
1.TAG:マルチタスク学習で一緒にトレーニングすべきタスクを知る(1/2)まとめ
・多くの機械学習モデルは、通常、一度に1つのタスクを学習する事に重点を置いている
・多数のタスクから同時に学習すると性能が向上する場合がありこれをマルチタスク学習という
・タスク間の親和性に注目して効率的なマルチタスク学習が実現できないか調査した
2.タスク間の親和性とは?
以下、ai.googleblog.comより「Deciding Which Tasks Should Train Together in Multi-Task Neural Networks」の意訳です。元記事は2021年10月25日、Christopher Fiftyさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by The HK Photo Company on Unsplash
多くの機械学習(ML:Machine Learning)モデルは、通常、一度に1つのタスクを学習する事に重点を置いています。たとえば、言語モデルは過去に出現した単語が与えられた場合に次に来る単語の確率を予測し、物体検出モデルは画像に存在する物体を識別します。
しかしながら、関連する多くのタスクから同時に学習すると、モデリングのパフォーマンスが向上する場合があります。これは、MLの一分野であるマルチタスク学習で研究されています。マルチタスク学習では、単一モデル内で複数の目的を同時にトレーニングします。
実際の例を考えてみましょう。例えば卓球ゲームです。卓球をするときは、ピンポン玉までの距離、回転、弾道を判断して体勢を調整し、スイングすると有利なことがよくあります。
これらのタスクはそれぞれ固有ですが(ピンポン玉の回転を予測するタスクとその位置を予測するタスクは根本的に異なります)、ボールの位置と回転の推論を改善することで、弾道をより正確に予測できるようになります。
例えて言えば、ディープラーニングでは、3つの関連するタスク(ピンポン玉の位置、スピン、軌道など)を予測する単一モデルを学習すると、個々の目的を予測するだけのモデルよりも性能が向上することがあります。
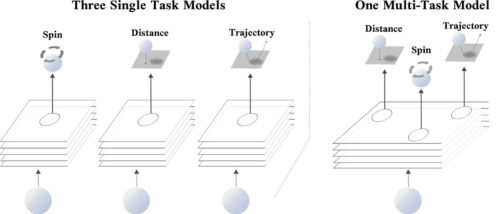
左:3つのシングルタスクネットワーク。それぞれが同じ入力を使用して、ピンポンボールのスピン、距離、または弾道をそれぞれ予測します。 右:スピン、距離、弾道を同時に予測する単一のマルチタスクネットワーク。
NeurIPS 2021でのスポットライトプレゼンテーションである「Efficiently Identifying Task Groupings in Multi-Task Learning」では、マルチタスクニューラルネットワークでどのタスクを一緒にトレーニングするかを決定するタスクアフィニティグループ(TAG:Task Affinity Groupings)と呼ばれる方法について説明します。
私たちのアプローチは、すべてのタスクのパフォーマンスが最大化されるように、タスクのセットをより小さなサブセットに分割しようとします。この目標を達成するために、すべてのタスクを1つのマルチタスクモデルで一緒にトレーニングし、モデルのパラメーターに対する1つのタスクの勾配の更新がネットワーク内の他のタスクの損失にどの程度影響するかを測定します。この量を「タスク間の親和性(inter-task affinity)」と呼びます。 私たちの実験結果は、タスク間の親和性を最大化するタスクのグループを選択することが、全体的なモデルのパフォーマンスと強く相関することを示しています。
どのタスクを一緒にトレーニングする必要がありますか?
理想的なケースでは、マルチタスク学習モデルは、1つのタスクから学習した情報を他のタスクに適用して損失を減らします。この情報の転移により、複数の予測を行うことができるだけでなく、タスクごとに異なるモデルをトレーニングした際のパフォーマンスと比較して、予測精度が向上する可能性がある単一のモデルが得られます。
その一方、多くのタスクで単一のモデルをトレーニングすると、モデル容量をめぐる獲得競争が発生し、パフォーマンスが大幅に低下する可能性があります。
この後者のシナリオは、タスクが無関係な場合によく発生します。ピンポンの例えに戻ると、フィボナッチ数列について解説しながら、ピンポン球の位置、回転、および軌道を予測しようとしていることを想像してみてください。この結果は楽しい見通しではなく、ピンポンプレーヤーとしての進歩に悪影響を与える可能性があります。
モデルの学習対象となるタスクを選択するための直接的なアプローチの1つは、可能な組み合わせをすべて網羅的に探索することです。しかし、可能な組み合わせの数はタスクの数に対して指数関数的に増加するため、特にタスクの数が多い場合には、この検索に伴うコストは膨大なものになります。
これは、モデルが適用されるタスクの集合が、その生涯を通じて変化する可能性があるという事実によって、さらに複雑になります。
すべてのタスクの集合にタスクが追加されたり削除されたりすると、このコストのかかる分析を繰り返して新しいグループ化を決定する必要があります。さらに、モデルの規模や複雑さが増すにつれ、可能なマルチタスクネットワークのサブセットのみを評価する近似的なタスクグルーピングアルゴリズムであっても、評価に莫大なコストと時間がかかるようになる可能性があります。
3.TAG:マルチタスク学習で一緒にトレーニングすべきタスクを知る(1/2)関連リンク
1)ai.googleblog.com
Deciding Which Tasks Should Train Together in Multi-Task Neural Networks
2)arxiv.org
Efficiently Identifying Task Groupings for Multi-Task Learning

