
1.Implicit BC:ロボットが優柔不断な行動を学習しないようにする(2/2)まとめ
・教師あり学習による行動クローニングはロボットが人間から学習する最も簡単な方法の一つ
・行動クローニングを行う際には暗黙的なポリシーでより複雑で正確な行動を模倣可能になる
・暗黙的な関数が不連続性やマルチモーダルなラベルをモデル化する能力は広く応用可能
2.Implicit BCの性能
以下、ai.googleblog.comより「Decisiveness in Imitation Learning for Robots」の意訳です。元記事は2021年11月19日、Pete FlorenceさんとCorey Lynchさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Dylan Hunter on Unsplas
一度訓練すれば、暗黙的モデル(implicit models)は明示的モデル(explicit models)が苦手とする不連続性を正確にモデル化することに特に優れており、迷わず行動を切り替えることができるポリシーを新たに生み出せます。
しかし、なぜ従来の明示的モデルは苦戦するのでしょうか?
最近のニューラルネットワークは、ほとんどの場合、連続活性化関数(continuous activation functions)を使用しています。
例えば、Tensorflow、Jax、PyTorchはすべて連続活性化関数しか搭載していません。不連続なデータにフィットさせようとすると、これらの活性化関数で構築された明示的ネットワークは不連続性を表現できないため、データポイント間に連続的な曲線を描かなければなりません。
暗黙的モデルの重要な点は、ネットワーク自体は連続層のみで構成されているにもかかわらず、著しい不連続性を表現する能力を獲得している点です。
また、そのための理論的基盤として、普遍近似の概念(notion of universal approximation)を確立しました。これはにより、暗黙的ニューラルネットワークが表現できる関数のクラスが証明され、今後の研究の正当化と指針になります。
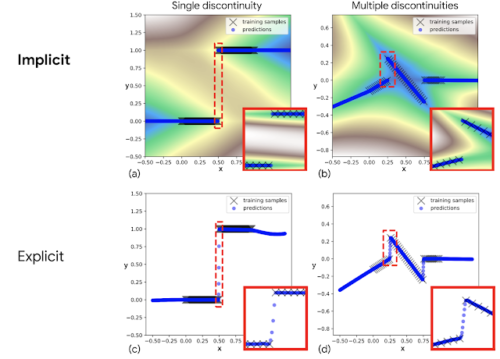
不連続関数のフィッティングの例
暗黙的モデル(上)と明示的モデル(下)の比較
赤色でハイライトされた挿入図は、明示的モデルでは不連続の間に連続線(c)と(d)を引く必要があるのに対し、暗黙的モデルでは不連続(a)と(b)を表現していることを示しています。
この手法の最初の試みは、「行動の高次元化」という課題を抱えていました。これは、ロボットが多くのモーターを同時に協調させる方法を決定しなければならないことを意味します。そこで、自己回帰モデルやランジュバンダイナミクス(Langevin dynamics)を用いることで、高い行動次元に対応できるようにしました。
実験のハイライト
実験では、暗黙的BC(Implicit BC)が実世界で特に優れていることがわかりました。
例えば、1mm精度のslide-then-insertタスクでは、ベースラインの明示的BCモデルと比較して1桁(10倍)優れています。この課題では、暗黙のモデルがブロックを所定の位置にスライドさせる前に、数回連続して精密な調整を行います(下図)。
このタスクでは、決断力の要素が複数求められます。
ブロックが対照的でどこからも押せる事、押す操作は任意の順序でできる事、などのために多くの異なる可能性があり、ロボットはブロックが「十分に」押されたことを不連続に決定してから、別の方向にスライドさせるように切り替える必要があります。これは、連続制御型ロボットにありがちな優柔不断さとは対照的です。

