
1.Shift-Robust GNN:データの偏りに堅牢なグラフニューラルネットワーク(2/3)まとめ
・データセットの分布の変化と分類精度の間に強い負の相関があり変化に伴い性能が劣化
・シフト堅牢正則化器で学習サンプルとラベルなしデータサンプルの分布ずれを最小化
・モデルの学習中にリアルタイムで領域シフトを測定しバイアスを無視するように強制
2.分布の変化と分類精度の相関
以下、ai.googleblog.comより「Robust Graph Neural Networks」の意訳です。元記事は2022年3月8日、Bryan PerozziさんとQi Zhuさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Johnny Briggs on Unsplash
分布シフトが性能に与える影響
分布の変化がGNNの性能にどのように影響するかを示すために、まず、既知の学術データセットを使って、偏った学習セットを多数生成しました。次に、その効果を理解するために、分布シフト(CMD:Central Moment Discrepancyで計測)と汎化性能(テスト精度)の関係をグラフ化します。
例えば、よく知られているPubMedの引用データセットを考えてみましょう。これは、ノードが医学研究論文で、エッジがそれらの間の引用を表すグラフと考えることができます。PubMedの偏った学習データを作成すると、次のような図になります。
ここでは、データセットの分布の変化と分類精度の間に強い負の相関があることが観察されます。CMDが増加すると、性能(F1)は減少します。つまり、GNNは学習データがテストデータセットと似ていないため、汎化が困難になっている可能性があります。
そこで、私達はシフト堅牢正則化器(shift-robust regularizer、領域不変学習(domain-invariant learning)と同様のアイディア)を提案します。これは「学習に使うサンプル」と「ラベルなしデータから得たIIDサンプル」との間の分布のずれを最小化します。
そのため、モデルの学習中にリアルタイムで領域シフト(CMDなど)を測定し、これに基づいて直接ペナルティを適用し、モデルに学習バイアスを可能な限り無視するように強制します。これにより、モデルが学習データから学習する特徴表現エンコーダーは、異なる分布に由来するラベルのないデータに対しても効果的に機能するようになります。
下図は、従来のGNNモデルと比較した場合のイメージです。同じ入力(ノードの特徴Xと隣接行列A)、同じレイヤー数です。しかし、GNNのレイヤー(k)から得る最終embedding Zkは、モデルが正しく符号化されていることを確認するために、ラベルのないデータ点からのembeddingと比較されます。
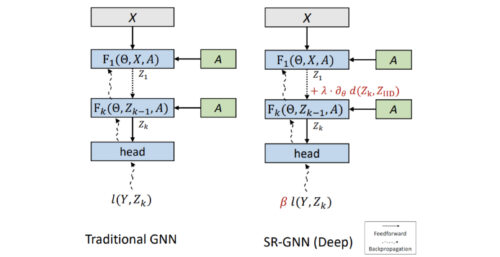
SR-GNNは、ディープGNNモデルに2種類の正則化を加えます。まず、領域シフト正則化(λ項)は、ラベル付き(Zk)データとラベルなし(ZIID)データの隠れ特徴表現間の距離を最小化します。第二に、サンプルのインスタンス重み(instance weight)(β)を変更することで、真の分布をさらに近似させることができます。
私達はこの正則化を、学習データの特徴表現と真のデータの分布の間の距離に基づくモデル損失に関する公式の追加項として記述します(完全な公式は論文内で入手可能)
3.Shift-Robust GNN:データの偏りに堅牢なグラフニューラルネットワーク(2/3)関連リンク
1)ai.googleblog.com
Robust Graph Neural Networks
2)proceedings.neurips.cc
Shift-Robust GNNs: Overcoming the Limitations of Localized Graph Training Data(PDF)

PubMedデータセットにおける分布シフトの効果
100個の偏った学習セットサンプルについて、性能(F1)をy軸に、分布シフトを中心モーメント不一致(CMD)をx軸に示しています。分布シフトが大きくなると、モデルの精度は低下します。