1.GCE:Pixel6の文字入力時の文法エラー修正モデル(1/2)まとめ
・スマートフォンを使用してより長い文章を作成することは、依然として非常に面倒
・この問題に対処するためにPixel 6のGboardに直接組み込んだ文法修正機能をリリース
・このモデルは、TransformerエンコーダーとLSTMデコーダーを組み合わせている
2.GCEとは?
以下、ai.googleblog.comより「Grammar Correction as You Type, on Pixel 6」の意訳です。元記事の投稿は2021年10月27日、Tony MakさんとSimon Tongさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by freestocks on Unsplash
スマートフォンの成功と普及にもかかわらず、スマートフォンを使用してより長い文章を作成することは、依然として非常に面倒です。ある人が書いているように、文法エラーはしばしば文章内に忍び寄る可能性があり(これは特に正式な文章では望ましくありません)、これらのエラーの修正は、操作方法が制限されている小さなディスプレイでは時間がかかる可能性があります。
これらの課題のいくつかに対処するために、Pixel 6のGboardに直接組み込んだ文法修正機能をリリースします。この機能は、クラウドに接続せずともデバイス上で完全に機能してプライバシーを保護し、ユーザーが入力している間の文法エラーの修正を検出して提案します。このような機能を構築するには、メモリサイズの制限、応答時間の要件、部分的な文の処理など、いくつかの重要な障害に対処する必要がありました。現在、この機能は英語の文章を修正することができ(近い将来、より多くの言語に拡張する予定です)、Gboardを利用するほぼすべてのアプリ(最終的にGboardを使用するすべてのアプリで利用できるようになりますが、現在WebViewのアプリでは利用できません)で利用できます。
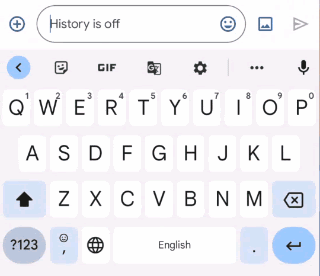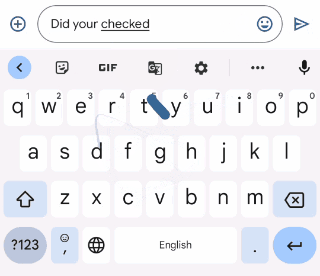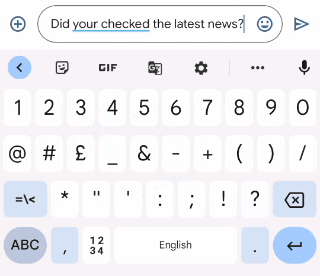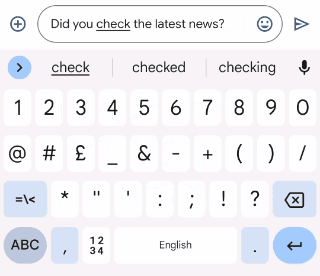
Gboardは、ユーザーが入力するときに文法的におかしい文を修正する方法を提案します。
モデルアーキテクチャ
入力文(または文頭)を取得して文法的に正しいバージョンを出力するようにsequence-to-sequenceニューラルネットワークをトレーニングしました。元のテキストがすでに文法的に正しい場合、モデルの出力はその入力と同じであり、修正が必要ないことを示します。 このモデルは、TransformerエンコーダーとLSTMデコーダーを組み合わせたハイブリッドアーキテクチャを使用しており、品質と応答時間のバランスが取れています。
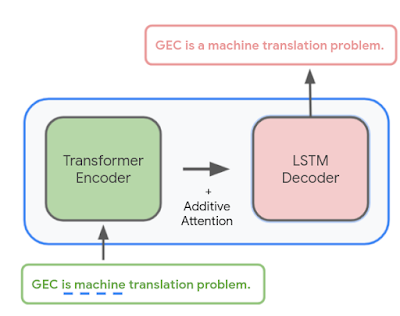
文法エラー訂正(GEC:Grammatical Error Correction)モデルの概要
スマートフォンのようなモバイルデバイスは、限られたメモリと計算能力によって制約され、高品質の文法チェックシステムを構築することをより困難にします。小さく、効率的で、有能なモデルを構築するために使用できるいくつかの手法があります。
・共有埋め込み(Shared embedding)
モデルの入力と出力は構造的に類似しているため(たとえば、両方が同じ言語のテキストであるため)、TransformerエンコーダーとLSTMデコーダーの間でモデルの重みの一部を共有します。これにより、精度に過度の影響を与えることなく、モデルファイルのサイズが大幅に削減されます。
・因数分解された埋め込み(Factorized embedding)
モデルは、文を事前定義されたトークンの並びに分割します。良好な品質を実現するには、事前定義されたトークンに大きな語彙を使用することが重要であることがわかっています。しかしながら、それをするとモデルサイズが大幅に増加します。因数分解された埋め込みは、隠れレイヤーのサイズを語彙の埋め込みのサイズから分離します。これにより、総重み数を大幅に増やすことなく、語彙の多いモデルを作成できます。
・量子化(Quantization)
モデルサイズをさらに縮小するために、トレーニング後に量子化を実行します。これにより、8ビットのみを使用して各32ビット浮動小数点の重みを格納できます。これは、各重みがより低い忠実度で保存されることを意味しますが、それでも、モデルの品質は実質的に影響を受けないことがわかります。
これらの手法を採用することで、結果のモデルはわずか20MBのストレージを使用し、Google Pixel 6のCPUで22ミリ秒未満で60個の入力文字に対して推論を実行できます。
モデルのトレーニング
モデルをトレーニングするには、<元文章, 修正された文章>をペアにしたテキスト形式のトレーニングデータが必要でした。
小さなオンデバイスモデルを生成するための1つの可能なアプローチは、大きなクラウドベースの文法モデルと同じトレーニングデータを使用することです。このデータは適度に高品質のオンデバイスモデルを生成しますが、ハード蒸留(hard distillation)と呼ばれる手法を使用して、オンデバイスでの使用により適したトレーニングデータを生成すると、さらに高品質の結果が得られることがわかりました。
ハード蒸留は次のように機能します。最初に、公開されているインターネット全体から数億の英語の文章を収集しました。次に、大規模なクラウドベースの文法モデルを使用して、これらの文の文法修正を生成しました。
3.GCE:Pixel6の文字入力時の文法エラー修正モデル(1/2)関連リンク
1)ai.googleblog.com
Grammar Correction as You Type, on Pixel 6
