、TPUデバイスの大規模クラスタ向けに開発できるかどうかは、すぐには明らかになりません。
論文「ALX: Large Scale Matrix Factorization on TPUs」では、TPUアーキテクチャを効率的に利用し、利用可能なTPUコアの数を拡張することで数十億の行や列の行列分解問題に対応できる分散ALS設計を探求しています。
私たちが提案するアプローチは、モデル並列とデータ並列の組み合わせを活用し、各TPUコアがembeddingテーブルの一部を保存し、ミニバッチにグループ化されたデータのユニークなスライスに対して学習を行うものです。大規模な行列分解手法に関する今後の研究に拍車をかけるため、また、私たち自身の実装のスケーラビリティ特性を説明するために、私たちはWebGraphという実世界のウェブリンク予測データセットも構築し、公開しました。
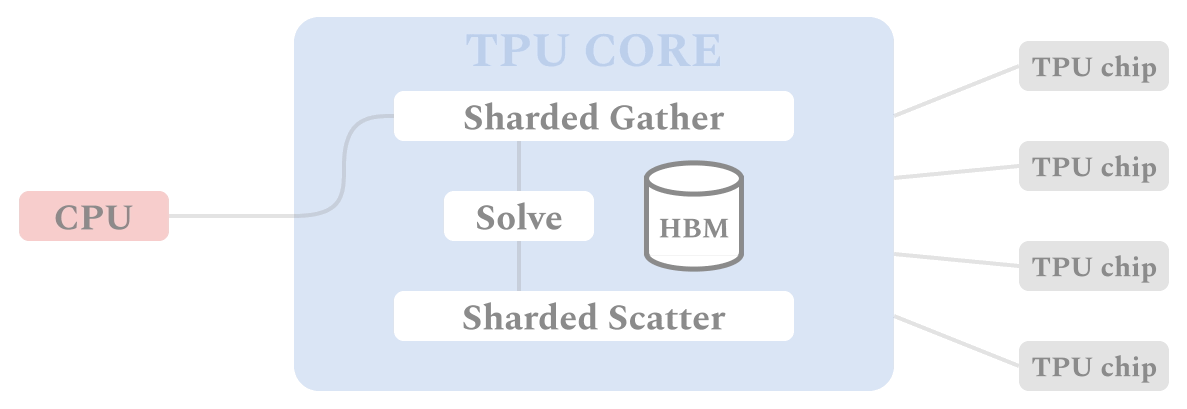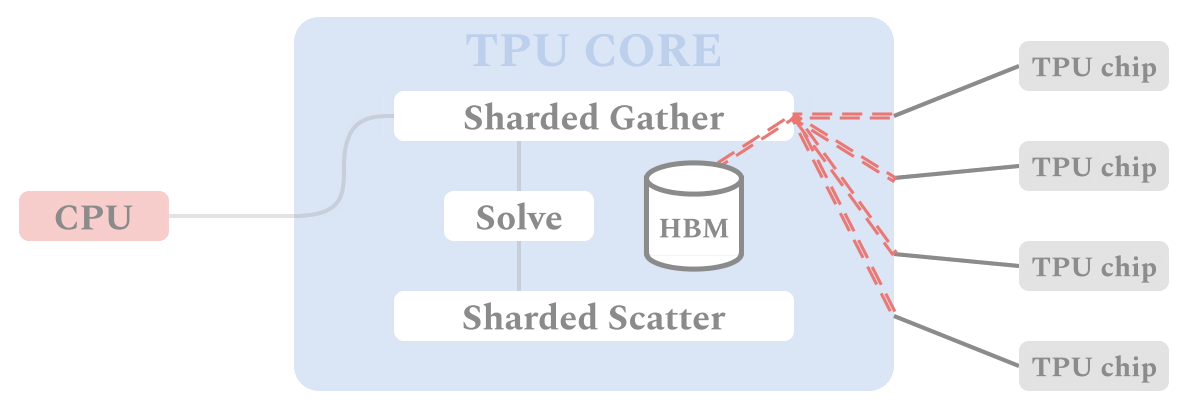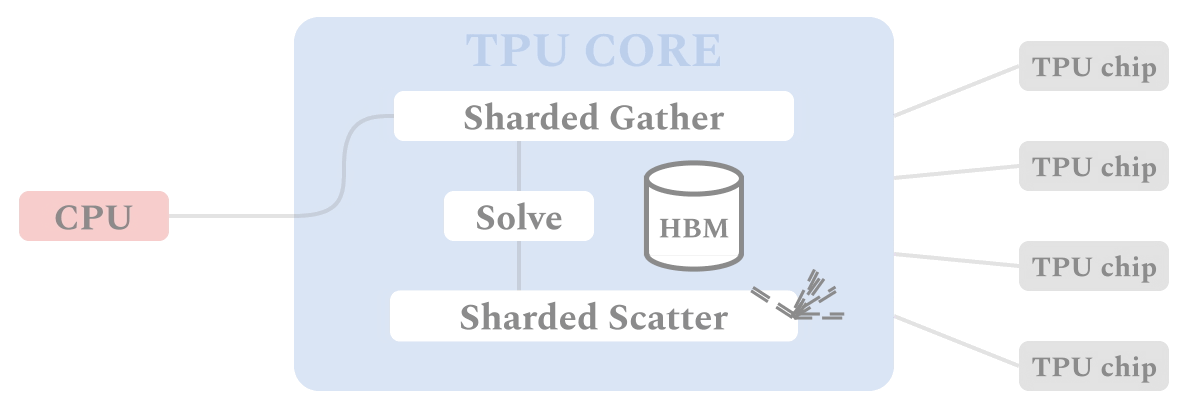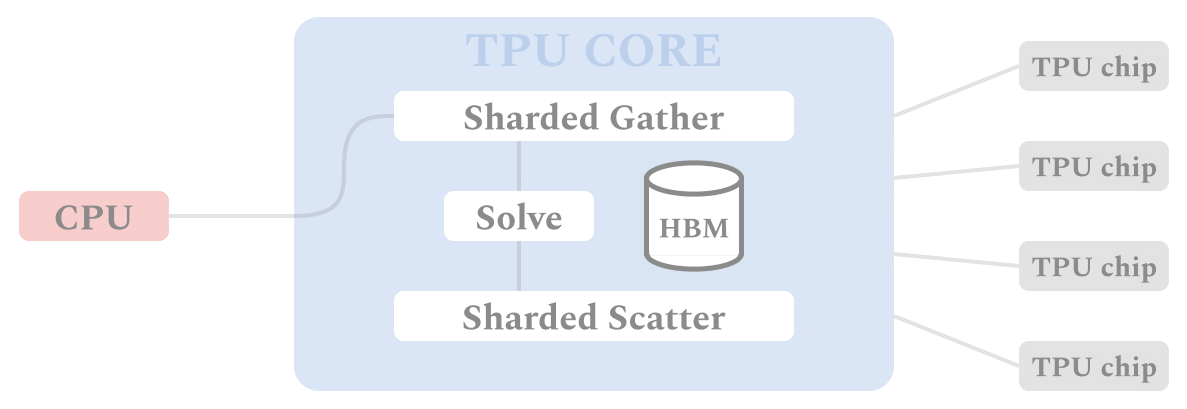
図は、TPUデバイス上のALXフレームワークを介したデータと計算の流れを示しています。SGDベースの学習手順と同様に、各TPUコアは自身が担当するバッチ用のデータに対してSPMD方式で同一の計算を行うため、複数のTPUコアで並行して同期計算を行うことが可能です。各TPUは、まずSharded Gatherステージで関連するアイテムのembeddingをすべて収集します。