
1.Fast WordPiece Tokenization:WordPieceによるトークン化を高速に実行(1/2)まとめ
・自然言語処理アプリケーションではトークン化が基本的な前処理ステップとなる
・WordPieceが良く使われているトークン化手法だが何十年も前から進歩があまりない
・WordPieceより計算の複雑さを一桁減らし最大で8倍速い新手法を新たに開発した
2.トークン化を高速に実行する新手法
以下、ai.googleblog.comより「A Fast WordPiece Tokenization System」の意訳です。元記事の投稿は2021年12月10日、Xinying SongさんとDenny Zhouさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Towfiqu barbhuiya on Unsplash
トークン化(Tokenization)は、ほとんどの自然言語処理(NLP:natural language processing)アプリケーションの基本的な前処理ステップです。
トークン化にはテキストをトークン(単語や単語の断片など)と呼ばれる小さな単位に分割する事が含まれます。これにより構造化されていない入力文字列を機械学習(ML:Machine Learning)モデルが取り扱いやすい形式に変換する事ができます。
深層学習ベースのモデル(BERTなど)では、各トークンがembeddingベクトルにマッピングされ、モデルに入力されます。
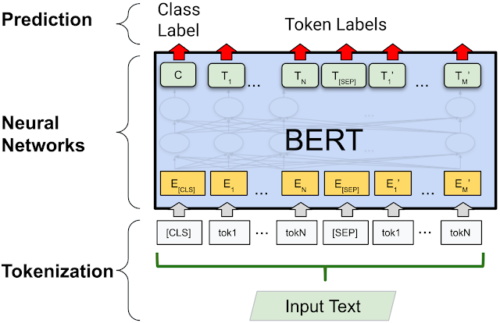
BERTのような典型的なディープラーニングモデルでのトークン化処理
トークン化の基本的なアプローチは、テキストを単語に分割することです。しかし、この方法では、あらかじめ定めた語彙リスト内に含まれていない単語は「未知(unknown)」として扱われてしまいます。
現在の自然言語処理モデルでは、テキストをサブワード(subword)単位にトークン化することでこの問題に対処しています。
サブワード単位であっても、言語的な意味(形態素など)を保持していることが多いです。そのため、ある単語がモデルにとって未知であっても、個々のサブワード・トークンはモデルがある程度意味を推論するのに十分な情報を保持している場合があります。
WordPieceはこのようなサブワード トークン化手法です。良く使用されており、他の多くの自然言語処理モデルに適用することができます。
テキストが与えられると、WordPiece はまずテキストを(句読点と空白で分割して)単語に事前トークン化し、次に各単語をワードピース(wordpieces)と呼ばれるサブワード単位にトークン化します。
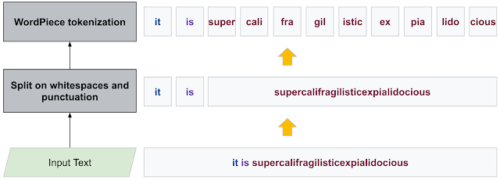
WordPieceによるサブワードトークン化処理の例
EMNLP 2021で発表した論文「Fast WordPiece Tokenization」では、改良したWordPieceトークン化システムを開発しました。これにより入力文章に対して直接トークン化処理を行って高速化し、モデル全体の反応速度を短縮して計算資源を節約する事ができます。
何十年も使われてきた従来のアルゴリズムと比較して、このアプローチでは計算の複雑さを一桁減らし、標準的なアプローチよりも最大で8倍速く、パフォーマンスが大幅に改善されました。このシステムはGoogleの多くのシステムで応用され成功を収めており、TensorFlow Textとして一般に公開されています。
単語をWordPieceの処理概要
WordPieceは単一の単語をトークン化するために、貪欲な最長一致優先戦略(greedy longest-match-first strategy)を使用します。
つまり、モデルの語彙内の単語に一致する、最長の接頭辞を残りのテキストから繰り返し選択します。この方法は最大マッチング(MaxMatch)として知られており、1980年代から中国語の単語分割にも用いられています。
しかし、何十年も前から自然言語処理で広く使われているにもかかわらず、比較的計算量が多く、一般に採用されているMaxMatchアプローチの計算量は入力単語長(n)に対して二次関数的に増加します。
これは、入力を走査する際に2つのポインタが必要なためであす。1つは開始位置をマークし、もう1つはその位置から語彙トークンにマッチする最長の部分文字列を検索するためです。
私たちはWordPieceトークン化に使われるMaxMatchアルゴリズムに代わるLinMaxMatchと呼ばれるアルゴリズムを提案すます。このアルゴリズムはトークン化時間が入力単語長nに対して厳密に線形に増加します。
まず、語彙トークンをトライ木(trie)にまとめます。トライ木はプレフィックス木(prefix tree)も呼ばれます。
トライの各エッジは文字でラベル付けされます。ルートからあるノードまでのツリーパスは、語彙中のあるトークンの接頭辞を表します。
下図では、ノードは円、ツリーエッジは黒い実線矢印で描かれています。トライ木が与えられたとき、ルートからトライ木のエッジをたどり、一文字ずつ入力にマッチする語彙トークンを見つけることができる。このプロセスをトライマッチと言います。
下図は “a”, “abcd”, “##b”, “##bc”, “##z “からなる語彙から作られたトライ木を示しています。
入力テキスト “abcd “は、ルート(左上)から “a”, “b”, “c”, “d “のラベルを持つトライエッジを一つずつたどることでボキャブラリトークンにマッチングさせることができます。(先頭の “##”記号はWordPieceのトークン化で使われる特殊文字です。後述します)
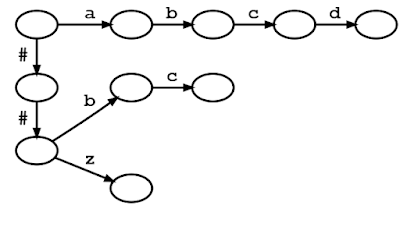
[“a”, “abcd”, “##b”, “##bc”, “##z”]という語彙のトライ木のダイアグラムです。丸と矢印はそれぞれトライ木に沿ったノードとエッジを表します。
第二に、1975年に発明された古典的な文字列探索アルゴリズムであるAho-Corasickアルゴリズムにヒントを得て、与えられた入力にマッチしないトライ木の枝を抜け出し、直接代わりの枝にスキップしてマッチングを継続する手法を導入しました。
標準的なトライ木における照合と同様に、トークン化の際にはトライ木のエッジをたどって入力文字を一つずつ照合していきます。
あるノードで入力文字にマッチングできなかった場合、標準的なアルゴリズムでは、トークンがマッチした最後の文字まで戻り、そこからトライ照合プロセスを再開しますが、これは反復的で無駄な繰り返しとなります。
本手法ではバックトラックの代わりに、失敗時遷移をおこないます。
これは2つのステップで実行されます
(1)そのノードに保存されている事前計算済みのトークンを回収します(これを失敗ポップ(failure pops)と呼びます)
(2)その後、事前計算済みの失敗リンクを辿って新しいノードに行き、そこからトライ木の照合プロセスを継続します。
3.Fast WordPiece Tokenization:WordPieceによるトークン化を高速に実行(1/2)関連リンク
1)ai.googleblog.com
A Fast WordPiece Tokenization System
2)arxiv.org
Fast WordPiece Tokenization
3)github.com
tensorflow / text