テーブル上でブロックをスライドさせ、スロットに正確に挿入するタスクの例
これらは、暗黙的BCポリシーによる自律的な動作であり、入力は画像(図示のカメラ)のみです。

このタスクを達成するための多様な異なる戦略のセット。
これらは、暗黙のBCポリシーによる、画像のみを入力とする自律的な行動です。
また、別の課題では、ロボットがブロックを色で並べ替える必要があります。並べ替えの順序が任意であるため、多数の解決策が考えられます。このタスクでは、明示的モデルは通常優柔不断になりますが、暗黙的モデルはかなり良いパフォーマンスを示します。
難易度の高い連続多項目並べ替え課題における暗黙的(左)と明示的(右)のBCモデルの比較。(4倍速)
私たちのテストでは、Implicit BCモデルは、人間の手を見たことがないにもかかわらず、私達がロボットに干渉しても、堅牢な反応行動を示すことができます。
ロボットに干渉したにもかかわらず、Implicit BCモデルは堅牢な動作を実現しています。
その結果、いくつかの異なるタスクにおいて、Implicit BCポリシーは、最先端のオフライン強化学習手法と比較して、強力な結果を得ることができました。これらの結果には、デモンストレーションの数が少ない(わずか19)、画像ベースで観測の次元が高い、ロボットに搭載されている動力モーターの数が多くアクションの次元が高く(30次元)、などの難しい課題が含まれています。
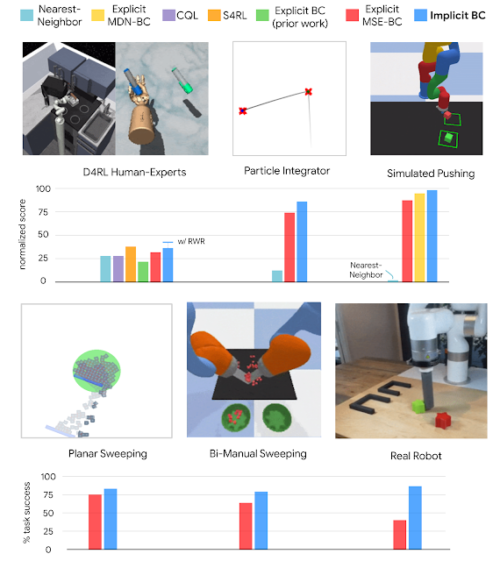
いくつかの分野において、Implicit BCのポリシー学習結果をベースラインと比較
結論
教師あり学習による行動クローニングは、限界はありますが、ロボットが人間の行動例から学習するための最も簡単な方法の一つです。今回示したように、行動クローニングを行う際に、明示的なポリシーを暗黙的なポリシーに置き換えることで、ロボットは「決断力の欠如」を克服し、より複雑で正確な行動を模倣することができます。今回の結果はロボットの学習に焦点を当てたものですが、暗黙的な関数が著しい不連続性やマルチモーダルなラベルをモデル化する能力は、機械学習の他の応用分野でも広く注目される可能性があります。
謝辞
本稿はPeteとCoreyが、他の共著者と一緒に行った研究をまとめたものです。共著者:Andy Zeng, Oscar Ramirez, Ayzaan Wahid, Laura Downs, Adrian Wong, Johnny Lee, Igor Mordatch, そして Jonathan Tompson。
また、プロジェクトの方向性をアドバイスしてくださったVikas Sindwhani、ロボットソフトウェアのインフラを提供してくださったSteve Xu, Robert Baruch, Arnab Bose、MLのインフラを提供してくださったJake Varley, Alexa Greenberg、有益なフィードバックや議論をしてくださったKamyar Ghasemipour, Jon Barron, Eric Jang, Stephen Tu, Sumeet Singh, Jean-Jacques Slotine, Anirudha Majumdar, Vincent Vanhouckeに感謝いたします。
3.Implicit BC:ロボットが優柔不断な行動を学習しないようにする(2/2)関連リンク
1)ai.googleblog.com
Decisiveness in Imitation Learning for Robots
2)arxiv.org
Implicit Behavioral Cloning
3)github.com
google-research / ibc

