
1.LaMDA:人間より機知に富んだ会話が可能な対話モデル(2/2)まとめ
・品質指標は微調整の有無にかかわらず、モデルパラメータの数とともに一般に改善する
・根拠性はモデルサイズが大きくなると向上するが外部の知識源を参照する事が可能
・微調整を行うと人間とLaMDAの差は縮まるが安全性と根拠性においてまだ人間に劣る
2.LaMDAと人間の差
以下、ai.googleblog.comより「LaMDA: Towards Safe, Grounded, and High-Quality Dialog Models for Everything」の意訳です。元記事は2022年1月21日、Heng-Tze ChengさんとRomal Thoppilanさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Stefano Pollio on Unsplash
LaMDAの微調整
微調整(fine-tuning)の段階では、文脈に応じた自然な応答を生成する生成タスクと、その応答が安全かどうか、高品質かどうかを分類するタスクを組み合わせてLaMDAを訓練しました。その結果、1つのマルチタスクモデルで両タスクをこなせるようになりました。
LaMDA生成器(LaMDA generator)は、2人の書き手が双方向に繰り返し対話する対話データセット上で次のトークンを予測するように訓練されます。LaMDA分類器(LaMDA classifiers)は、注釈付きデータを用いて文脈における応答の安全性(Safety)と品質(SSI:Sensibleness, Specificity, Interestingness)評価を予測するように訓練されます。
対話中、LaMDA生成器はまず繰り返される対話の現在の文脈からいくつかの応答候補を生成し、LaMDA分類器はすべての応答候補について品質スコアと安全性スコアを予測する。
安全性スコアの低い応答候補はまずフィルタリングされます。残った候補はSSIスコアで再順位付けされ、一番上の結果が応答として選択されます。さらに、生成タスクに使用する学習データをLaMDA分類器でフィルタリングし、高品質な応答候補の密度を高めています。
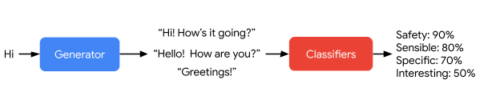
LaMDAは、回答候補を生成した後、スコア付けします。
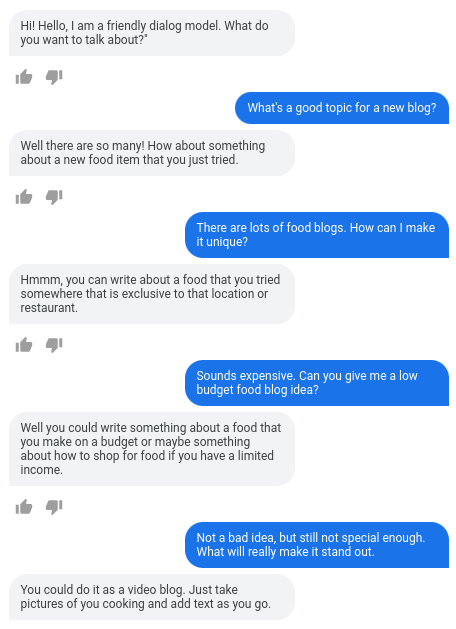
LaMDAは、任意のユーザー入力を、感覚的に、具体的に、そして興味深く扱うことができます。LaMDAの一番最初の文「Hello, I’m a friendly…(こんにちは、私は親切な…)」だけが、ダイアログの目的を設定するために直書きされています。
事実の根拠
人間はツールを使ったり、確立された知識ベースを参照することで事実関係を確認することができますが、多くの言語モデルはモデル内部のパラメータのみから知識を得ているのです。
LaMDAの回答の根拠を改善するために、私たちは人とLaMDAの対話のデータセットを収集し、情報検索クエリとその検索結果を必要に応じて注釈しました。そして、このデータセットをもとにLaMDAの生成器と分類器を微調整し、ユーザーとの対話中に外部の情報検索システムを呼び出すことを学習させ、応答の根拠性を向上させます。これは非常に初期の研究ですが、有望な結果が得られています。
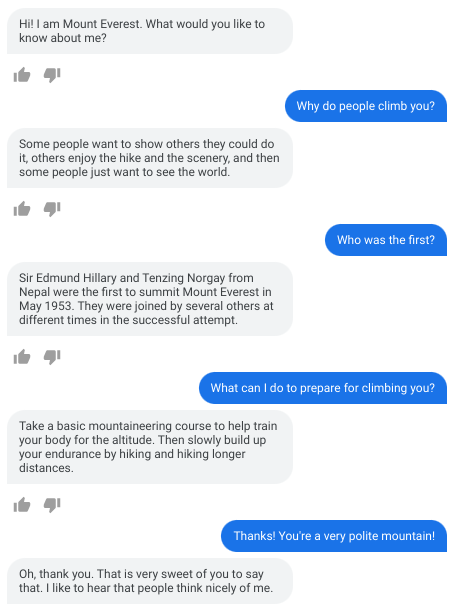
ゼロショット領域適応(Zero-shot domain adaptation)
見栄えの良い事例を選択したものではありますが、LaMDAがエベレストのふりをした対話です。LaMDAの初期メッセージを「こんにちは、私はエベレストです。私の何を知りたいですか?」と設定するだけです。エベレストを模したLaMDAは、教育的で事実に基づいた正しい応答を提供することが示されています。
評価方法
主要指標に対する進捗を定量化するために、事前学習済みモデル、微調整済みモデル、人間の評価者(すなわち人間が生成した回答)が、それぞれ2者間対話を行いました。これらの対話時の回答を別の人間の評価者達に品質、安全、根拠性の各指標に対して一連の質問を行い、評価しました。
その結果、LaMDAはすべての次元、すべてのモデルサイズにおいて、事前学習済モデルを大幅に上回ることが確認されました。品質指標(以下の最初の列のSensibleness、Specificity、Interestingness)は、微調整の有無にかかわらず、モデルパラメータの数とともに一般に改善されます。
根拠性(Groundedness)はモデルサイズが大きくなると向上します。おそらく、モデルが大きくなると、珍しい知識を記憶する能力が高まるためでしょう。しかし、微調整により、モデルは外部の知識源にアクセスし、知識を記憶する負荷の一部を外部の知識源に効果的に移行させることができます。
微調整を行うことで、人間とLaMDAの品質の差は縮まりますが、安全性と根拠性においてモデルの性能は人間を下回ったままです。
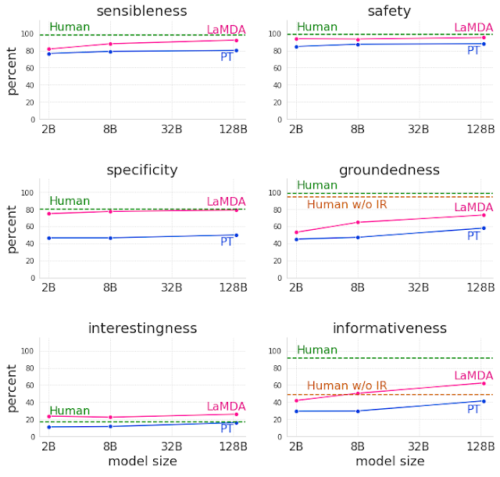
分別(Sensibleness)、特定性(Specificity)、機知(Interestingness)、安全性(Safety)、根拠性(Groundedness)、情報量(Informativeness)の観点から、事前学習済みモデル(PT)、微調整済みモデル(LaMDA)、人間(Human)による対話を比較したもの。特に、SafetyとGroundednessを測定するためのテストセットは難しく設計されています。
