
1.TokenLearner:柔軟にトークン化する事でVision Transformerの効率と精度を向上(2/2)まとめ
・Vision Transformerはトークンの数が多くなってしまう事がボトルネックとなっていた
・本研究では多数のトークンを保持して完全に処理する必要がないことを説明した
・入力画像に基づいて適応的にトークンを抽出するモジュールを学習させる事で達成可能
2.TokenLearnerの性能
以下、ai.googleblog.comより「Improving Vision Transformer Efficiency and Accuracy by Learning to Tokenize」の意訳です。元記事は2021年12月7日、Michael RyooさんとAnurag Arnabさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Joao Tzanno on Unsplash
TokenLearnerの設置場所
TokenLearner モジュールを構築した後、それをどこに配置するかを決定する必要がありました。まず、224×224の画像を使った標準的なViTアーキテクチャの中のさまざまな場所に配置してみました。
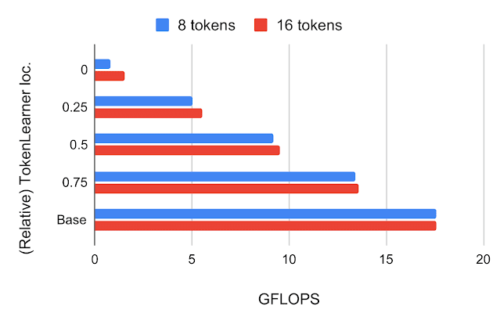
その結果、TokenLearnerが生成したトークンの数は8個と16個で、標準的なViTが使用する196個や576個よりはるかに少なくなりました。下図は、ViT B/16の様々な相対的位置にTokenLearnerを挿入したモデルのImageNet数ショット分類精度とFLOPSを示したもので、16×16のパッチトークンで動作する12 attention layersを持つ基本モデルです。
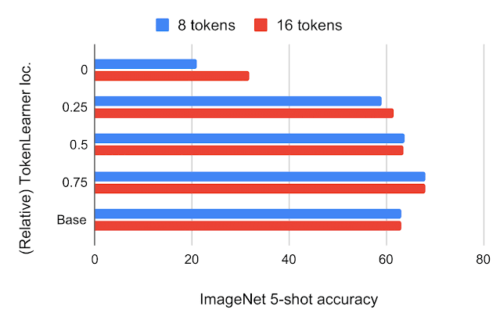
上図:JFT 300Mの事前学習によるImageNet 5-shot転移精度と、ViT B/16内のTokenLearnerの相対位置関係
位置0はTokenLearnerがTransformer層の前に配置されていることを意味します。
BaseはオリジナルのViT B/16です。
下図:計算量は、相対的なTokenLearnerの位置ごとに、十億単位の浮動小数点演算(GFLOPS)で測定されています。
その結果、ネットワークの最初の4分の1以降(1/4時点)にTokenLearnerを挿入すると、ベースラインとほぼ同じ精度を達成しつつ、計算量は3分の1以下に削減できることがわかりました。
さらに、TokenLearnerを後段(ネットワークの3/4以降)に配置すると、TokenLearnerの適応性により、より高速に実行しながら、TokenLearnerを使用しない場合に比べてさらに高い性能を達成することができます。
TokenLearner の前後でトークン数に大きな差があるため(例:前 196、後 8)、TokenLearner モジュール後のtransformersの相対計算量はほとんど無視できる程度になります。
ViTとの比較
ImageNetで小数ショット後の転移において、TokenLearnerを搭載した標準的なViTモデルと搭載していないモデルを同じ設定で比較しました。TokenLearnerは、各ViTモデルの1/2や3/4など様々な位置に配置されています。下図は、TokenLearnerを搭載したモデルと搭載していないモデルの性能・計算量のトレードオフを示しています。
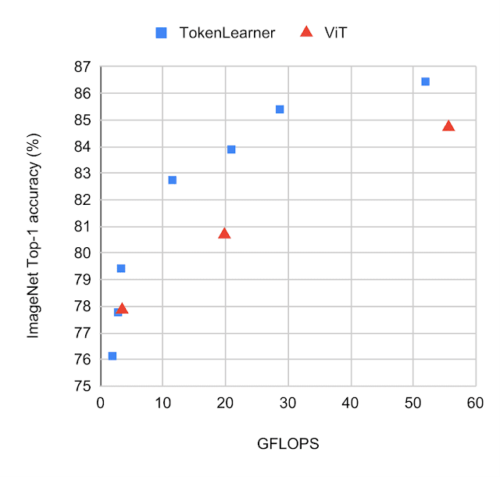
TokenLearnerを使用した場合と使用しない場合のImageNet分類における様々なバージョンのViTモデルの性能
モデルはJFT300Mで事前に学習させています。各グラフの左上に近いモデルほど、高速に動作し、性能が良いことを意味します。TokenLearnerのモデルが、精度と計算の両方でViTより優れていることを観察してください。