これらの実体化したembeddingは、ユーザembeddingを解くために使われます。ユーザembeddingは、Sharded Scatterステージで、embeddingテーブルと関連するシャードに散らばっています。
高密度バッチによる効率性の向上
私たちはALXをTPU向けに特別に設計し、TPUアーキテクチャのユニークな特性を利用しながら、いくつかの興味深い制限を克服しています。例えば、TPUの各コアはメモリに制限があり、全てのテンソルは固定的な形状に制限されていますが、ミニバッチの各サンプルは項目数が大きく変化します(つまり、入力が長いので、疎になる可能性があります)。これを解決するために、非常に長いサンプルを同じ形状の複数の小さなサンプルに分割します。これを密なバッチング(dense batching)と呼びます。密なバッチングの詳細については、論文を参照してください。
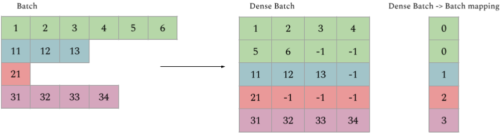
TPUでの効率を上げるために疎なバッチを高密度化した例
3.ALX:大規模な行列計算をTPU上で実現(1/3)関連リンク
1)ai.googleblog.com
Large-Scale Matrix Factorization on TPUs
2)arxiv.org
ALX: Large Scale Matrix Factorization on TPUs
3)github.com
google-research/alx/
4)www.tensorflow.org
web_graph

