
1.MBT:動画における新しいモダリティ融合モデル(3/3)まとめ
・少数のattentionボトルネックを使用しても計算量はそれほど大きく増えずほぼ一定に保たれる
・MBTの融合ボトルネックは画像のより小さな領域にAttentionを集中させることを強いている
・融合ボトルネックでattentionを制限することで最先端のスコアと計算量削減を達成できた
2.厳しいボトルネックの効果
以下、ai.googleblog.comより「Multimodal Bottleneck Transformer (MBT): A New Model for Modality Fusion」の意訳です。元記事は2022年3月15日、Arsha Nagrani さんとChen Sunさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Andrew Seaman on Unsplash
素のクロスアテンション(vanilla cross-attention)とボトルネック融合(bottleneck fusion)の計算量をGFLOPsで比較しました。少数のattentionボトルネック(私達の実験では4つのボトルネックトークンを使用)を使用することで、後期融合モデルにわずかな計算が追加される事になりますが、計算量は融合レイヤーを変えてもほぼ一定に保たれます。
これは素のクロスアテンションとは対照的です。素のクロスアテンションを適用するとレイヤーごとに無視できない計算コストが発生します。私達は、早期融合において、ボトルネック融合は、半分以下の計算コストで、視聴覚音分類において2以上の平均平均精度ポイント(mAP)で素のクロスアテンションを上回ることに注目しています。
音声分類と行動認識に関する結果
MBTは、一般的なビデオ分類タスクである音声分類(AudioSetとVGGSound)とアクション認識(KineticsとEpic-Kitchens)において、先行研究よりも優れた性能を発揮しています。複数のデータセットにおいて、後期融合とMBTと中期融合(音声と視覚の両方を融合)は、最良のスコアを出す単一モダリティモデルを上回り、中期融合のMBTは後期融合を上回ります。

複数のデータセットにおいて、音声と視覚を融合したマルチモダリティモデルは単一モダリティモデルを上回り、中期融合モデルのMBTは後期融合モデルを上回りました。各データセットについて、広く使われている主要な指標を使用しています。すなわち、Audioset: mAP、Epic-Kitchens: Top-1 アクション精度、VGGSound、Moments-in-Time、Kinetics: Top-1 分類精度です。
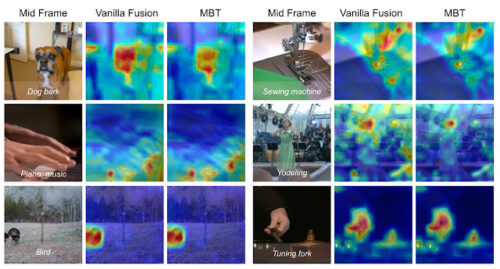
Attentionヒートマップの可視化
MBTの挙動を理解するために、Attentionロールアウトテクニックに従ってネットワークが計算したAttentionを可視化しました。
AudioSetテストセットにおける素のクロスアテンションモデルとMBTについて、出力分類トークンから画像入力空間へのAttentionのヒートマップを計算しました。
各ビデオクリップについて、左側にオリジナルをMIDフレーム、画像下部に検証済ラベルを重ねて表示しています。特に、ピアノの指先、ミシン、犬の顔など、動きがあり、音を出す画像領域にAttentionが集まっていることがわかります。MBTの融合ボトルネックは、さらに、左上の犬の口や右側中段の歌っている女性など、画像のより小さな領域にAttentionを集中させることを強いています。これは、MBTが、音声分類タスクに関連し、音声との中間融合から恩恵を受ける画像断片にのみ注目するよう、厳しいボトルネックを強制していることを示す証拠です。
概要
マルチモーダル融合のための新しいtransformerベースのアーキテクチャであるMBTを紹介し、ボトルネックトークン間のクロスアテンションを用いた様々な融合アプローチを検討しました。その結果、融合ボトルネックの小さなセットを介してクロスモーダルなattentionを制限することで、多くのビデオ分類ベンチマークにおいて最先端の結果を達成するとともに、素のクロスアテンションモデルと比較して計算コストを削減できることを実証しました
謝辞
本研究は、Arsha Nagrani、Anurag Arnab、Shan Yang、Aren Jansen、Cordelia Schmid、Chen Sunによって実施されました。ブログ記事はArsha Nagrani、Anurag Arnab、Chen Sunによって書かれました。アニメーションは、Tom Smallが制作しました。
3.MBT:動画における新しいモダリティ融合モデル(3/3)関連リンク
1)ai.googleblog.com
Multimodal Bottleneck Transformer (MBT): A New Model for Modality Fusion
2)arxiv.org
Attention Bottlenecks for Multimodal Fusion
3)github.com
scenic/scenic/projects/mbt/