また、より大きなViTモデルにもTokenLearnerを挿入し、巨大なViT G/14モデルとの比較も行いました。ここでは、10×10(または8×8)パッチを初期トークンとし、24のattention layersを持つViTのL/10とL/8にTokenLearnerを適用しました。下図は、TokenLearnerが、少ないパラメータと少ない計算量にもかかわらず、48層の巨大なG/14モデルに匹敵する性能を持つことを示しています。
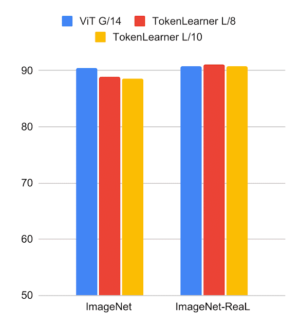
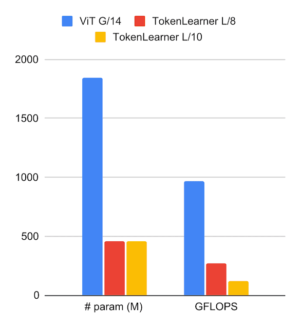
左:ImageNetデータセットにおける大規模TokenLearnerモデルの分類精度とViT G/14の比較
右:パラメータ数とFLOPSの比較
高性能な動画モデル
ビデオの理解はコンピュータビジョンにおける重要な課題の一つであるため、複数の映像分類データセットでTokenLearnerを評価しました。これはTokenLearnerをVideo Vision Transformers(ViViT)に追加することで行われました。ViViTはViTの時空間バージョン(spatio-temporal version)として考えることができます。TokenLearnerはタイムステップごとに8(または16)個のトークンを学習しました。
ViViTと組み合わせた場合、TokenLearnerはKinetics-400、Kinetics-600、Charades、AViDなどの複数の一般的なビデオベンチマークにおいて最先端の性能(SOTA:State-Of-The-Art)を獲得し、Kinetics-400とKinetics-600では従来のTransformerモデルを、CharadesとAViDでは従来のCNNモデルより優れた性能を発揮することが分かりました。
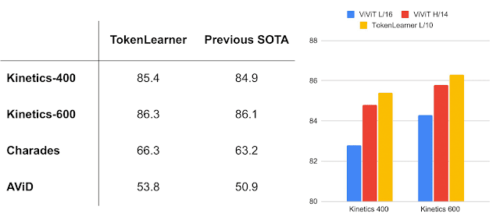
TokenLearnerを搭載したモデルは、一般的なビデオベンチマークで最先端のスコアを上回ります。(2021年11月の記録)
左:一般的なビデオ分類タスク
右:ViViTモデルとの比較
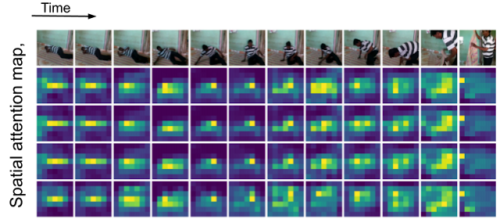
TokenLearnerの空間的なattention mapの時系列な可視化
人がシーン内を移動するため、TokenLearnerは異なる空間位置に注意を払ってトークン化しています。
まとめ
Vision Transformerはコンピュータビジョンの強力なモデルとして機能しますが、トークンの数が多く、それに伴う計算量が大きいことが、より大きな画像や長い動画へ適用する際のボトルネックになっています。
本プロジェクトでは、そのような多数のトークンを保持し、レイヤーのセット全体にわたって完全に処理する必要がないことを説明しました。
更に、入力画像に基づいて適応的にトークンを抽出するモジュールを学習させることで、計算量を削減しつつ、より高い性能を達成できることを示しました。提案したTokenLearnerは、特に動画像表現学習課題において有効であり、複数の公開データセットで確認しています。本研究の査読前論文とコードはarxivとgithubで一般に公開されています。
謝辞
共著者に感謝します。AJ Piergiovanni, Mostafa Dehghani, 及び Anelia Angelovaに感謝します。また、有益な議論に付き合ってくれたRobotics at Googleのチームメンバーに感謝します。
3.TokenLearner:柔軟にトークン化する事でVision Transformerの効率と精度を向上(2/2)まとめ
1)ai.googleblog.com
Improving Vision Transformer Efficiency and Accuracy by Learning to Tokenize
2)arxiv.org
TokenLearner: What Can 8 Learned Tokens Do for Images and Videos?
3)github.com
scenic/scenic/projects/token_learner/