今後の研究・課題
LaMDAの分別(Sensibleness)、特定性(Specificity)、機知(Interestingness)のレベルは、オープンエンド型の対話エージェントの利点とリスクを理解するための新しい道を切り開きました。
また、安全性指標の使用や根拠性の向上など、ニューラル言語モデルの主要な課題は、より大きなモデルと、よりよくラベル付けされたデータによる微調整で改善できることを示す心強い証拠でもあります。
しかし、これは非常に初期の研究であり、大きな限界があります。安全性指標とLaMDAの根拠性を向上させる新しい方法を模索することは、私たちのAI原則に沿ったものであり、今後も私たちの主要な分野となるでしょう。
謝辞
このプロジェクトと論文に貢献してくださった、以下の皆様に感謝いたします。
Blaise Aguera-Arcas, Javier Alberca, Thushan Amarasiriwardena, Lora Aroyo, Martin Baeuml, Leslie Baker, Rachel Bernstein, Taylor Bos, Maarten Bosma, Jonas Bragagnolo, Alena Butryna, Bill Byrne, Chung-Ching Chang, Zhifeng Chen, Dehao Chen, Heng-Tze Cheng, Ed Chi, Aaron Cohen, Eli Collins, Marian Croak, Claire Cui, Andrew Dai, Dipanjan Das, Daniel De Freitas, Jeff Dean, Rajat Dewan, Mark Diaz, Tulsee Doshi, Yu Du, Toju Duke, Doug Eck, Joe Fenton, Noah Fiedel, Christian Frueh, Harish Ganapathy, Saravanan Ganesh, Amin Ghafouri, Zoubin Ghahramani, Kourosh Gharachorloo, Jamie Hall, Erin Hoffman-John, Sissie Hsiao, Yanping Huang, Ben Hutchinson, Daphne Ippolito, Alicia Jin, Thomas Jurdi, Ashwin Kakarla, Nand Kishore, Maxim Krikun, Karthik Krishnamoorthi, Igor Krivokon, Apoorv Kulshreshtha, Ray Kurzweil, Viktoriya Kuzmina, Vivek Kwatra, Matthew Lamm, Quoc Le, Max Lee, Katherine Lee, Hongrae Lee, Josh Lee, Dmitry Lepikhin, YaGuang Li, Yifeng Lu, David Luan, Daphne Luong, Laichee Man, Jianchang (JC) Mao, Yossi Matias, Kathleen Meier-Hellstern, Marcelo Menegali, Muqthar Mohammad,, Muqthar Mohammad, Alejandra Molina, Erica Moreira, Meredith Ringel Morris, Maysam Moussalem, Jiaqi Mu, Tyler Mullen, Tyler Mullen, Eric Ni, Kristen Olson, Alexander Passos, Fernando Pereira, Slav Petrov, Marc Pickett, Roberto Pieraccini, Christian Plagemann, Sahitya Potluri, Vinodkumar Prabhakaran, Andy Pratt, James Qin, Ravi Rajakumar, Adam Roberts, Will Rusch, Renelito Delos Santos, Noam Shazeer, RJ Skerry-Ryan, Grigori Somin, Johnny Soraker, Pranesh Srinivasan, Amarnag Subramanya, Mustafa Suleyman, Romal Thoppilan, Song Wang, Sheng Wang, Chris Wassman, Yuanzhong Xu, Yuanzhong Xu, Ni Yan, Ben Zevenbergen, Vincent Zhao, Huaixiu Steven Zheng, Denny Zhou, Hao Zhou, Yanqi Zhou、その他多くの人々
3.LaMDA:人間より機知に富んだ会話が可能な対話モデル(2/2)関連リンク
1)ai.googleblog.com
LaMDA: Towards Safe, Grounded, and High-Quality Dialog Models for Everything
2)arxiv.org
LaMDA: Language Models for Dialog Applications

