
1.GLaM:1.2兆のパラメータを持ち効率的に学習可能な大規模言語モデル(2/2)まとめ
・GLaMはゼロショットとワンショットで密モデルと比べて競争力のある結果を達成した
・多くのタスクで高いスコアを達成し、推論時も学習時も計算量が少なくて済む
・小規模では同等の性能になるが大規模では密モデルを上回ることも確認された
2.GLaMの性能
以下、ai.googleblog.comより「More Efficient In-Context Learning with GLaM」の意訳です。元記事は2021年12月9日、Andrew M DaiさんとNan Duさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Ashley Piszek on Unsplash
GLaMの評価
学習中に一度もやっていないタスクをやらせるゼロショット設定やワンショット設定を用いました。
評価対象は、
(1) cloze and completion task
(2) Open-domain question answering
(3) Winograd-style task
(4) commonsense reasoning
(5) in-context reading comprehension
(6) SuperGLUE task
(7) natural language inference
といったベンチマークです。
合計8つの自然言語生成タスク(NLG:Natural Language Generation tasks)は生成されたフレーズを検証済みフレーズに対してどれだけ近づけられたかをExact Match(EM)精度とF1メジャーで評価しました。
合計21の言語理解タスク(NLU:Natural Language Understanding tasks)は複数の選択肢から正しいものを条件付き対数尤度(conditional log-likelihood)を使って予測するものです。
タスクの中にはいくつかの変種があり、SuperGLUEは複数のタスクから構成されています。EM精度、F1スコアともに全結果を0から100でスケーリングし、平均化したものが以下のNLGスコアとなります。NLUスコアは、精度とF1スコアの平均値です。
結果
GLaMは、各MoE層が1つのExpertしか持たない場合、基本となる密な(dense)Transformerベースの言語モデル・アーキテクチャに帰着します。
すべての実験において、GLaMモデルを記述するために、(基本となる密なモデルのサイズ) / (MoE層あたりのExpertの数)という表記を採用しました。
例えば、1B/64Eは、10億パラメータの密なモデルのアーキテクチャを表し、他の全ての層は64のExpertを持つMoE層に置き換わっています。以下のセクションでは、同じデータセットで学習したベースラインの密なモデルを含め、GLaMの性能とスケーリング特性について探ります。最近発表されたMegatron-Turingモデルと比較すると、GLaMは推論時に5倍少ない計算量でありながら、5%のブレ幅を許容するならば、7つのタスクで同等になります。
以下では、1.2兆パラメータの疎活性化モデル(GLaM)が、1750億パラメータの密なモデル(GPT-3)よりも平均的かつ多くのタスクで高い結果を達成し、推論時の計算量も少なくて済むことを紹介します。
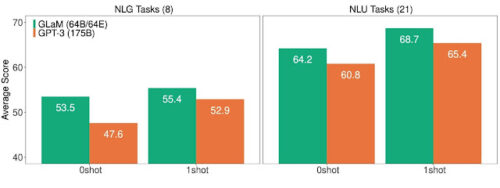
GLaMとGPT-3のNLG(左)とNLU(右)における平均スコア(高いほど良い)。
以下、29のベンチマークについて、密なモデル(GPT-3, 175B)と比較した性能の概要。GLaMは、ゼロショットタスクのほぼ8割、ワンショットタスクのほぼ9割において、密なモデルの性能を超えるか、同程度の性能であることがわかりました。
| Evaluation | Higher (>+5%) | On-par (within 5%) | Lower (<-5%) |
| Zero-shot | 13 | 11 | 5 |
| One-shot | 14 | 10 | 5 |
さらに、GLaMのフルバージョンは1.2兆のパラメータを持ちますが、推論時には1トークンあたり970億パラメータ(1.2兆の8%)のサブネットワークを活性化するだけです。
| GLaM (64B/64E) | GPT-3 (175B) | |
| Total Parameters | 1.162T | 0.175T |
| Activated Parameters | 0.097T | 0.175T |
規模拡大時の動作
GLaMには2つの規模拡大方法があります。
(1)各Expertが1つの計算機内にホストされている場合、層毎にExpertの数を増加させる。
(2)各Expertのサイズを1つのデバイスの限界を超えて増加させる。
規模拡大した際の特性を評価するために、推論時にトークンあたりのFLOPSが同程度のそれぞれの高密度モデル(MoE層ではなくFFN層を持つモデル)と比較します。
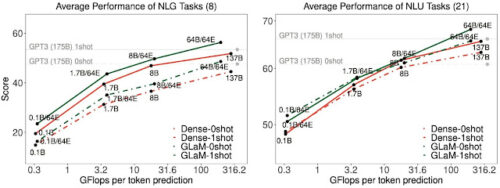
各Expertのサイズを大きくした場合のゼロショットとワンショットの平均性能。Expertサイズが大きくなるにつれ、推論時のトークン予測あたりのFLOPSが増加。
上に示したように、各タスクの性能はExpertのサイズに比例して増大します。GLaMは疎活性化モデルですが、生成タスクの推論時に同等のFLOPsで密なモデルより良い性能を発揮します。言語理解タスクについては、小さい規模では同等の性能を発揮しますが、大きい規模では疎活性化モデルが上回ることが確認されました。
データ効率
大規模な言語モデルの学習は計算量が多いため、消費電力を抑えるためには効率化が有効です。
以下に、GLaMの完全バージョンにおける計算コストを示します。
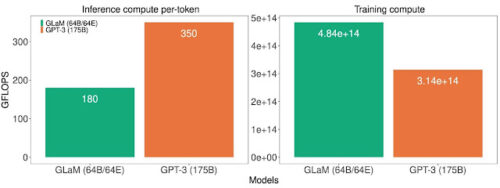
推論、トークン毎の推論時(左)およびトレーニング時(右)の両方のGFLOPSでの計算コスト
これらの計算コストは、GLaMはより多くのトークンを使って学習するため、学習時の計算量が多く、推論時の計算量が大幅に少ないことを示しています。以下に、異なる数のトークンを用いて学習した場合の比較を示します。
また、GLaMの学習曲線も密モデルのベースラインと比較して評価しました。
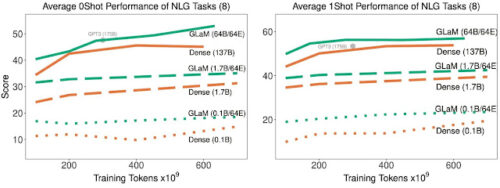
8つの生成タスクにおける、疎活性化モデルと密モデルの平均的なゼロショットとワンショットの性能比較。
学習時に処理されるトークンの数が増えるにつれて向上します。
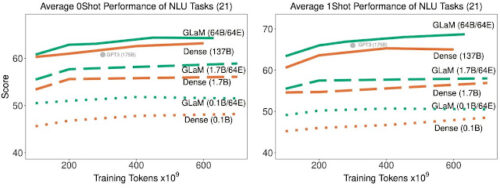
21個の言語理解タスクにおける、疎活性化モデルと高密度モデルの平均的なゼロショットとワンショットの性能比較。
学習時に処理されるトークンの数が増えるにつれて向上します。
上記の結果から、疎活性化モデルがゼロショットとワンショットの性能を同等にするためには、密なモデルよりも大幅に少ないデータで学習すれば良く、同じ量のデータを用いれば、疎活性化されたモデルが大幅に良い性能を示すことがわかりました。
最後に、GLaMのエネルギー効率を評価しました。
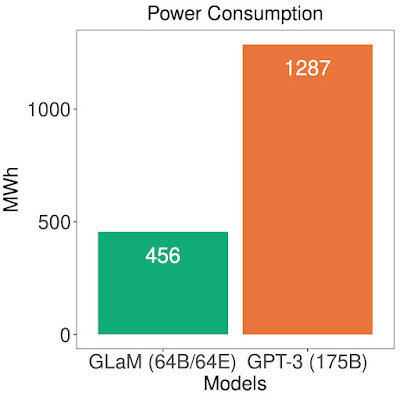
トレーニング時の消費電力比較
GLaMは学習時の計算量が多いものの、GSPMDによる効率的なソフトウェア実装とTPUv4の優位性により、他のモデルよりも学習時の消費電力が少なくなっています。
結論
私たちの大規模疎活性言語モデルであるGLaMは、ゼロショット学習とワンショット学習で競争力のある結果を達成し、先行する画一的な密結合モデルよりも効率的なモデルとなりました。また、大規模言語モデルには高品質なデータセットが不可欠であることを定量的に示しています。私たちの研究が、計算効率の高い言語モデルに関する研究のきっかけとなることを期待しています。
謝辞
Claire Cui, Zhifeng Chen, Yonghui Wu, Quoc Le, Macduff Hughes, Fernando Pereira, Zoubin Ghahramani and Jeff Deanのサポートと貴重な意見に感謝します。
共同研究者に感謝します。Yanping Huang, Simon Tong, Yanqi Zhou, Yuanzhong Xu, Dmitry Lepikhin, Orhan Firat, Maxim Krikun, Tao Wang, Noam Shazeer, Barret Zoph, Liam Fedus, Maarten Bosma, Kun Zhang, Emma Wang, David Patterson, Zongwei Zhou, Naveen Kumar, Adams Yu, Laurent Shafey, Jonathan Shen, Ben Lee, Anmol Gulati, David So, Marie Pellat, Kellie Webster, Kevin Robinson, Kathy Meier-Hellstern, Toju Duke, Lucas Dixon, Aakanksha Chowdhery, Sharan Narang, Erica Moreira and Eric Niには有益な議論とインスピレーションを頂きました。そしてGoogle Research team。
また、この記事で使用されているアニメーション図を提供してくれたTom Smallに感謝します。
3.GLaM:1.2兆のパラメータを持ち効率的に学習可能な大規模言語モデル(2/2)関連リンク
1)ai.googleblog.com
More Efficient In-Context Learning with GLaM
2)arxiv.org
GLaM: Efficient Scaling of Language Models with Mixture-of-Experts

